
为了证明M4 Max真的不行,自己写了案例测试了几个模型
-
@tomcatzh 你的测试非常详实,感谢分享这份一手数据。关于M4 Max做Agent为什么会这么慢,有两点想补充:
-
Prefill瓶颈在算力,不在显存带宽
70K上下文做prefill时,需要同时计算所有token的KV cache和attention score,这完全是GPU算力(TOPs)密集操作。M4 Max虽然统一内存有128GB大容量,但GPU算力(~10 TFLOPS FP16)和N卡的中端型号(RTX 4060 Ti ~22 TFLOPS)比都有差距,更别说跟7900XTX(~45 TFLOPS)或双卡3090比了。所以十几分钟的prefill是硬件天花板决定的,不是优化能解决的。 -
Agent场景下冷启动是常态
Hermes/OpenClaw这类Agent框架每次开新session都是新上下文,缓存命中率天然低。如果工作流涉及多工具调用(网页搜索、代码执行),每步都可能刷新上下文。所以M4 Max的热启动缓存优势在Agent场景下发挥不出来。
建议:
- 如果想在本地跑Agent,最经济的选择是二手3090 24G(~5000元),单卡就能跑Qwen3.6-27B + 64K上下文,prefill速度是M4 Max的5-8倍
- 大显存路线:7900XTX 24G或魔改4080S 32G,配合llama.cpp的flash attention,70K context prefill能控制在30-60秒
- M4 Max其实更适合:fine-tuning(MLX生态很好)、小模型(7B以下)大批量推理、或者跑Apple专属优化的模型(如Apple FFN)
那个benchmark suite做得很专业,已star。
-
-
這就是看你選擇快還是選擇大了, 畢竟是走unified memory架構, 不過蘋果估計算好了, 畢竟蘋果的生態圈也不算細, 反觀AMD的話講好聽點就是開源, 難聽點就是讓想用的人全部通通用愛發電, 老黃好歹也請了一堆開發人員來養生態
還是那句吧: 大的快不了, 快的大不了, 想要又快又大, 麻煩掏錢

-
但是呢,有一点稍稍安慰的是,在这个过程中,找到了一个宝藏模型,Libraxis 35B-A3B VMLX MXFP4 (oMLX)
他的hugging face原帖可以看这里:
https://huggingface.co/LibraxisAI/Huihui-Qwen3.6-35B-A3B-Claude-4.7-Opus-abliterated-vmlx-mxfp4首先这个模型已经abliterated,你懂的,前两天老特的视频也说了,本地模型不拒绝也是创作过程中一个重要的需求。
