全站首发:RTX 3090 24G 无痛爽玩 华为最新开源KV cache格式 (每日更新总结,希望3090卡友进来讨论)
-
上面所用的参数.
killall llama3-server 2>/dev/null; sleep 3 killall llama-server 2>/dev/null; sleep 3 export LD_LIBRARY_PATH=/data/model3/beellma616-kv.cpp/build/bin:$LD_LIBRARY_PATH /data/model3/beellma616-kv.cpp/build/bin/llama-server \ --host 0.0.0.0 --port 8025 \ -m /data/model2/Qwen3.6-27B-MTP-MoQ-4.85.gguf \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ -ngl all \ --ctx-size 163840 \ -b 2048 -ub 512 \ -np 1 \ --kv-unified \ --cache-type-k kvarn4 \ --cache-type-v kvarn4 \ --flash-attn on \ --cache-ram 0 \ --no-host \ --jinja \ --reasoning off \ --temp 0.6 --top-k 20 --top-p 0.96 --min-p 0.01完美契合 Qwen3.6 的混合架构
Qwen3.6 系列本身采用了混合注意力机制。llama.cpp 近期通过 --swa-full 等参数,完美适配了这种架构
。社区测试表明,在重新评估 Qwen3.6-27B 时,开启 SWA 相关参数能完美解决长上下文下的显存泄漏和失效问题
补充一下,看增加这个参数有没有好效果,这个参数在beellama上无效,可能是千问自己幻想的.抱歉了. -
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
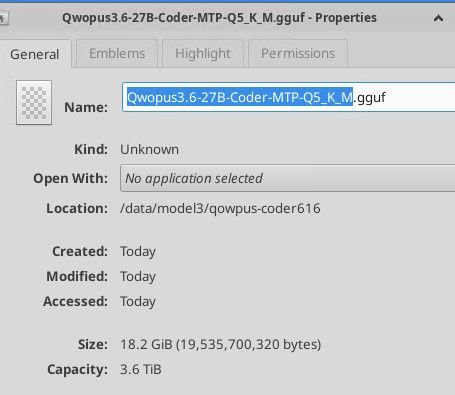 权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
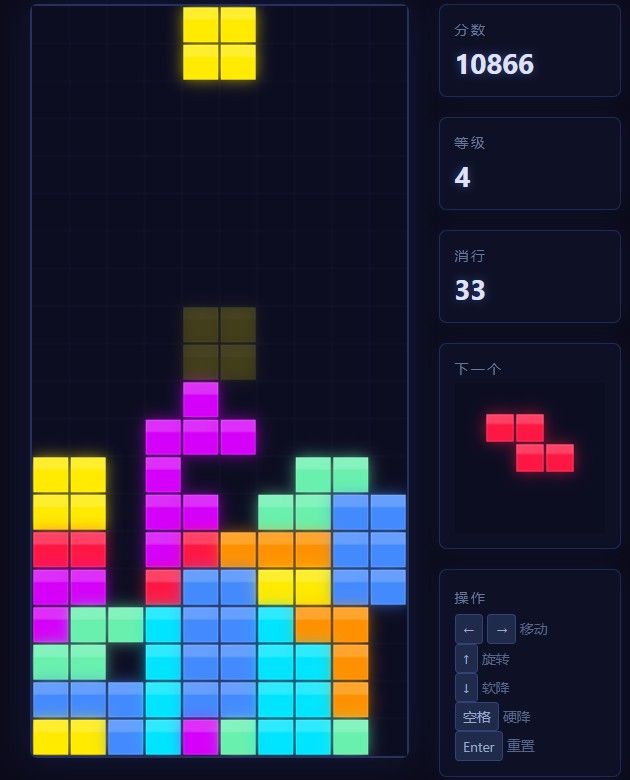
写完之后显存占用没变,显存管理挺优秀.

