
高乐天
@高乐天
-
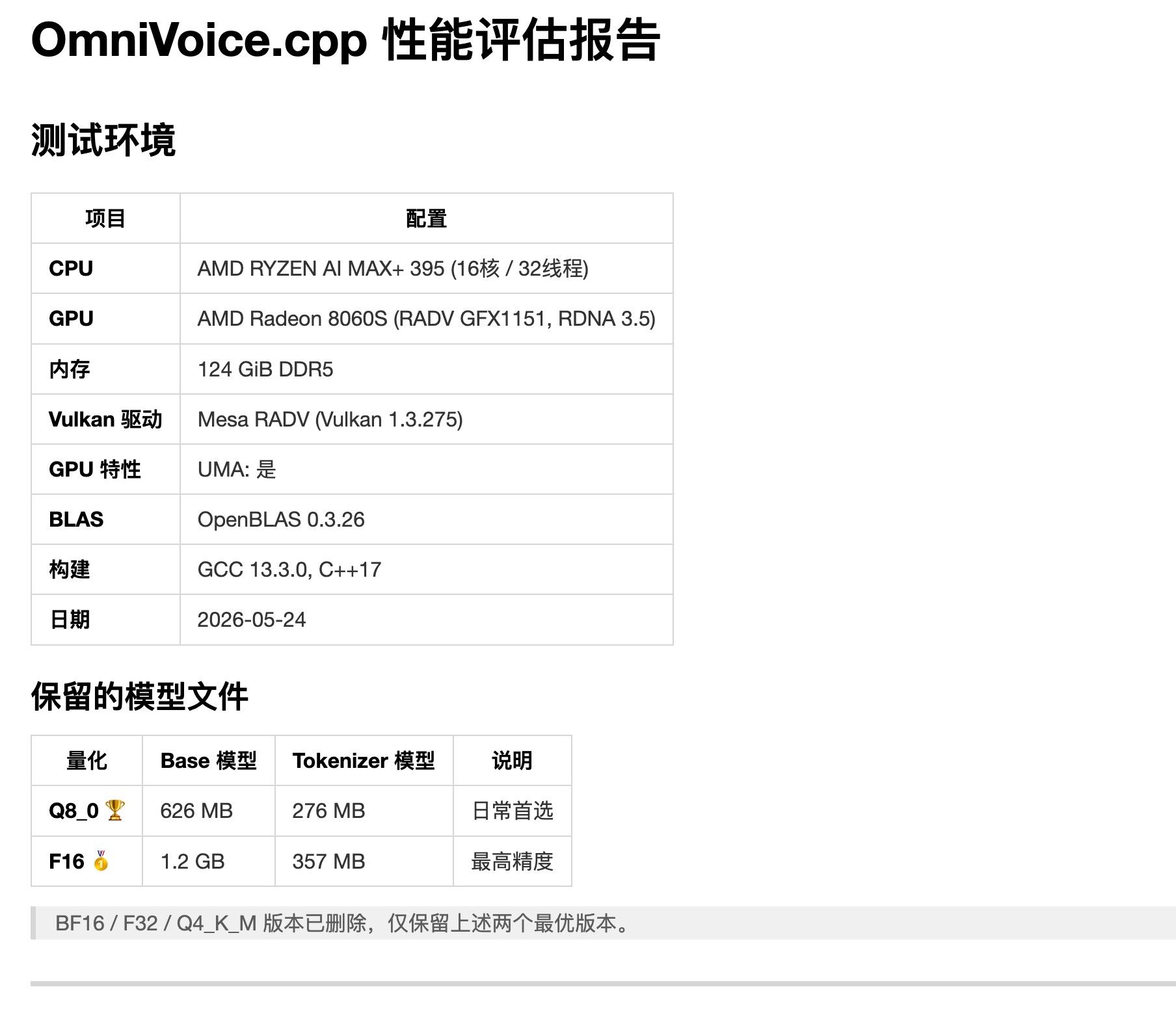
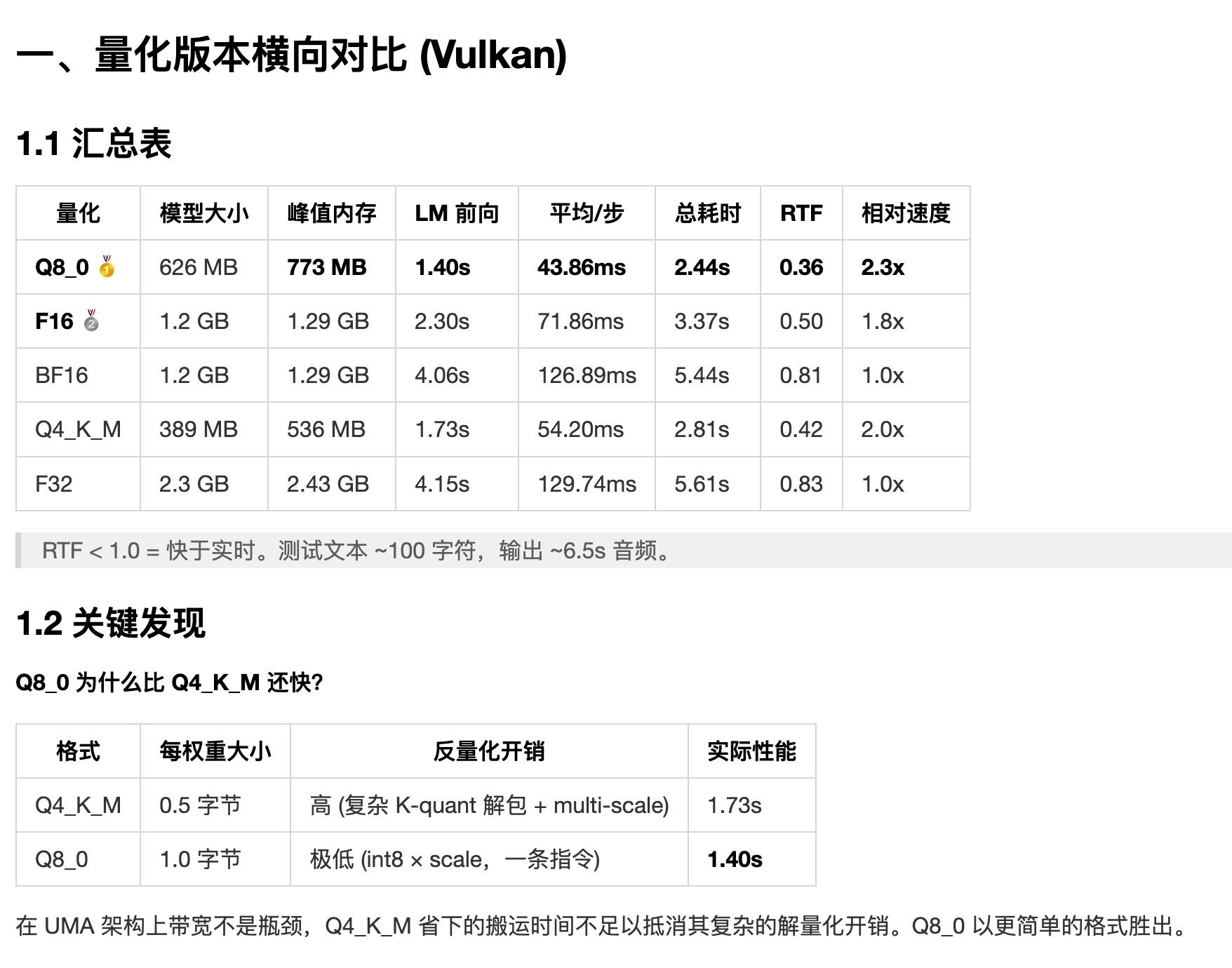
OmniVoice.cpp 性能评估报告 -
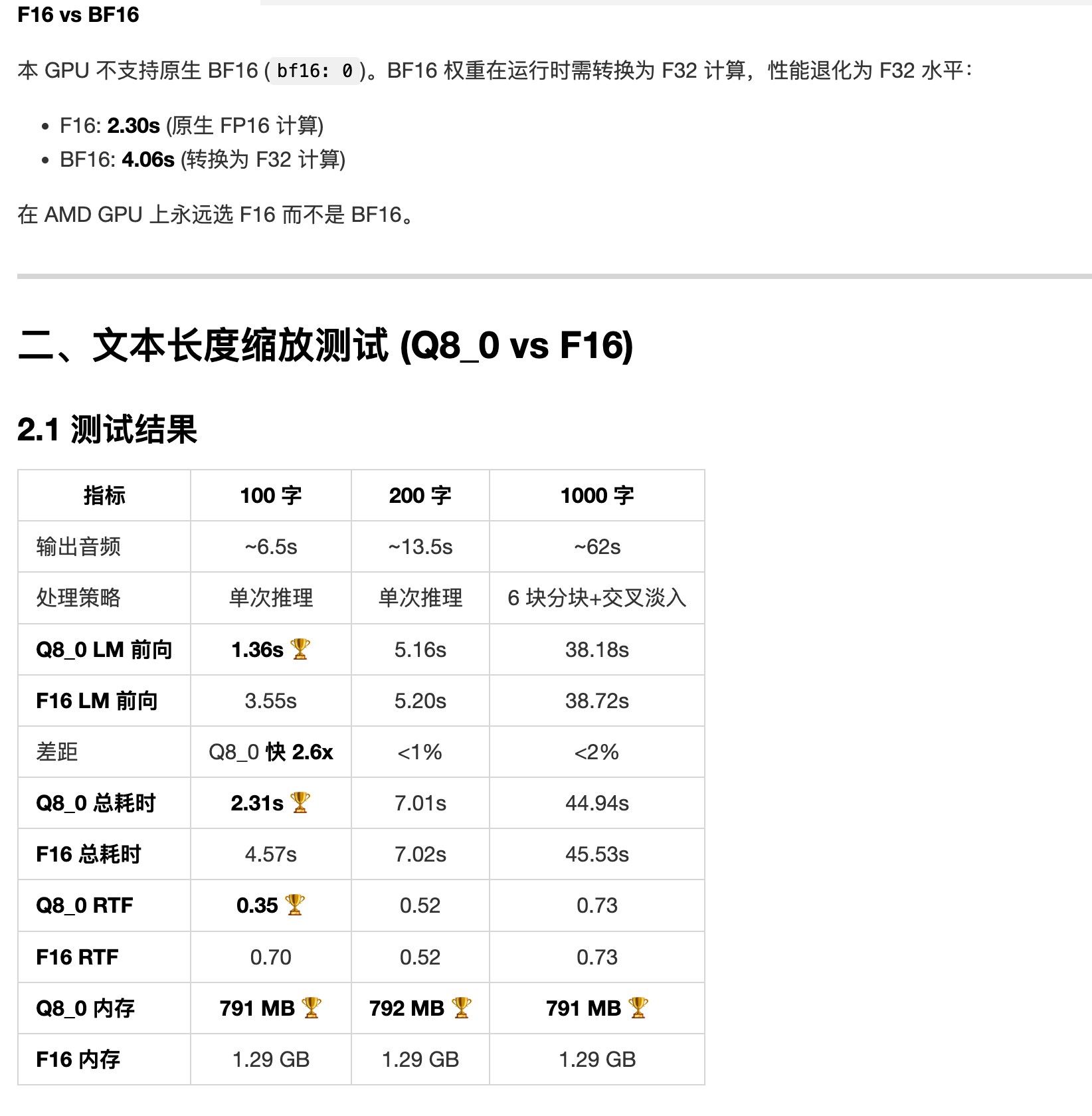
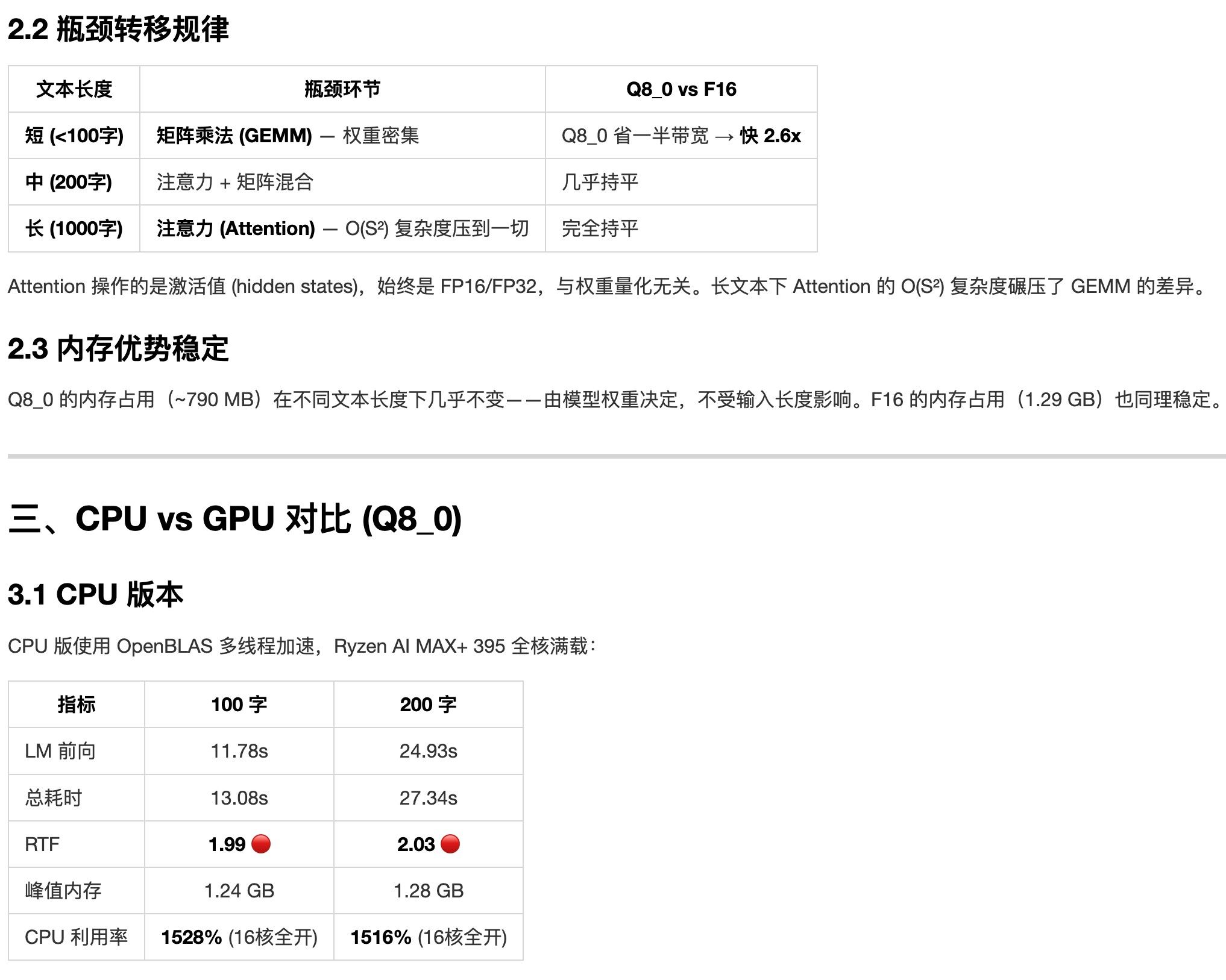
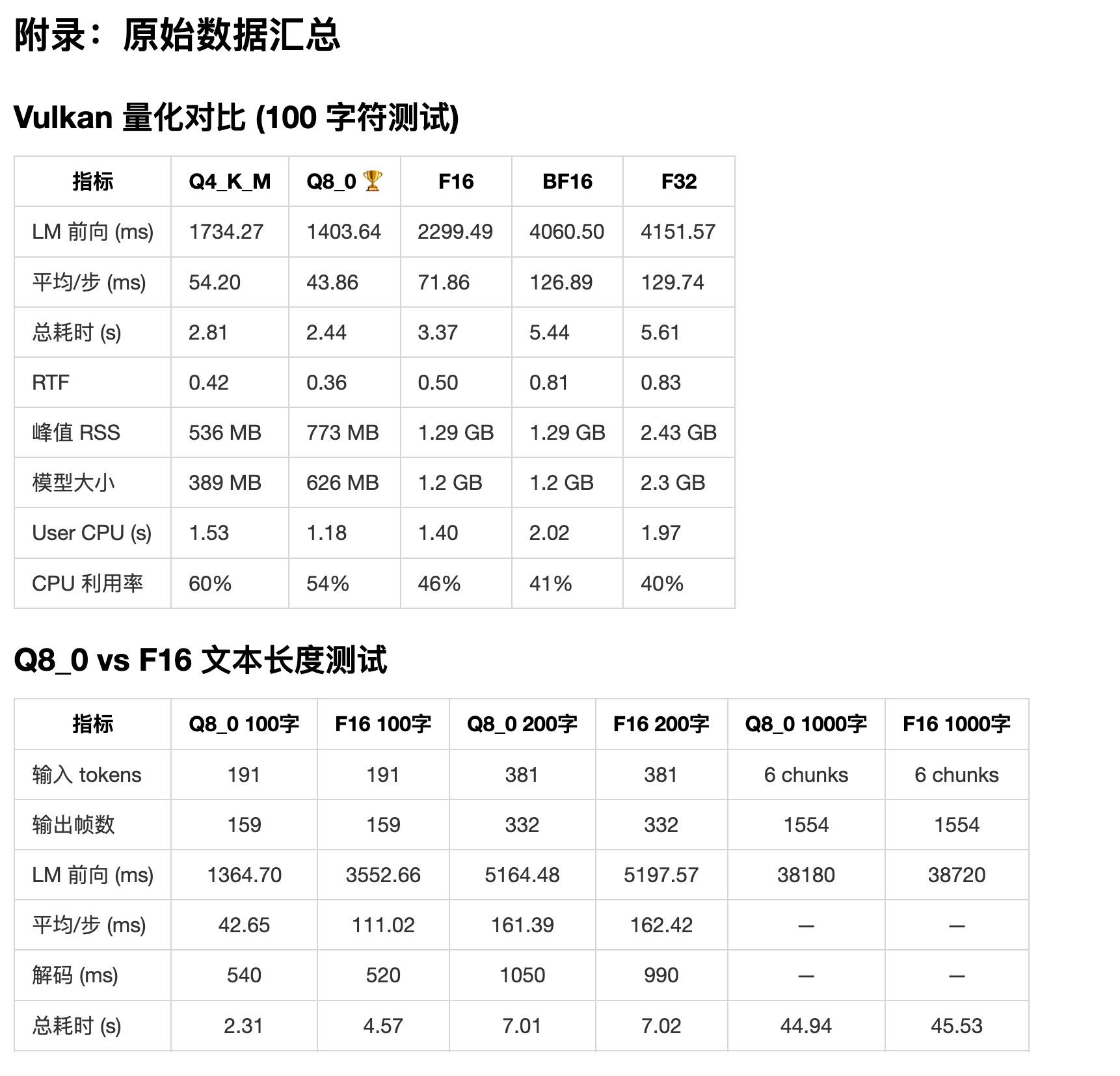