其次呢,他是一个35B-A3B的模型,本来他的智能应该是比较弱的,但是运行速度是比较好的(尤其在我的m4 max上)
大家可以看我上贴第一张图,大部分的35B-A3B都在下面。但是呢,这个模型的发布机构使用opus 4.7给他整流校准过,效果极好,至少在我的测试集里,完全达到了27B的性能。当然仅对我的测试集负责,偏向tool call和编程,可能也是因为蒸馏的opus 4.7也是偏向这些方向的。
看看图中的智能表现,接近27B的水平:
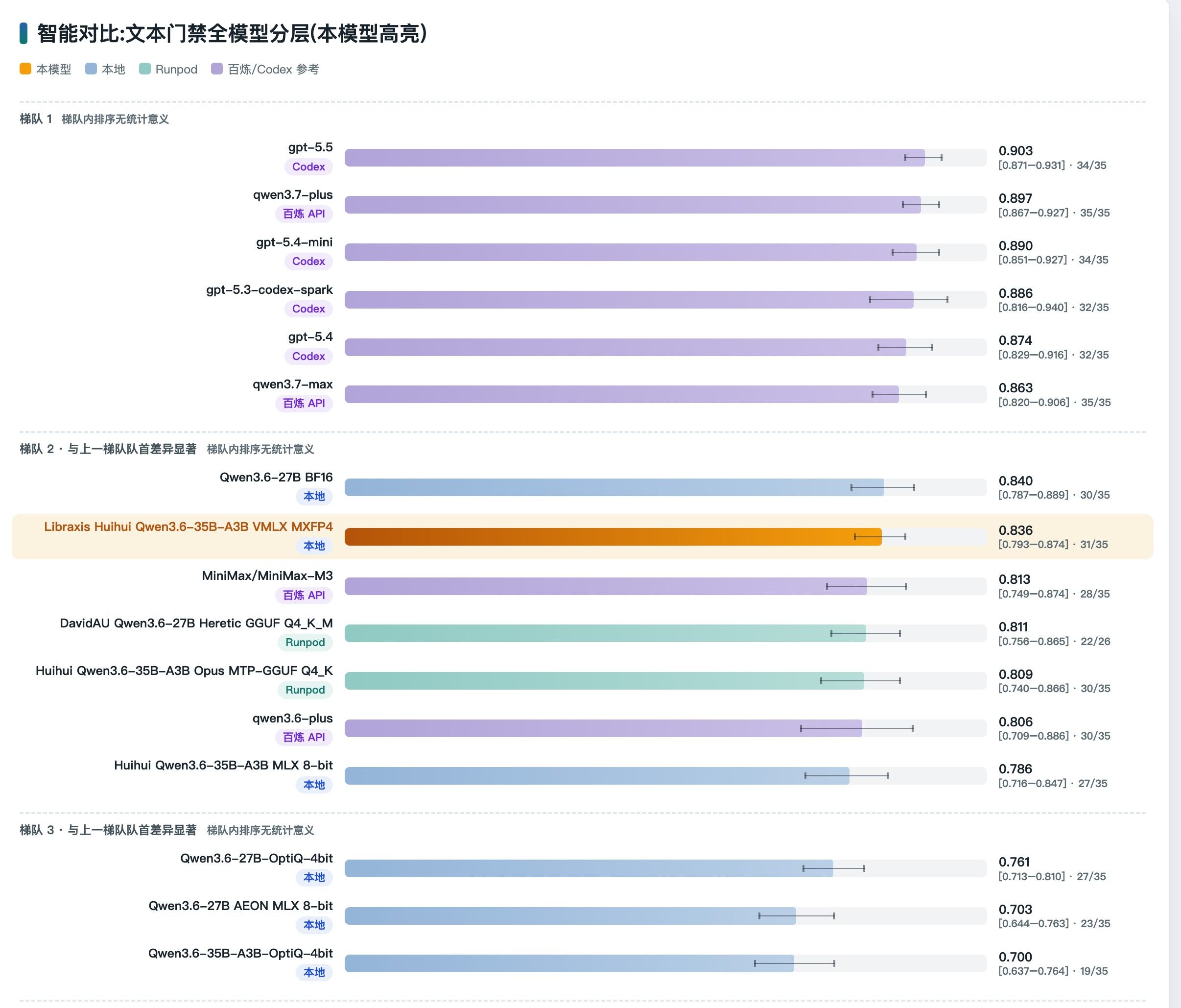
但他的性能,在我的机器上总算能用了
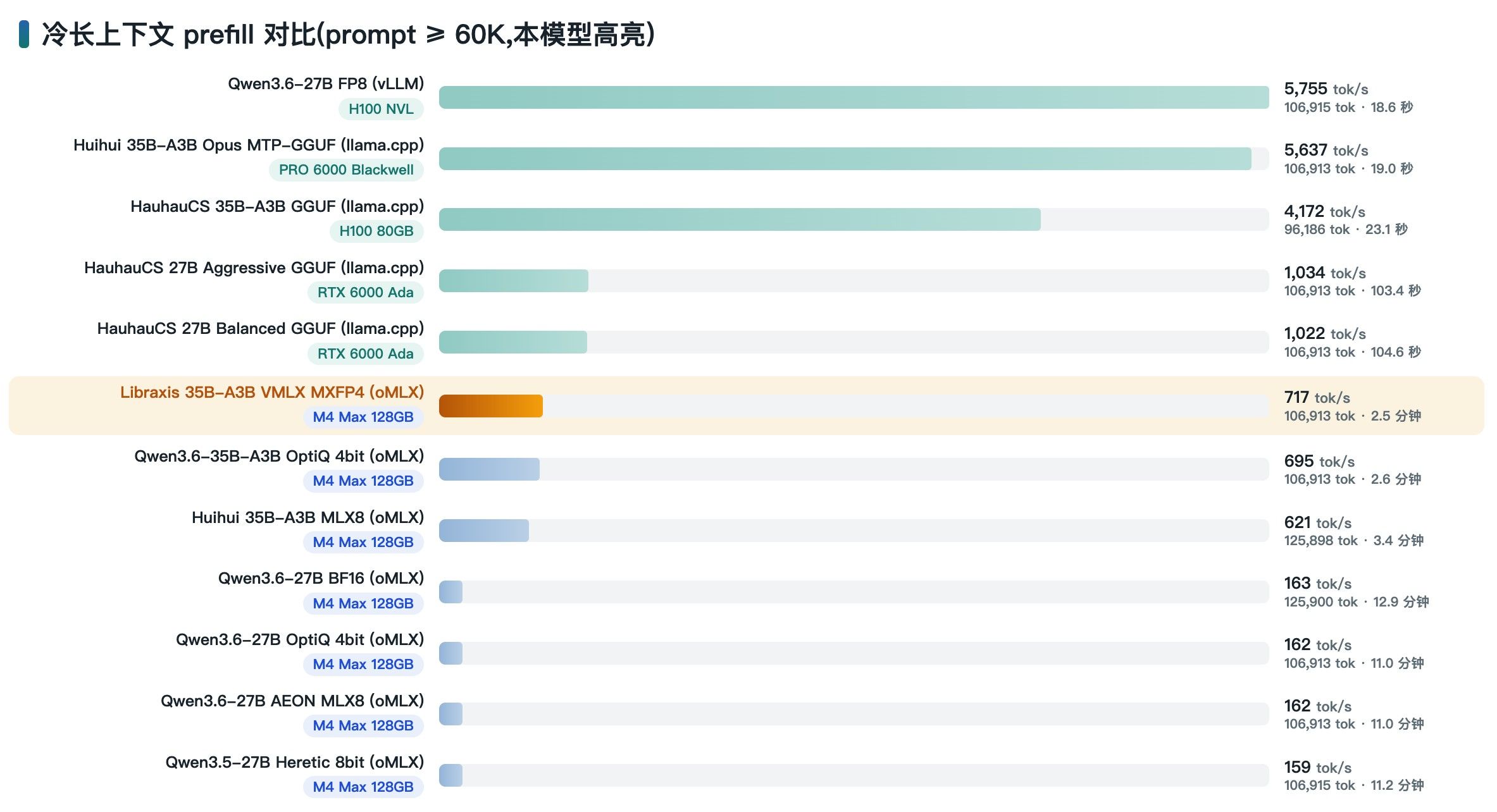
结合老特的教程,只要harness环境够好,区分好上下文记忆,这样tool call准确的模型是可以干活的。
我现在在我的机器上配给了一个小的hermes,专门处理一些prompts润色啊等内容,他也能比较智能的自己总结经验,生成skill,目前感觉良好。关键是,终于找到一个我的机器能跑,智力还算正常的模型了。
推荐各位兄弟使用,尤其是小硬件的,可以试试看。有啥坑也欢迎过来踩我。
-
@tomcatzh 你的测试非常详实,感谢分享这份一手数据。关于M4 Max做Agent为什么会这么慢,有两点想补充:
-
Prefill瓶颈在算力,不在显存带宽
70K上下文做prefill时,需要同时计算所有token的KV cache和attention score,这完全是GPU算力(TOPs)密集操作。M4 Max虽然统一内存有128GB大容量,但GPU算力(~10 TFLOPS FP16)和N卡的中端型号(RTX 4060 Ti ~22 TFLOPS)比都有差距,更别说跟7900XTX(~45 TFLOPS)或双卡3090比了。所以十几分钟的prefill是硬件天花板决定的,不是优化能解决的。 -
Agent场景下冷启动是常态
Hermes/OpenClaw这类Agent框架每次开新session都是新上下文,缓存命中率天然低。如果工作流涉及多工具调用(网页搜索、代码执行),每步都可能刷新上下文。所以M4 Max的热启动缓存优势在Agent场景下发挥不出来。
建议:
- 如果想在本地跑Agent,最经济的选择是二手3090 24G(~5000元),单卡就能跑Qwen3.6-27B + 64K上下文,prefill速度是M4 Max的5-8倍