下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
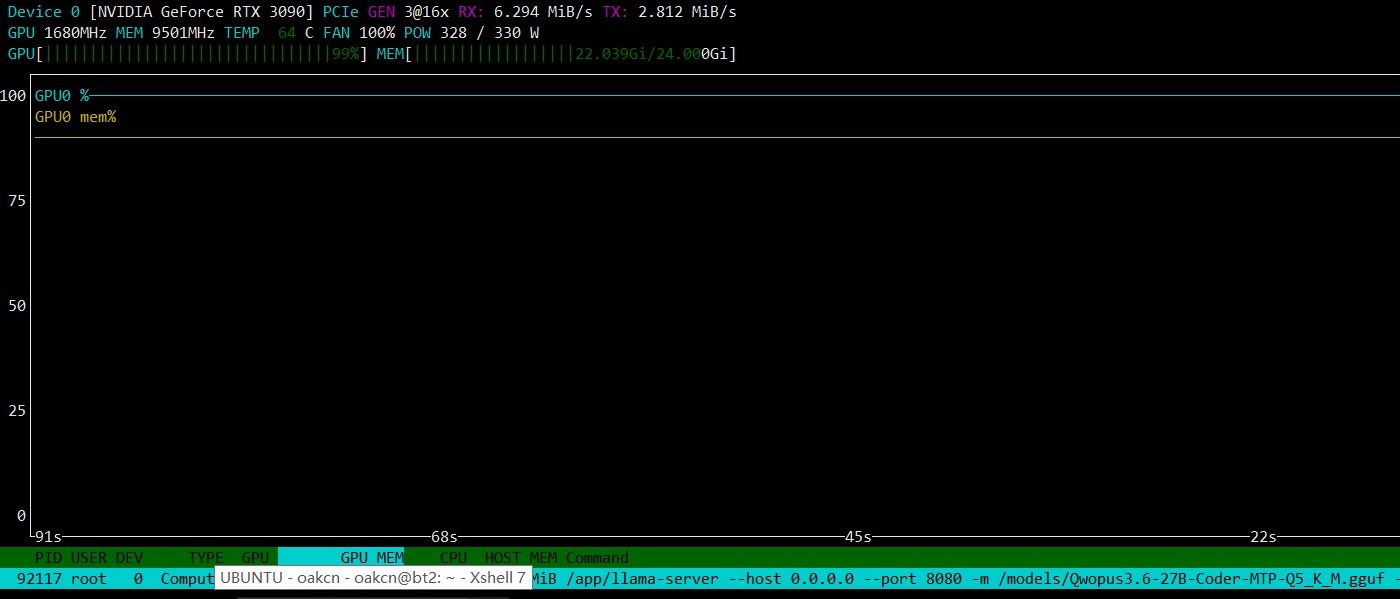
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
写完之后显存占用没变,显存管理挺优秀.
下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
@stxpnet 我的显卡长期70+啊
-
@applejuice 温度?
-
可以多在reddit上搜索看一下,我昨晚看了,也有人在研究这个格式的kv cache了,对咱们这批老用户是个好消息.