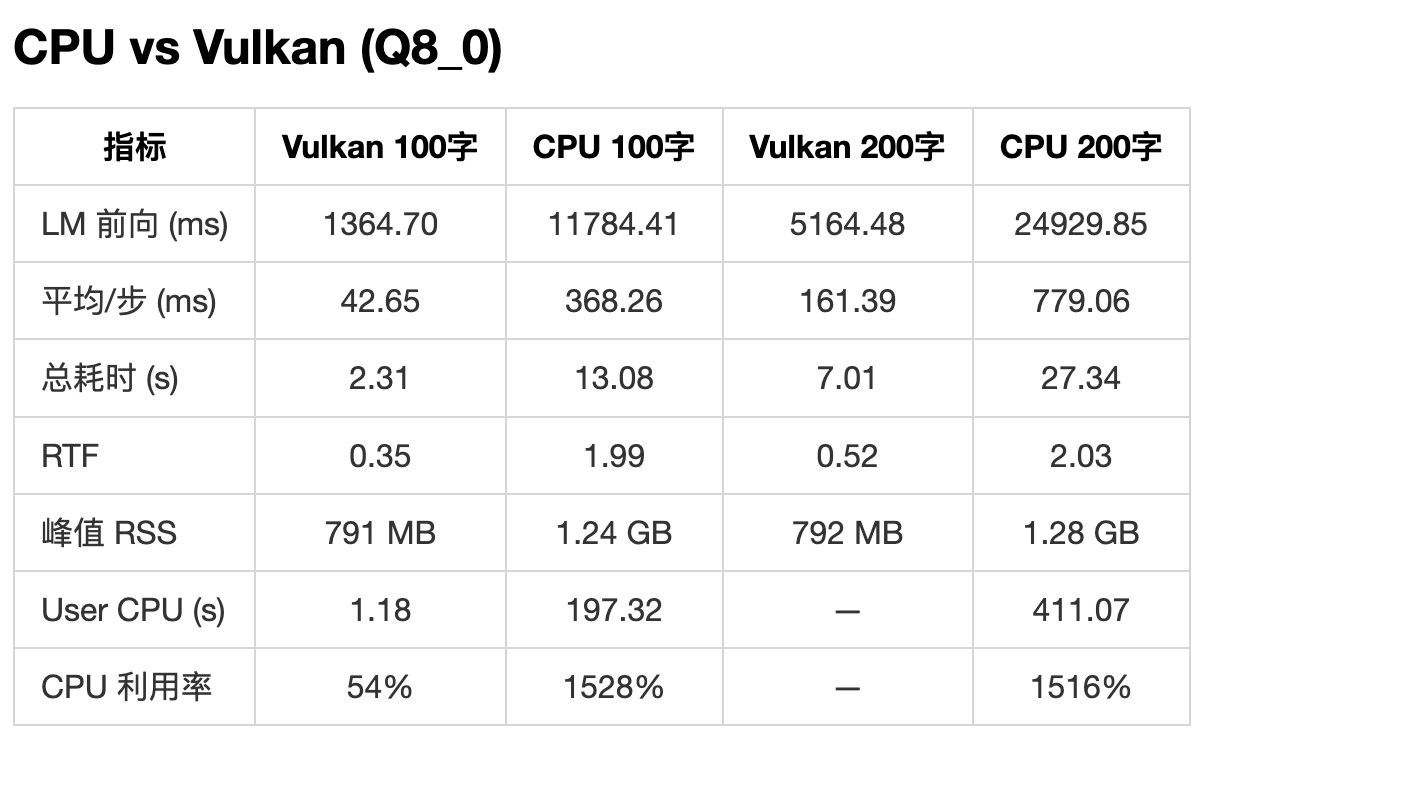
qwen3-tts.cpp amd 优化报告(还在测试中)
还可以对话情绪挺饱满,就是节奏有点快
做了大量重构添加了一个 tts-server, 支持流式,无论多长的文本,首音延迟都是 3 秒,chunk 拆分目前是 30 帧, 今天晚些上传到 github
@terry 到时你们可以用独立显卡测试一下速度
-
