在 vae 解码节点前面可以加 清理显存或卸载模型节点,vae 解码挺吃显存的,特别是生成长时间的视频,我的 ai max 395, 使用标准的 ltx2.3 图生视频工作流生成 5s的视频,跑到最后就卡死了。加了“清理显存节点” 后,可以生成 10s, 20s 的视频了
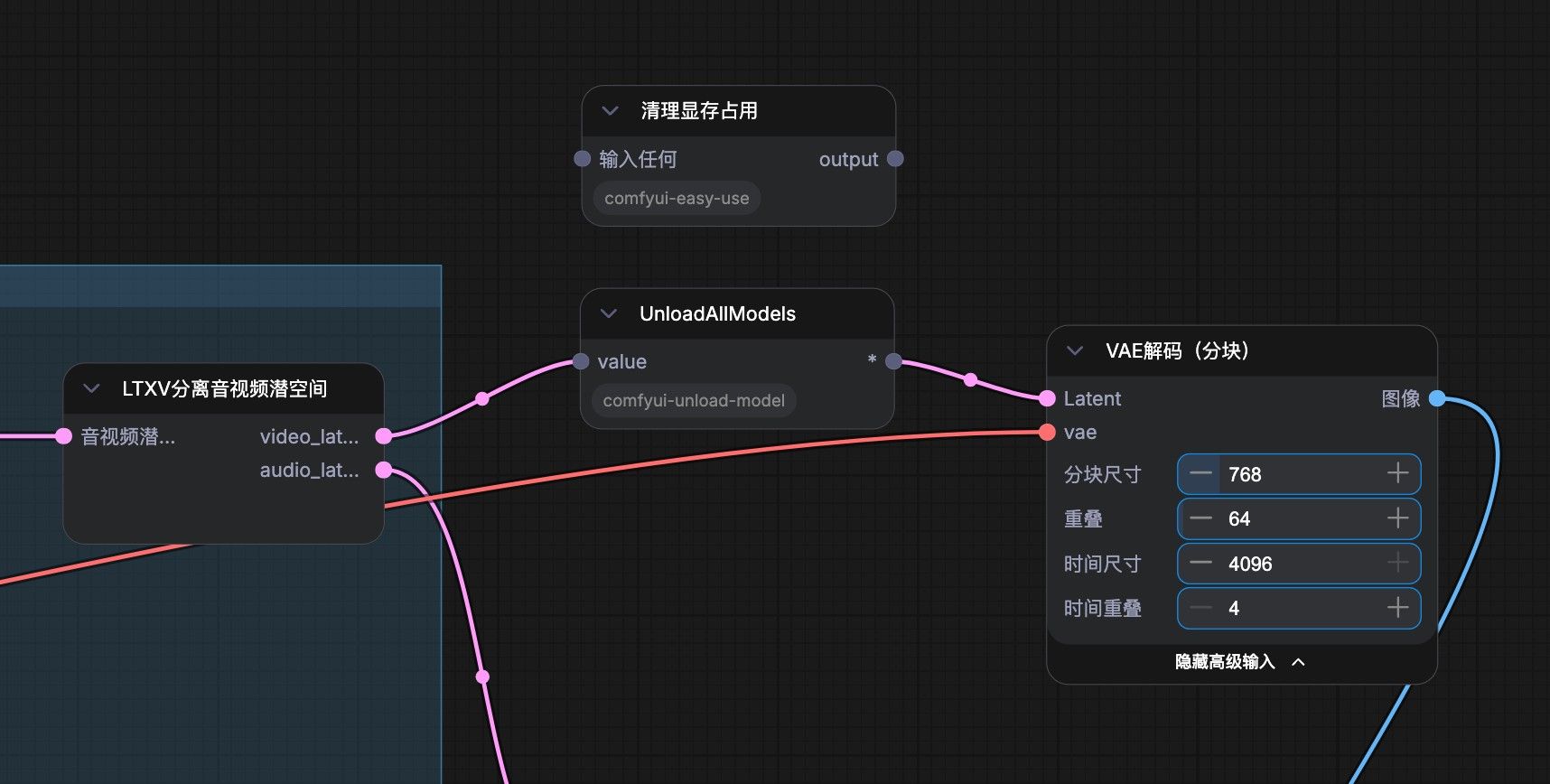
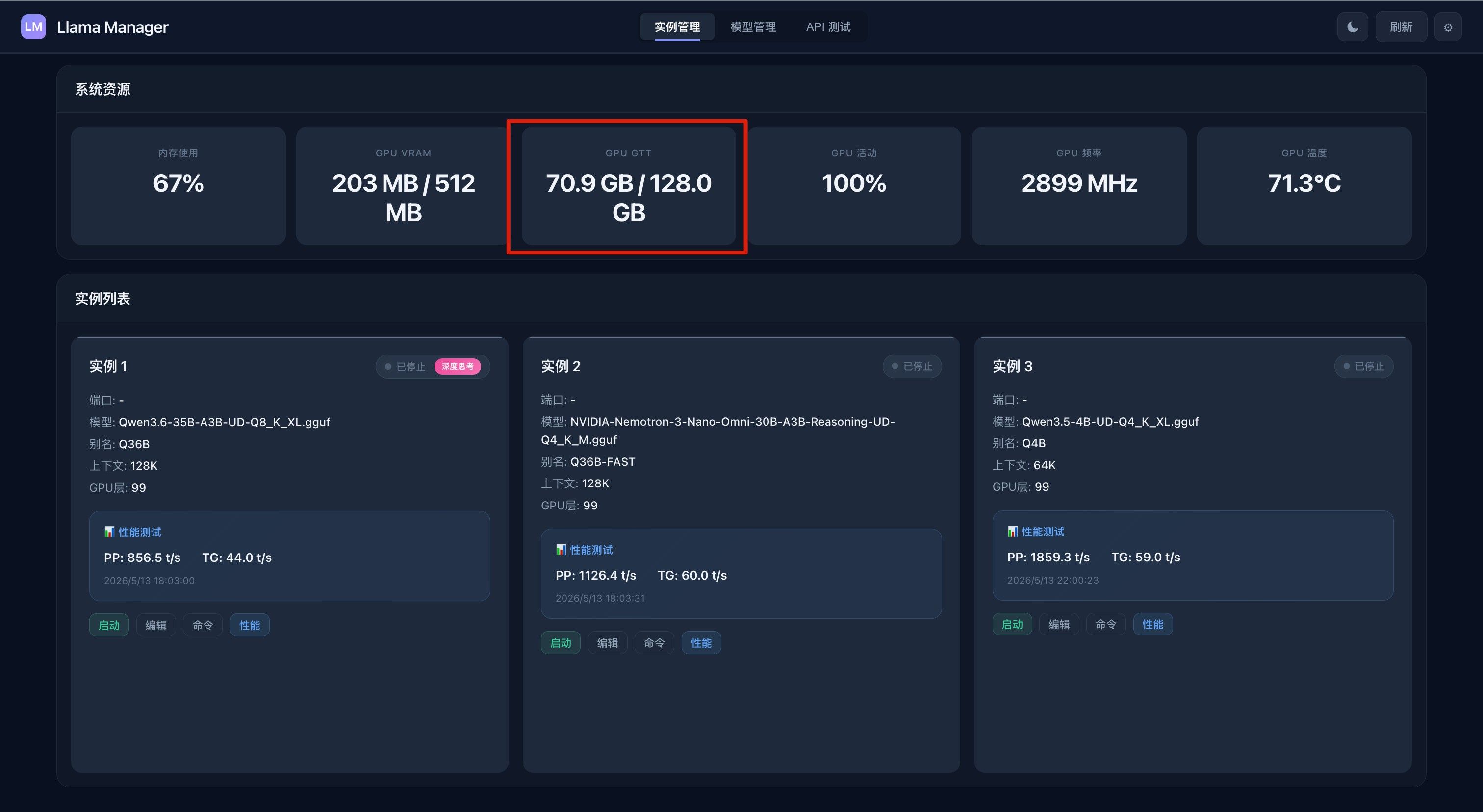
