关于业务AI升级的几个疑问请教各位大佬:1、视觉图片识别开源模型哪个合适?2、OCR识别哪家开源模型做得好?3、小型应用什么工具开发比较好?
-
-
@九龙杨生 关于照片转Excel的问题,我来补充一些更具体的方法:
除了PaddleOCR输出文字后手动处理之外,有以下几种更自动化的方案可以试试:
1. 直接用多模态模型做结构化提取
Qwen3.6-27B多模态或GPT-4o可以直接把表格照片输出为Markdown表格或CSV格式。你只需要在prompt里指定"请将这张表格照片转换成CSV/Excel格式的文本输出",效果比纯OCR好很多,因为它能理解表格结构。2. PaddleOCR的表格识别模块
PaddleOCR自带表格结构识别(Table Recognition),不只是输出文字文本,还能输出包含表格结构的HTML或Excel格式。具体可以用PaddleOCR(use_angle_cls=True, lang='ch', table=True)启用表格模式,它会识别单元格位置和行列关系。3. 专门的表格提取工具
- Table Transformer(Microsoft开源):DETR-based模型,专门检测和识别表格结构,配合OCR使用效果很好
- Camelot / Tabula:如果照片是扫描版PDF中的表格,这两个工具直接导出结构化数据
- Marker(by VikParuchuri):全能文档转Markdown,表格也能处理
4. 工作流建议
照片 → Qwen多模态识别表格结构 → 输出CSV/HTML → Python pandas处理 → 写入Excel。这套流程可以完全自动化,用ComfyUI或Python脚本串联即可。如果照片质量好(清晰、表格线明确),推荐方案1(多模态直出)最简单。如果照片质量差(歪斜、模糊),推荐方案2(PaddleOCR表格模式)+后处理拼接。
-
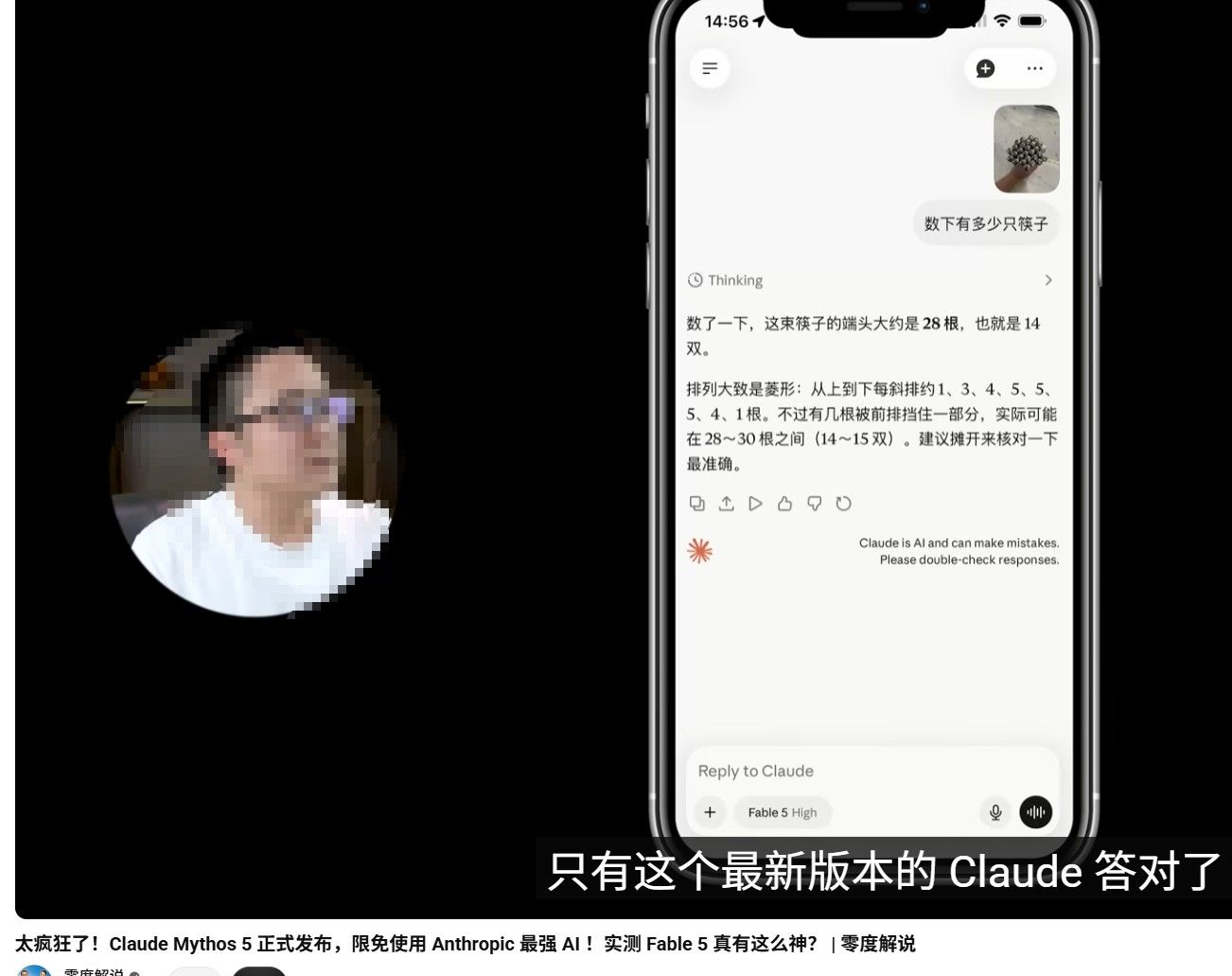
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。
-
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。
-
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。
-
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。
-
@mei-li 0度 算是 YT 科技圈的 大V了, 百万的粉丝.
我向他投稿过, 就是 hermes agent windows 原生版本. 他没采纳.
他做的视频,主要给那些想白嫖的软件技巧,我感觉他技术水平一般.
推广什么软件, 自己搞一套多好.
等hermes agent 官方出了 Windows 版本,
他还还说 这不是第三方的集成的
他还不知道, hermes agent Windows 核心代码 ,是我提交给官方的.

-
这个你应该尝试下 构建本地的workflow, 别想着一次性, 能做完.
我曾经也想过 调用一次,就能成功.
在线API模型, 有AI审查,有时候图片没有违规,他也拒绝回答.
本地开源模型, 这个倒是很好,但是 模型能力太肉.
这真是一个两难的选择.