qwen3-tts.cpp amd 优化报告(还在测试中)正在优化 qwen3-tts.cpp
https://github.com/predict-woo/qwen3-tts.cpp.gitqwen3-tts 的音色和情绪我感觉还不错,适合有声朗读
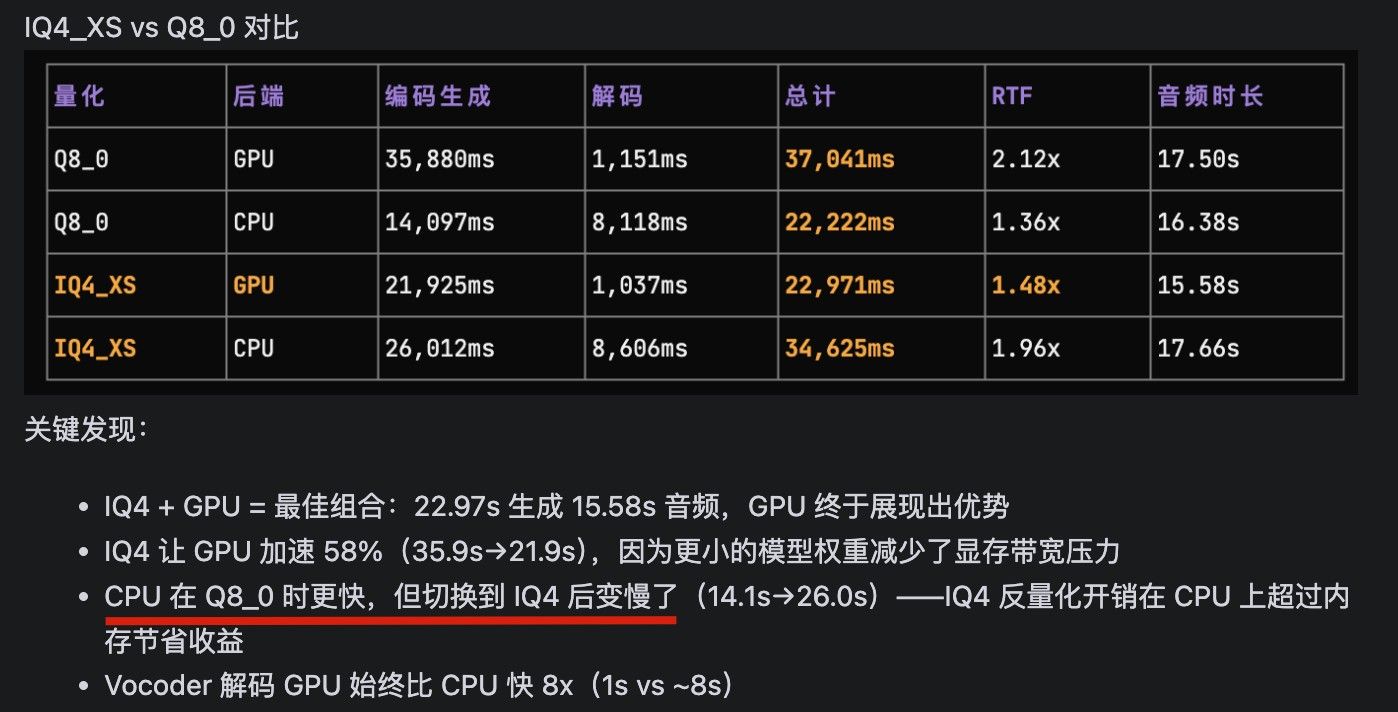
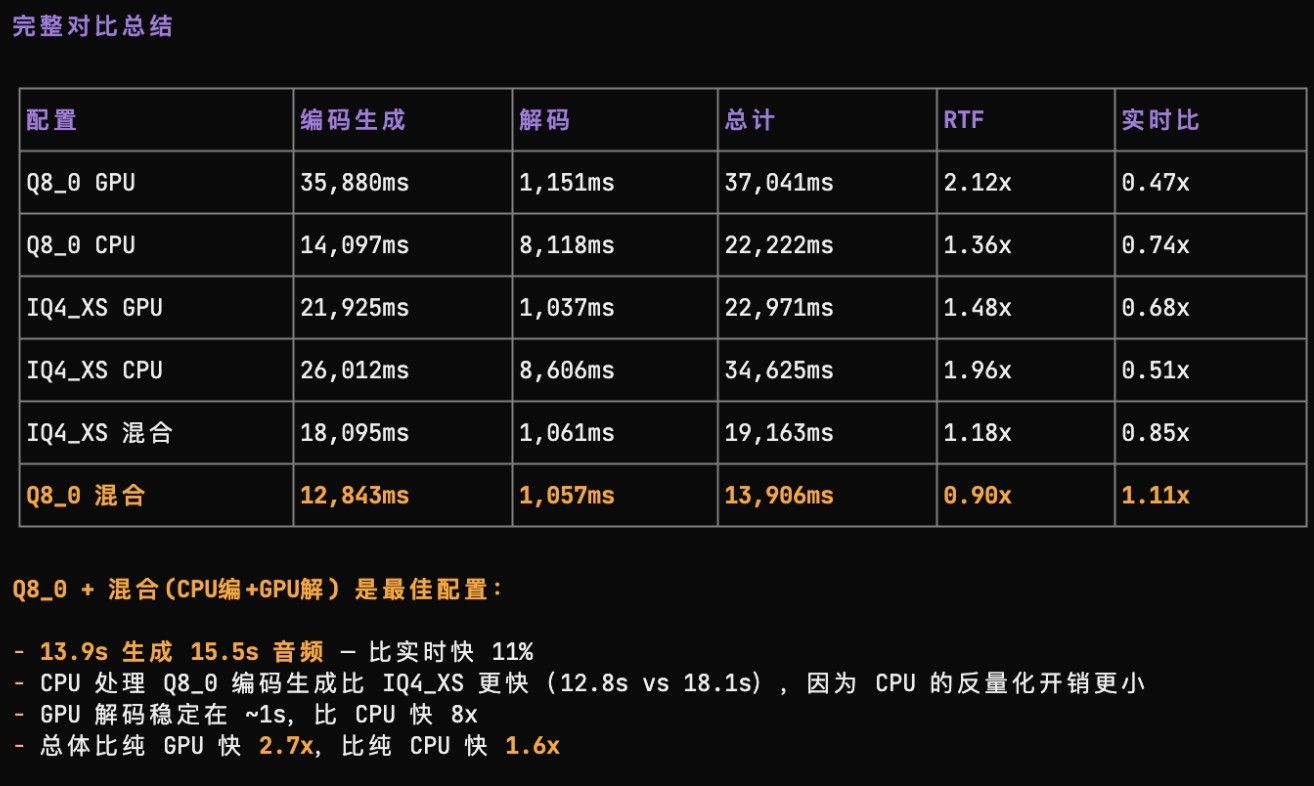