在 vae 解码节点前面可以加 清理显存或卸载模型节点,vae 解码挺吃显存的,特别是生成长时间的视频,我的 ai max 395, 使用标准的 ltx2.3 图生视频工作流生成 5s的视频,跑到最后就卡死了。加了“清理显存节点” 后,可以生成 10s, 20s 的视频了
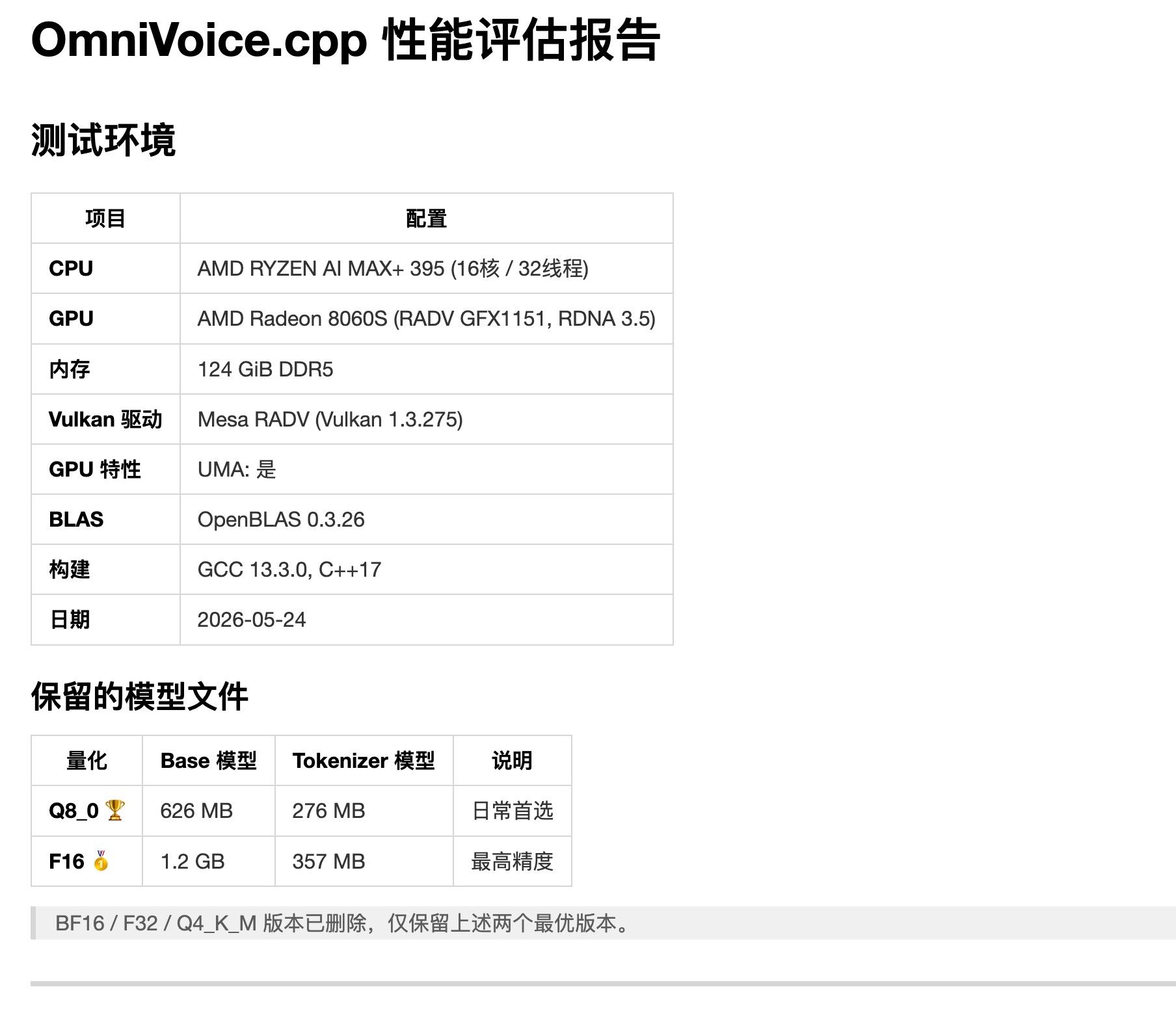
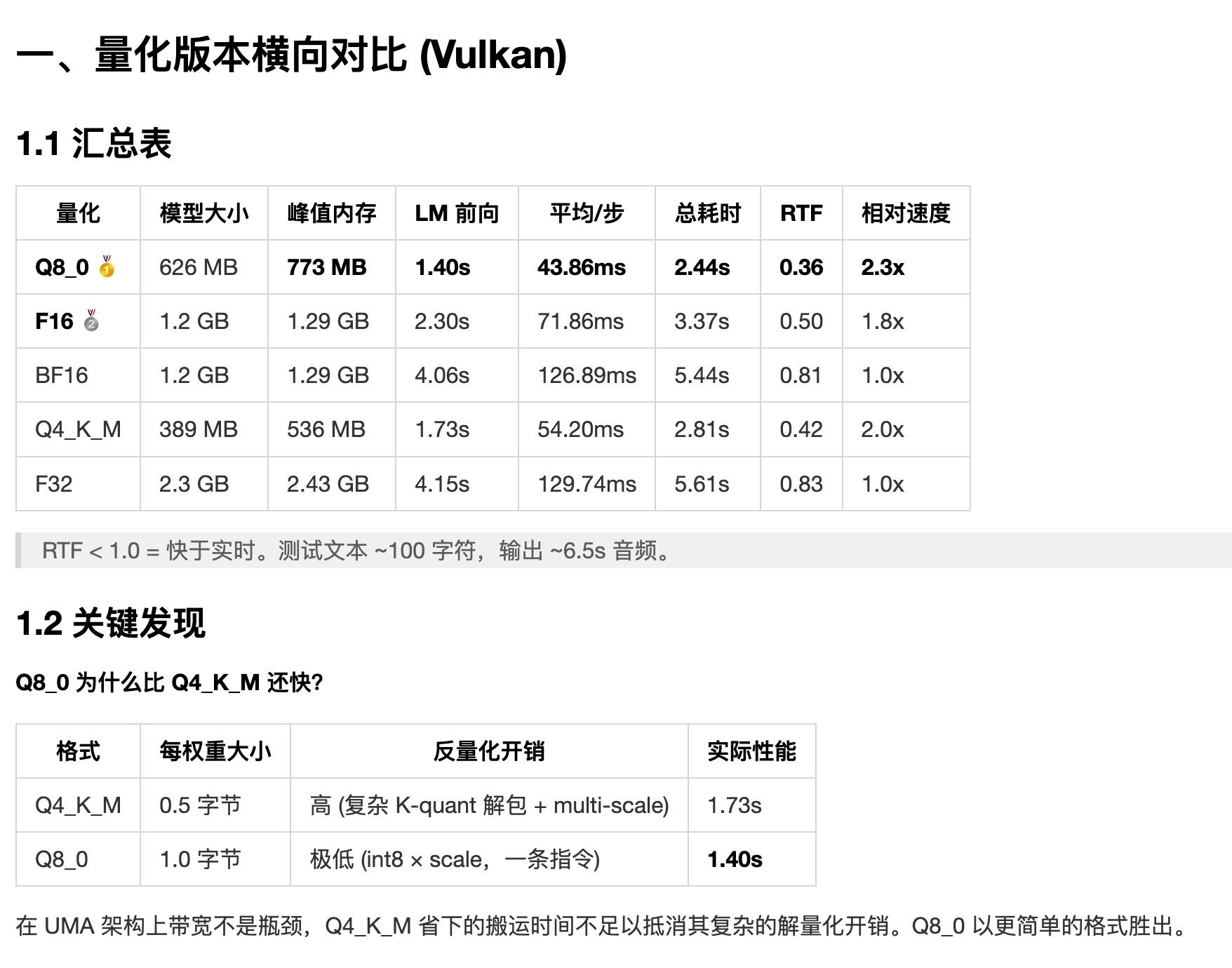