- 大显存路线:7900XTX 24G或魔改4080S 32G,配合llama.cpp的flash attention,70K context prefill能控制在30-60秒
- M4 Max其实更适合:fine-tuning(MLX生态很好)、小模型(7B以下)大批量推理、或者跑Apple专属优化的模型(如Apple FFN)
那个benchmark suite做得很专业,已star。
-
-
@566656661 徽章要显示,这是论坛用户的评价锁定的,不要不带啊,那声望系统就没意义了

-
M4 群众:盖版 32G 改版 24G 丐版 16G 围观下。大家偷乐,你也不比我们强多少哈。哈哈哈哈哈哈。
-
我局域网让 7900XTX 做本地算力了。
-
嗯。但是暂时 闲置折腾状态。没什么项目给它做。我还是主力用 在线 api 跑。
-
但是呢,有一点稍稍安慰的是,在这个过程中,找到了一个宝藏模型,Libraxis 35B-A3B VMLX MXFP4 (oMLX)
他的hugging face原帖可以看这里:
https://huggingface.co/LibraxisAI/Huihui-Qwen3.6-35B-A3B-Claude-4.7-Opus-abliterated-vmlx-mxfp4首先这个模型已经abliterated,你懂的,前两天老特的视频也说了,本地模型不拒绝也是创作过程中一个重要的需求。
其次呢,他是一个35B-A3B的模型,本来他的智能应该是比较弱的,但是运行速度是比较好的(尤其在我的m4 max上)
大家可以看我上贴第一张图,大部分的35B-A3B都在下面。但是呢,这个模型的发布机构使用opus 4.7给他整流校准过,效果极好,至少在我的测试集里,完全达到了27B的性能。当然仅对我的测试集负责,偏向tool call和编程,可能也是因为蒸馏的opus 4.7也是偏向这些方向的。
看看图中的智能表现,接近27B的水平:
但他的性能,在我的机器上总算能用了
结合老特的教程,只要harness环境够好,区分好上下文记忆,这样tool call准确的模型是可以干活的。
我现在在我的机器上配给了一个小的hermes,专门处理一些prompts润色啊等内容,他也能比较智能的自己总结经验,生成skill,目前感觉良好。关键是,终于找到一个我的机器能跑,智力还算正常的模型了。
推荐各位兄弟使用,尤其是小硬件的,可以试试看。有啥坑也欢迎过来踩我。
-
對了, 個人推薦是盡量避免Claude/GPT/Gemini的蒸餾模型, 因為成效很迷
不是說蒸餾這個技術沒用, 是在指家用端的模型思考能力有限發揮不出來優勢