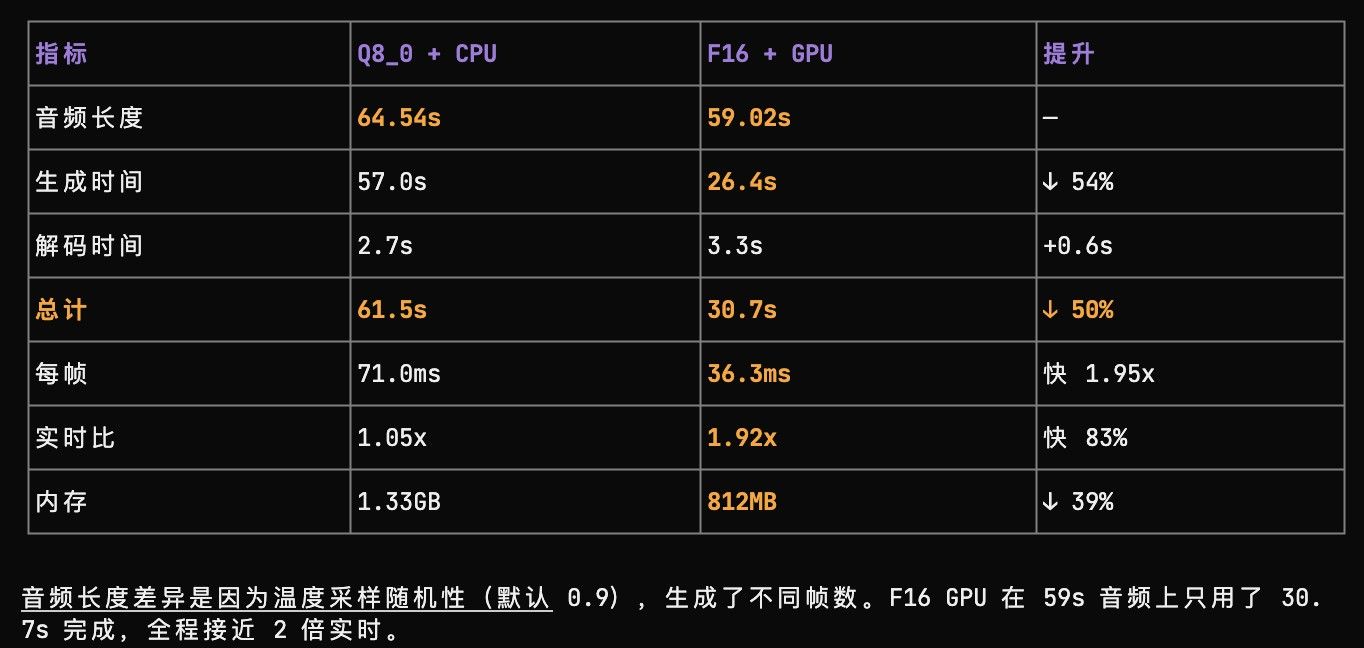
amd max 395 上做充分优化
-
VOX CPM2如何提速 -
【Uncencored】Sulphur-2免审查图生视频模型一窥 -
部署llm用于写代码,构建本地项目编程的话还是不建议用本地模型,尤其是对接 claude code 或 open code 这类编程代理工具,prefill 的速度慢的让人无法忍受。即使上 5090 ,prefill 3000+ , 本地编程模型的水平也实在一般,即使是 