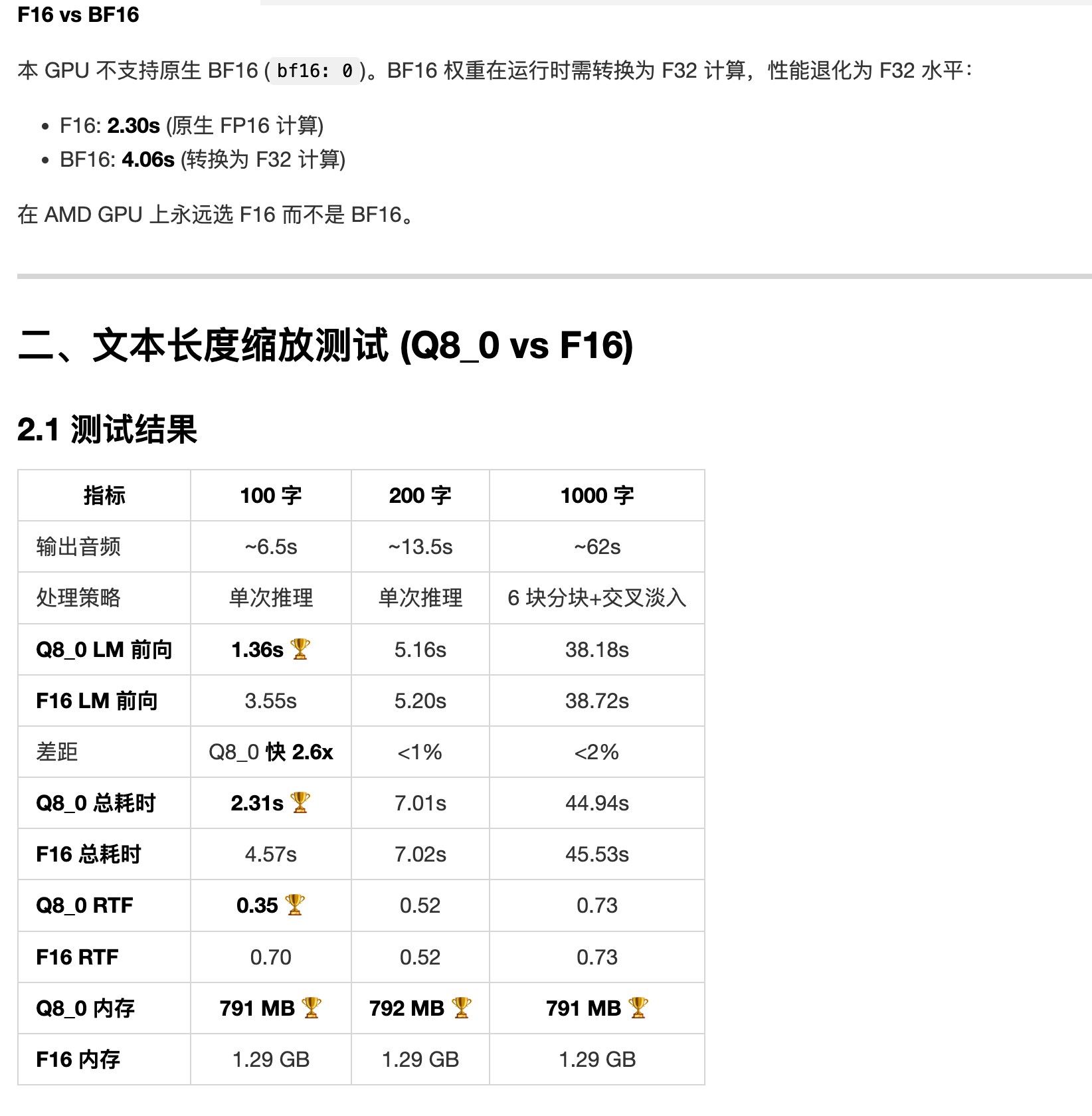
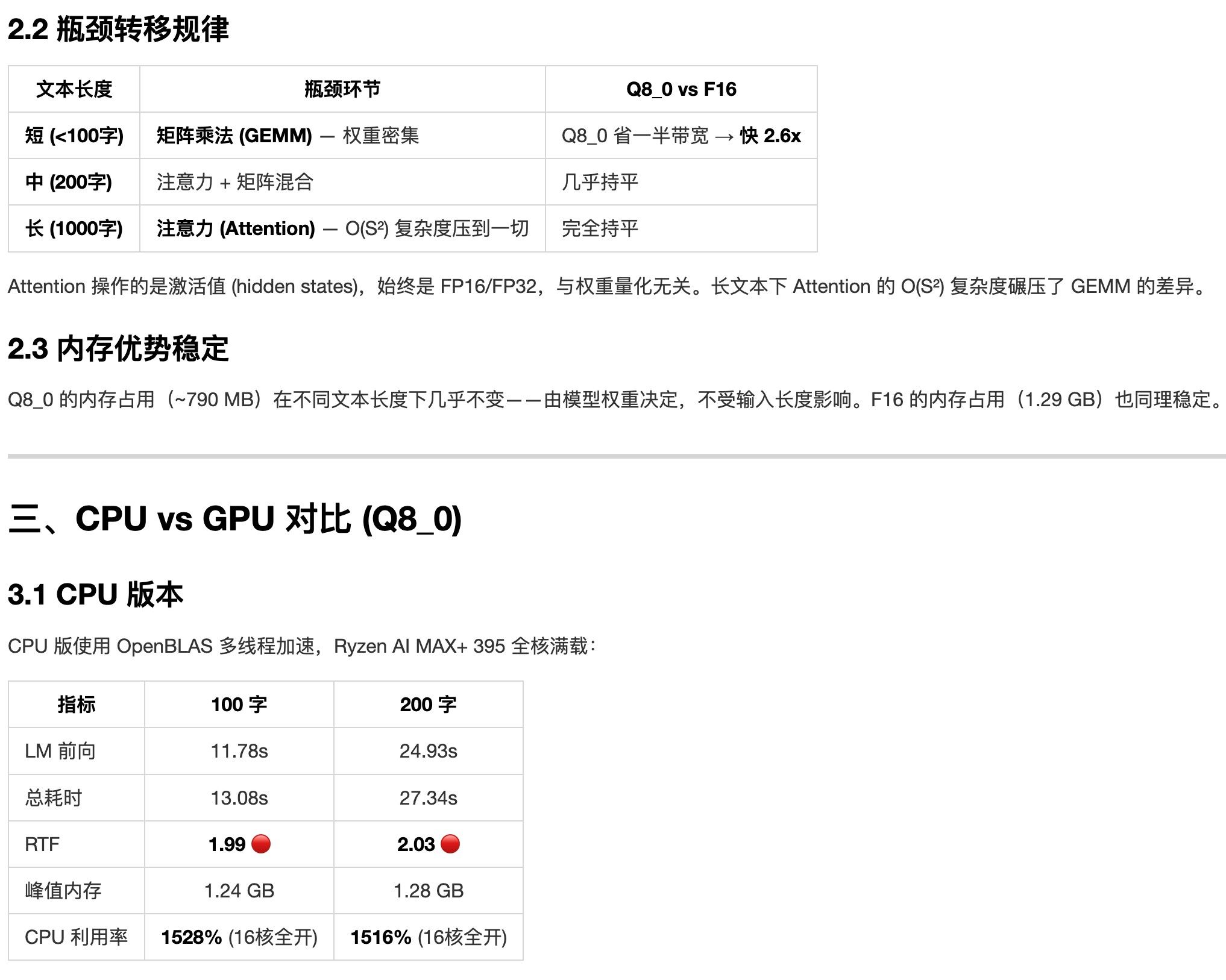
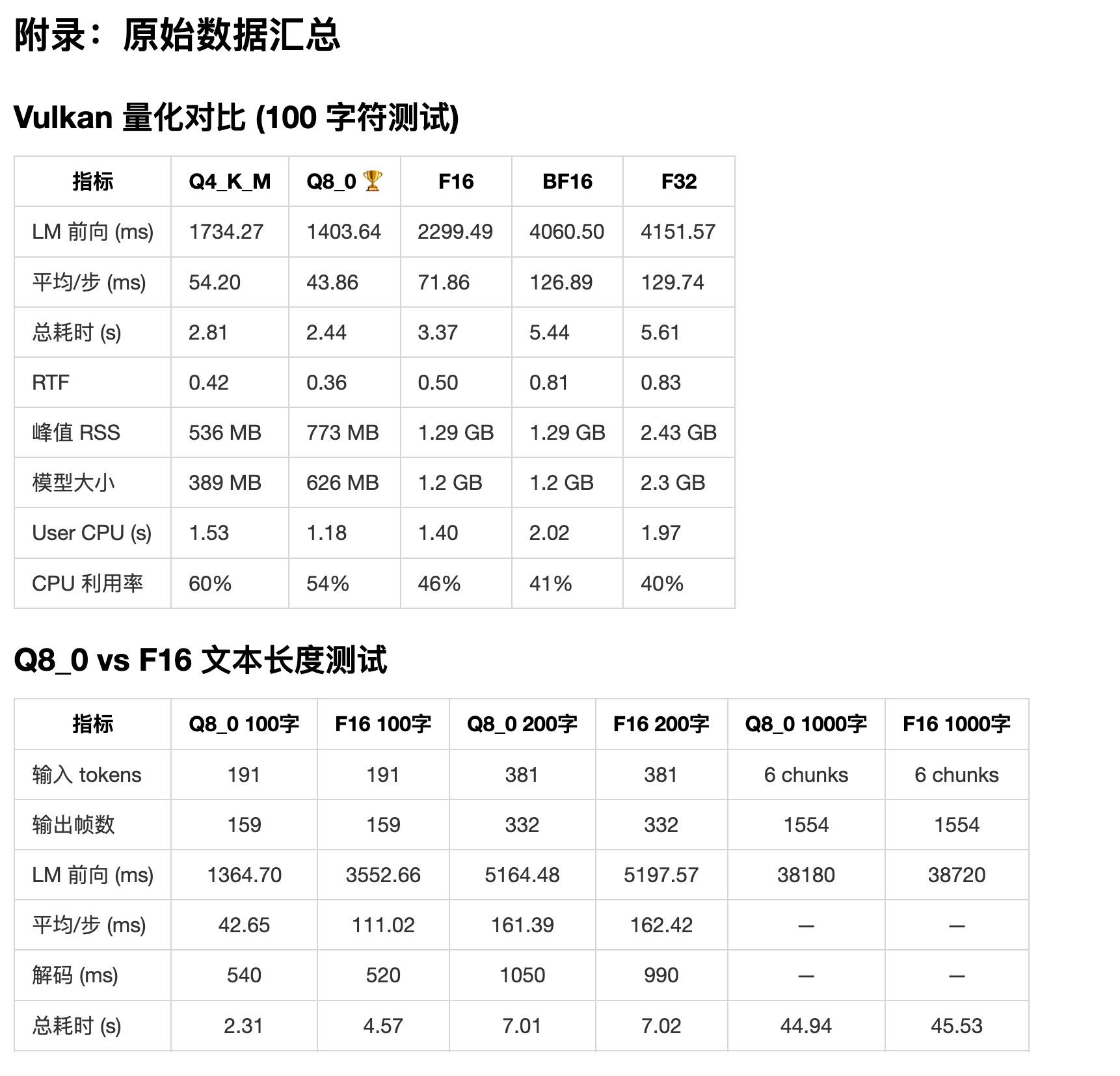