我目前的体感是64K或者128K比较适合咱们这个卡. 开0.7的温度,和hermes聊天. 0.6的温度编程. 下面是各种kv cache 的分歧度. 及显存占用 ,二者都是越小越好. 但我还想到一层:
就是如果你的模型权重本身 是Q4的话,产生Q5或Q6级别的cache,可能会拖慢速度,因为它在原始权重中找不到对应的参数.要在KV CACHE里面找,可能拖慢速度. 所以有空可以试试Q5级别的权重.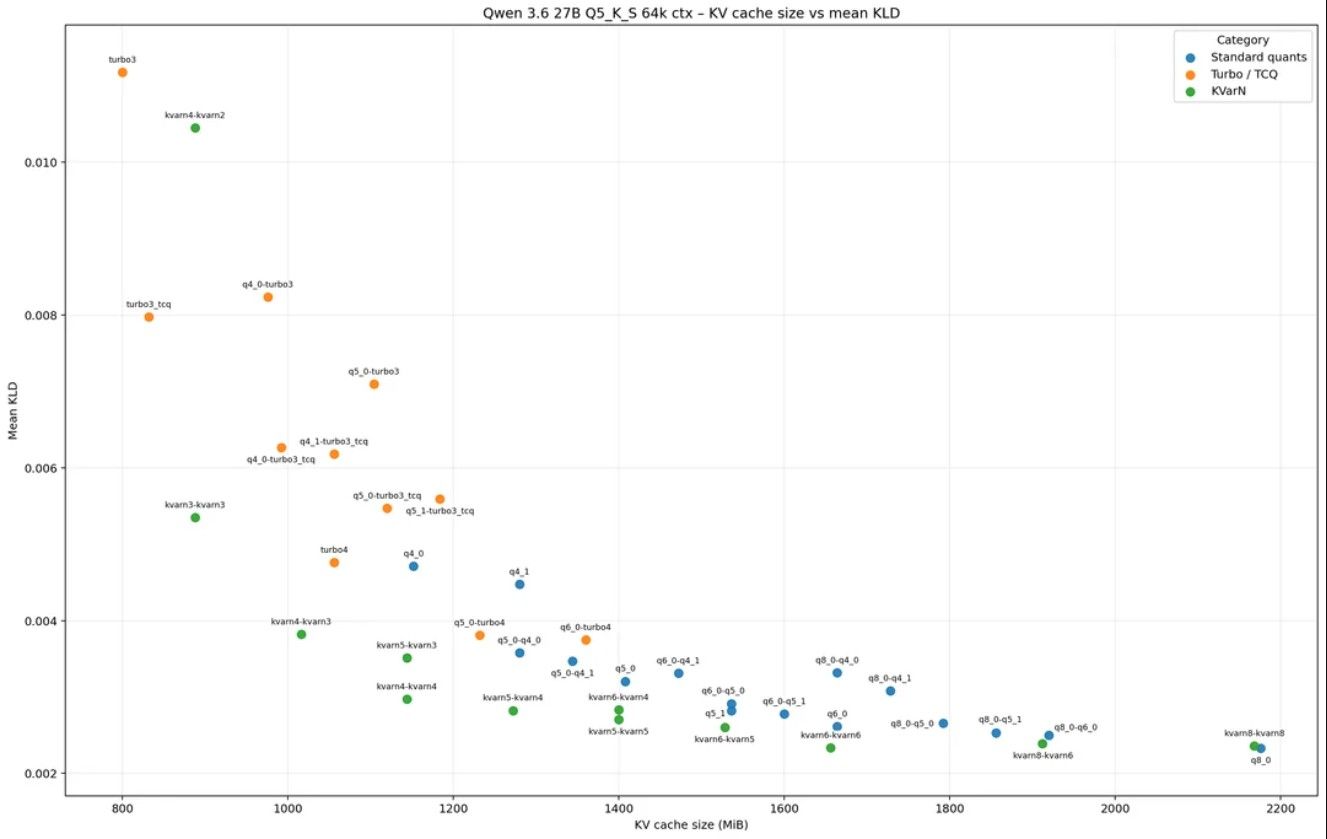
-
可以多在reddit上搜索看一下,我昨晚看了,也有人在研究这个格式的kv cache了,对咱们这批老用户是个好消息.
我目前的体感是64K或者128K比较适合咱们这个卡. 开0.7的温度,和hermes聊天. 0.6的温度编程. 下面是各种kv cache 的分歧度. 及显存占用 ,二者都是越小越好. 但我还想到一层:
就是如果你的模型权重本身 是Q4的话,产生Q5或Q6级别的cache,可能会拖慢速度,因为它在原始权重中找不到对应的参数.要在KV CACHE里面找,可能拖慢速度. 所以有空可以试试Q5级别的权重. -
,系统 取消固定了此主题
-
,5 566656661 引用了 此主题
-
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
写完之后显存占用没变,显存管理挺优秀.
下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
@stxpnet 平时我只要跑起来就 90度啊。。。