qwen3.6-27B 的编程水平也只是凑乎能用而已。
-
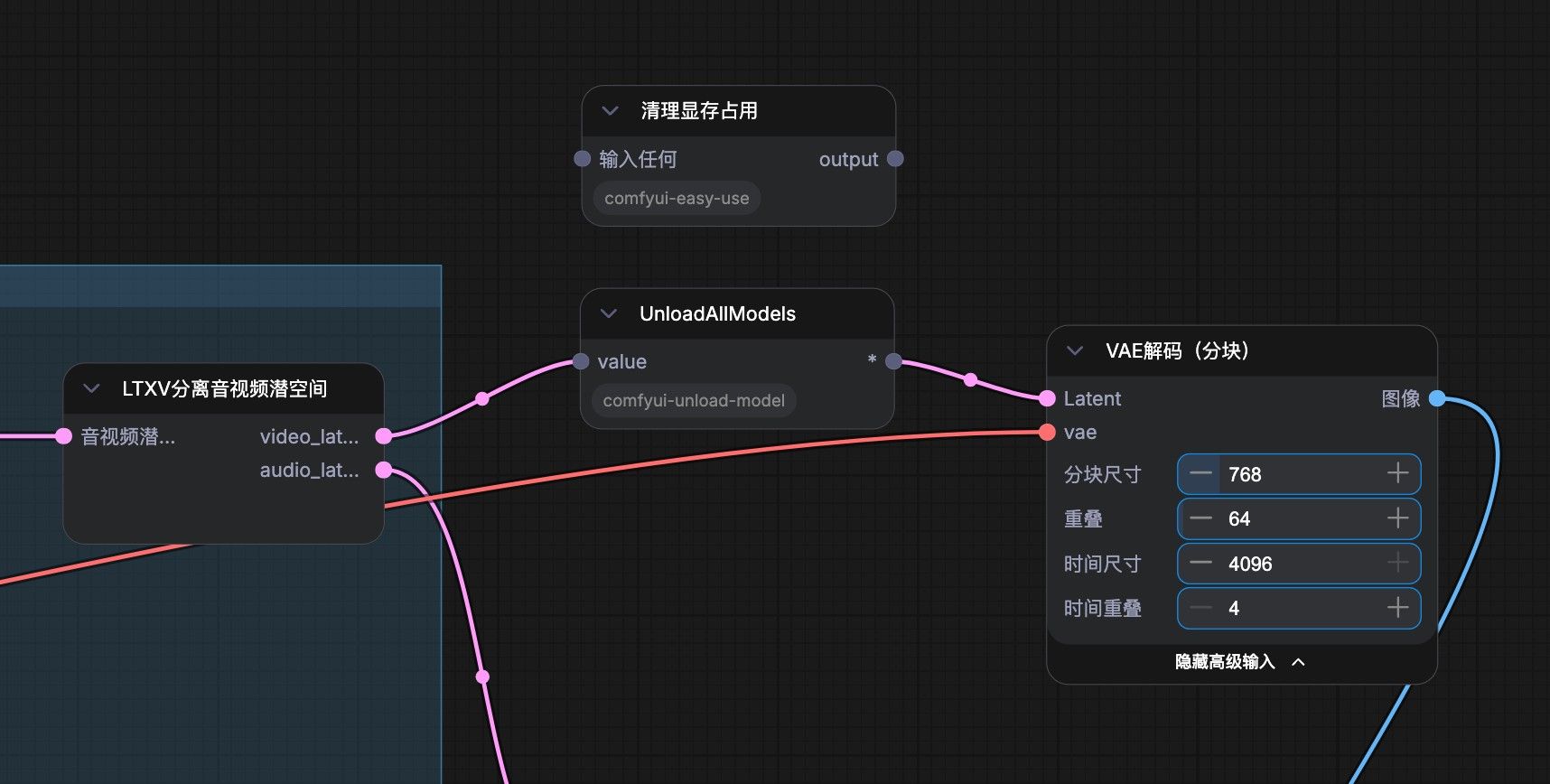
请教:uburntu26.04+7900xtx,comfyui跑不通在 vae 解码节点前面可以加 清理显存或卸载模型节点,vae 解码挺吃显存的,特别是生成长时间的视频,我的 ai max 395, 使用标准的 ltx2.3 图生视频工作流生成 5s的视频,跑到最后就卡死了。加了“清理显存节点” 后,可以生成 10s, 20s 的视频了