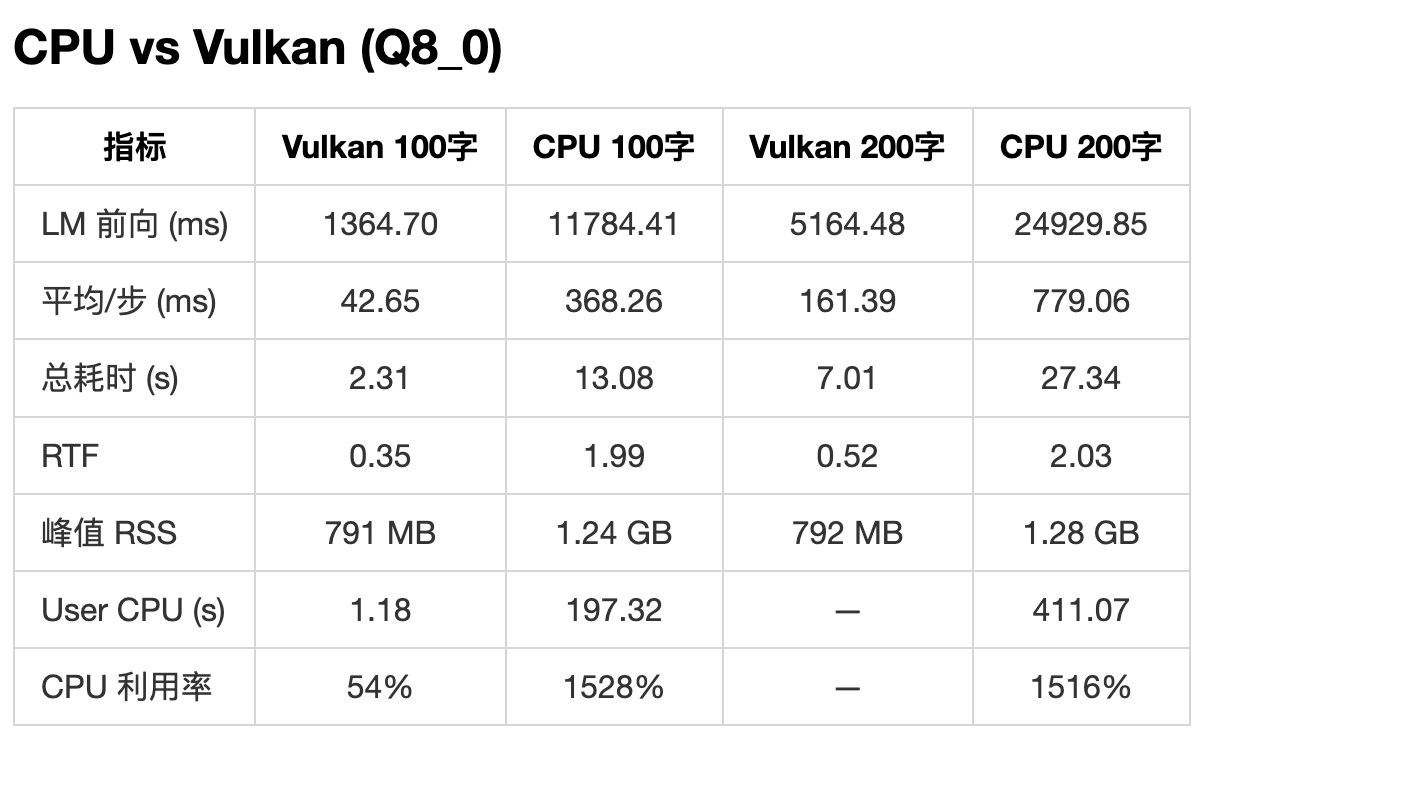
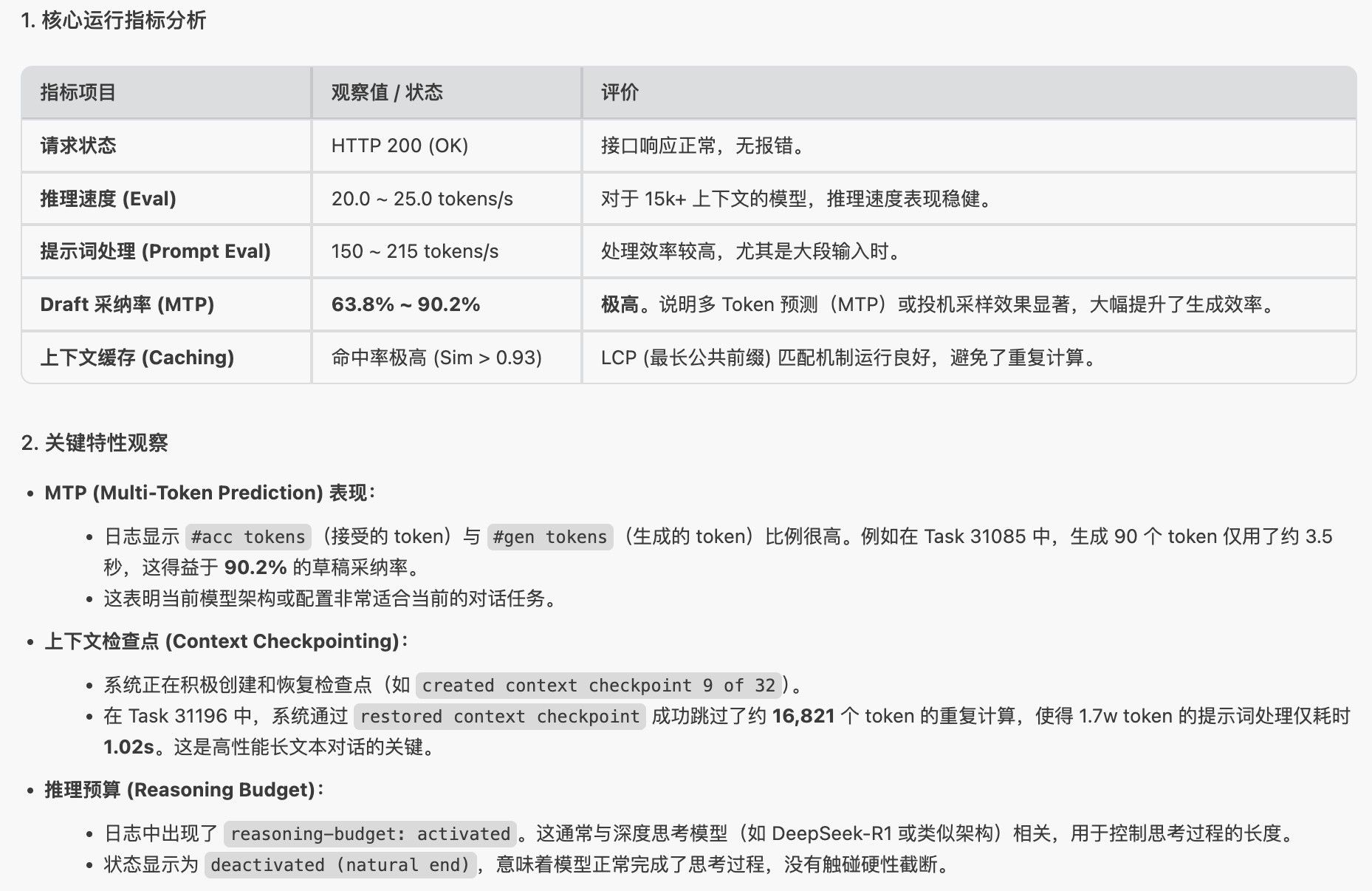