而且更有可能會矯枉過正導致原本的模型CoT爆掉, 思考能力反而更差
我其實更傾向相信在訓練途中Qwen團隊早已經加入有關這些模型的CoT訓練資料, Gemma 4反而可能沒有對了, 個人推薦是盡量避免Claude/GPT/Gemini的蒸餾模型, 因為成效很迷
不是說蒸餾這個技術沒用, 是在指家用端的模型思考能力有限發揮不出來優勢
而且更有可能會矯枉過正導致原本的模型CoT爆掉, 思考能力反而更差
我其實更傾向相信在訓練途中Qwen團隊早已經加入有關這些模型的CoT訓練資料, Gemma 4反而可能沒有是的,的确,大部分的蒸馏模型都一般。
我也是将信将疑的用。但是hugging face很多发布都喜欢越狱同时加蒸馏。
当时也是看着热度比较高的这个mxfp4模型,本来纯打算测一把速度的。但没想到智能让我有惊喜。(至少在我的测试集里面有惊喜)
-
對了, 個人推薦是盡量避免Claude/GPT/Gemini的蒸餾模型, 因為成效很迷
不是說蒸餾這個技術沒用, 是在指家用端的模型思考能力有限發揮不出來優勢
而且更有可能會矯枉過正導致原本的模型CoT爆掉, 思考能力反而更差
我其實更傾向相信在訓練途中Qwen團隊早已經加入有關這些模型的CoT訓練資料, Gemma 4反而可能沒有是的,的确,大部分的蒸馏模型都一般。
我也是将信将疑的用。但是hugging face很多发布都喜欢越狱同时加蒸馏。
当时也是看着热度比较高的这个mxfp4模型,本来纯打算测一把速度的。但没想到智能让我有惊喜。(至少在我的测试集里面有惊喜)
-
你这个27b decode的速度惊人啊, 可惜就是prefill 太慢.
目前的Mac 跑 35A3 或者 26A4, 应该是最好的选择了. 27b普遍都跑不动.
M5 max 的实测数据, 我们论坛还没有, 我感觉 M5 max 可能将将可用.
-
你这个27b decode的速度惊人啊, 可惜就是prefill 太慢.
目前的Mac 跑 35A3 或者 26A4, 应该是最好的选择了. 27b普遍都跑不动.
M5 max 的实测数据, 我们论坛还没有, 我感觉 M5 max 可能将将可用.
@Tony-Wang decode速度高,毕竟是满血的m4 max
-
@Tony-Wang 我还有一个想测的,是DGX Spark,好像可以闲鱼租
-
剛跑了qwen 3.6 27B Q8 單台DGX spark的測試供參考, 手邊沒有Q4的模型可以跑.

圖片影片的話.. 論壇上有發一篇了, 可以看看
-
 T terry 固定了该主题
T terry 固定了该主题