-
软路由及内网穿透 - 请教各位老大- easytier 主要是 p2p, 有免费公共节点(只用于发现),如果自己有ip 主机也可以做为一个节点,可以自动中转
- 节点小宝 支持两个节点组网,p2p 免费,中继免费 每月 5G 够用。节点小宝使用体验非常不错, 127.0.0.1:anyport 他自动映射到 组网ip + 端口
-
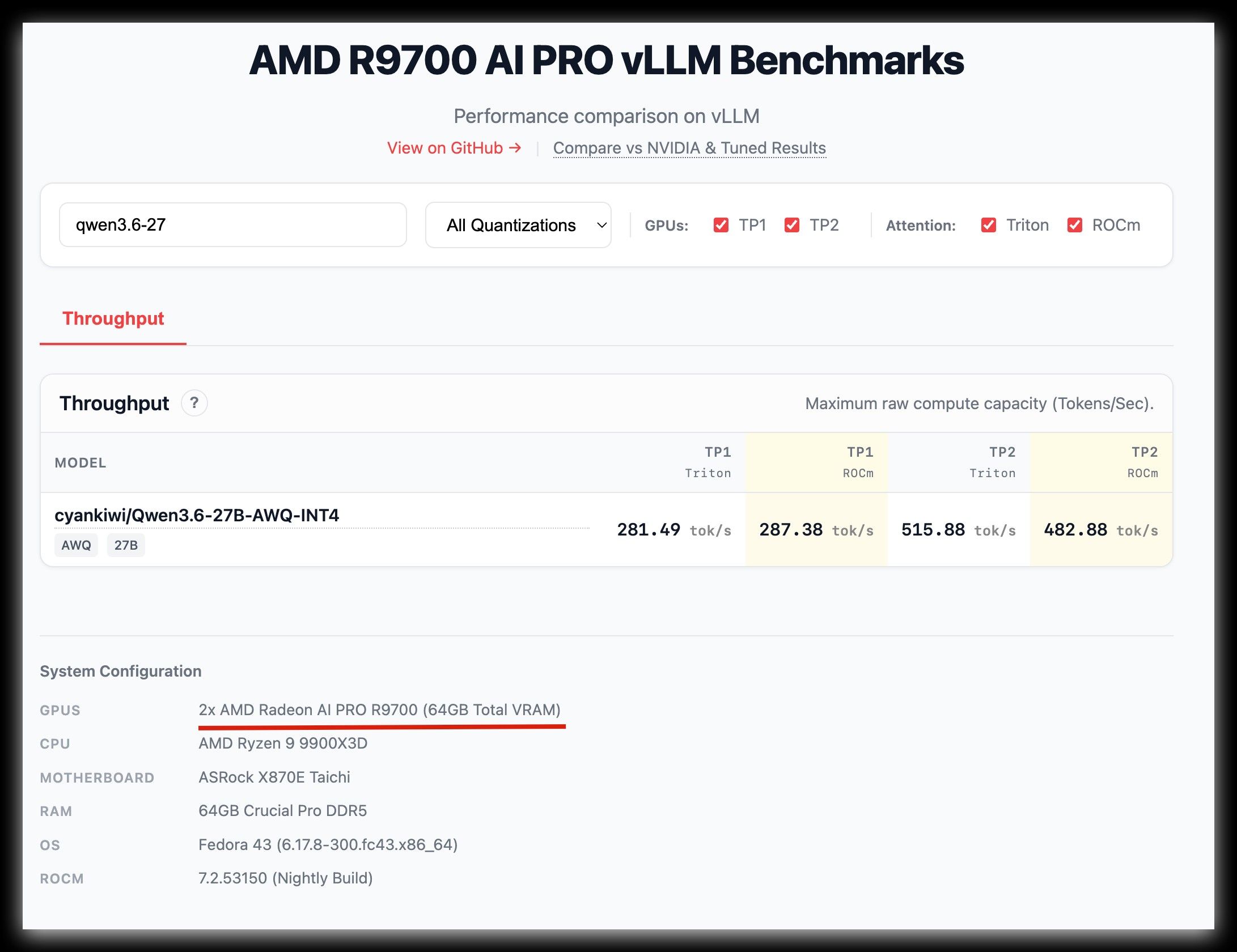