llama.cpp mtp 确实可以用, 我的 ai max 395 跑 qwen3.6-27b 24T/s
参考这个社区主题
mtp 分支还没有合并到主分支,目前还存在的问题
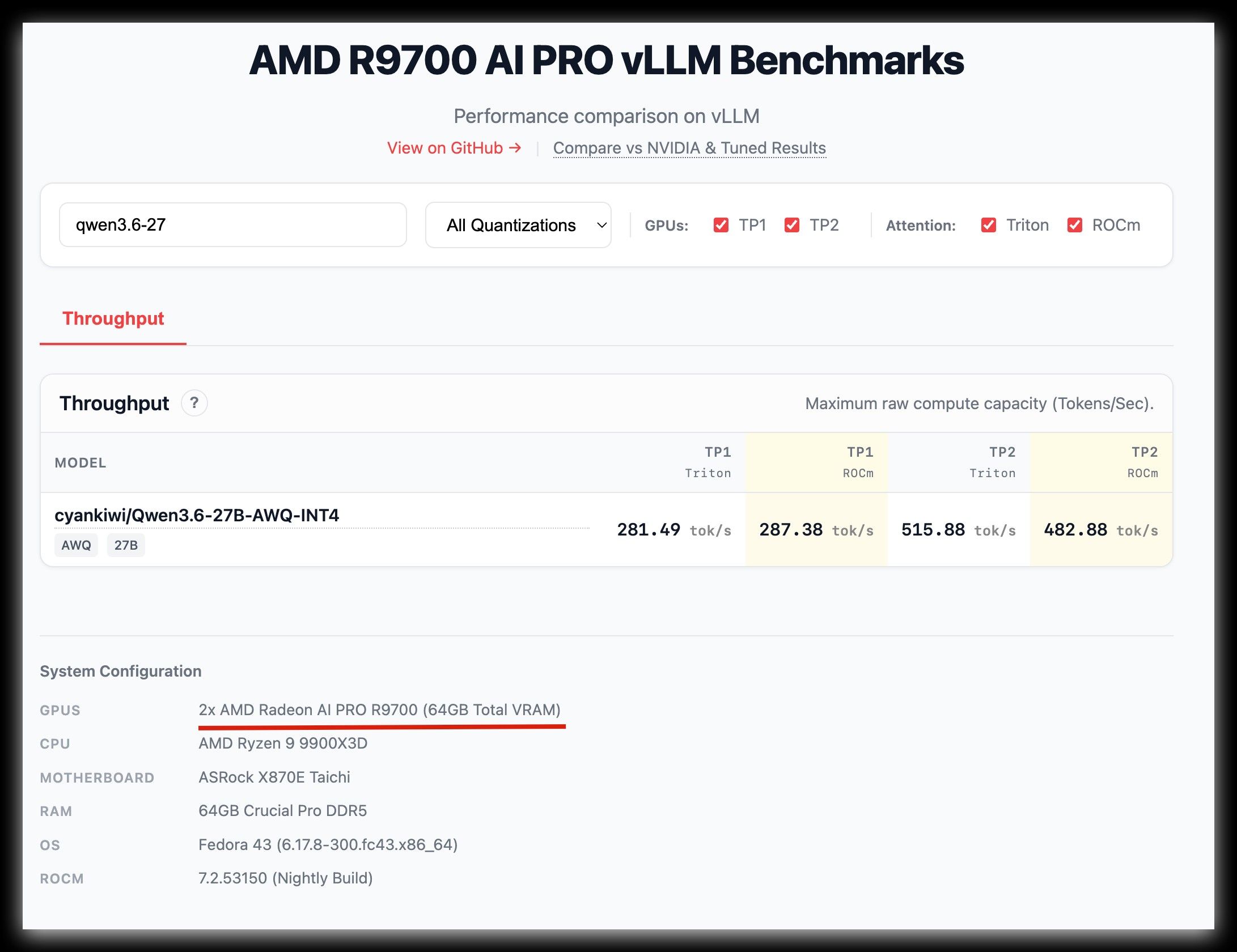