[申请精华帖]秀一下刚到的R9700,以及初步配置llama.cpp -
[申请精华帖]秀一下刚到的R9700,以及初步配置llama.cpp数据来源 : https://kyuz0.github.io/amd-r9700-ai-toolboxes/
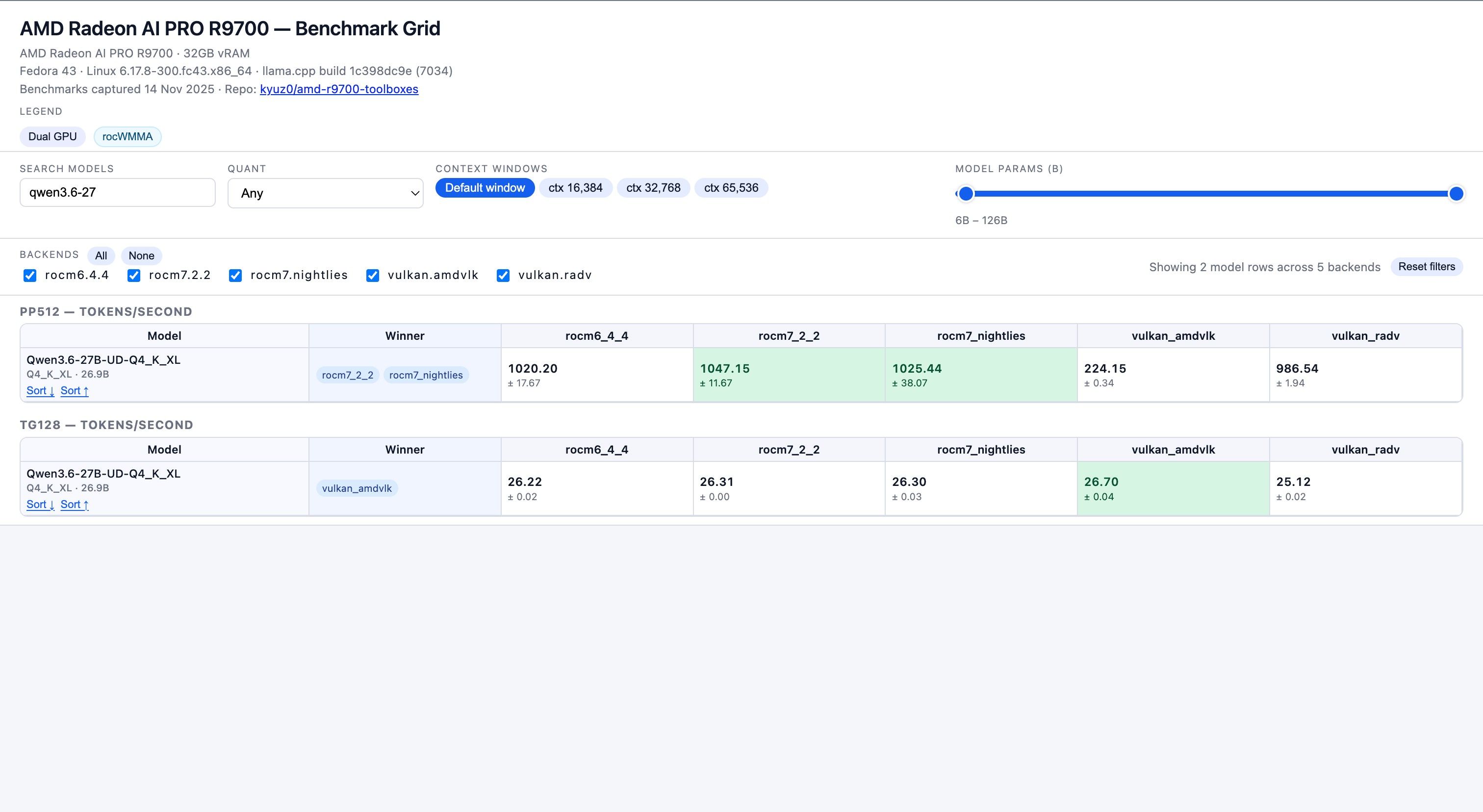
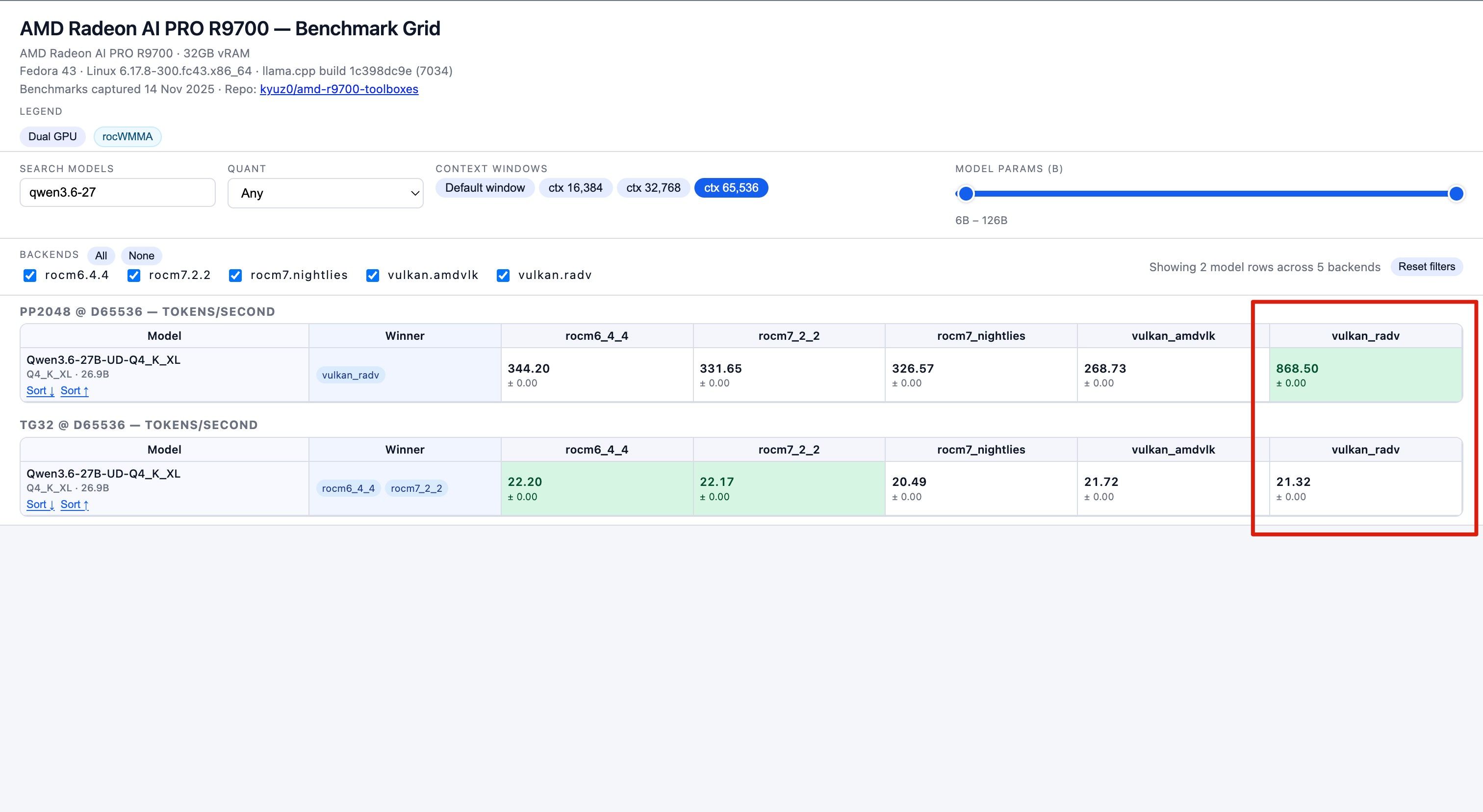
上面的测试数据,老外没有使用投机解码
如果开投机解码,估计能到 50+ token / s -
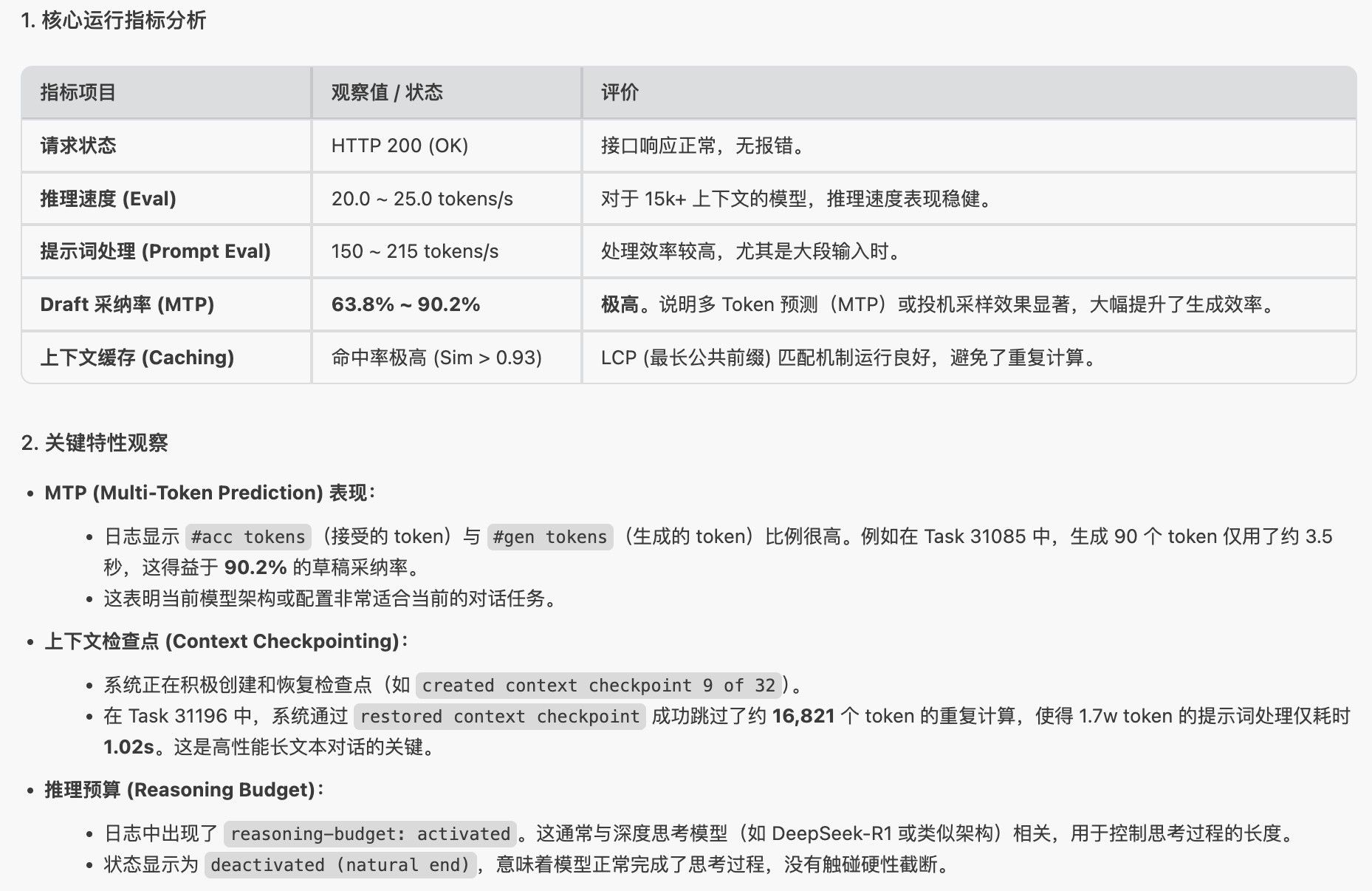
我尝试了mtp和tuboquantllama.cpp mtp 确实可以用, 我的 ai max 395 跑 qwen3.6-27b 24T/s
参考这个社区主题
mtp 分支还没有合并到主分支,目前还存在的问题
- 只支持np = 1
- 暂不支持多模态