数据来源 : https://kyuz0.github.io/amd-r9700-ai-toolboxes/
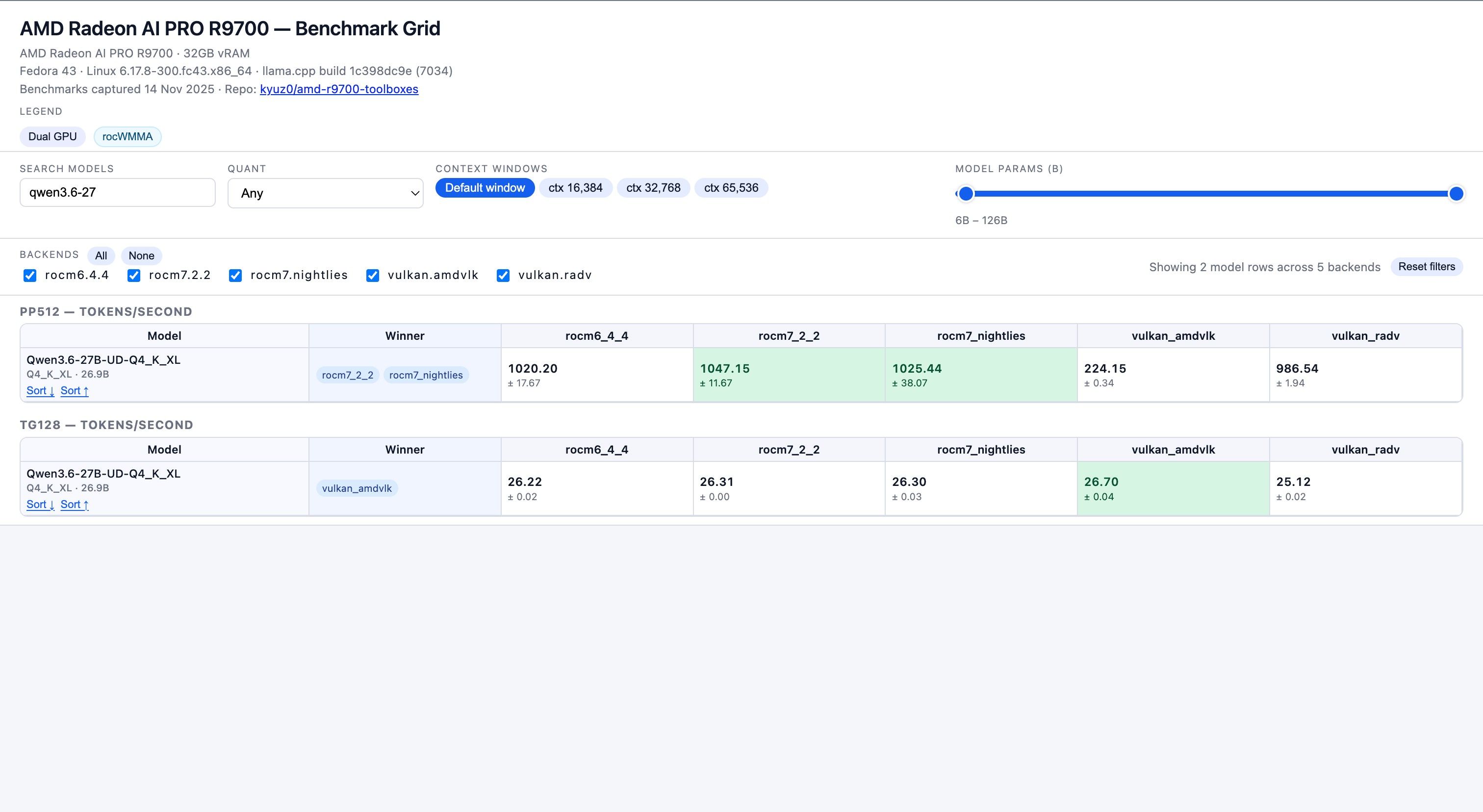
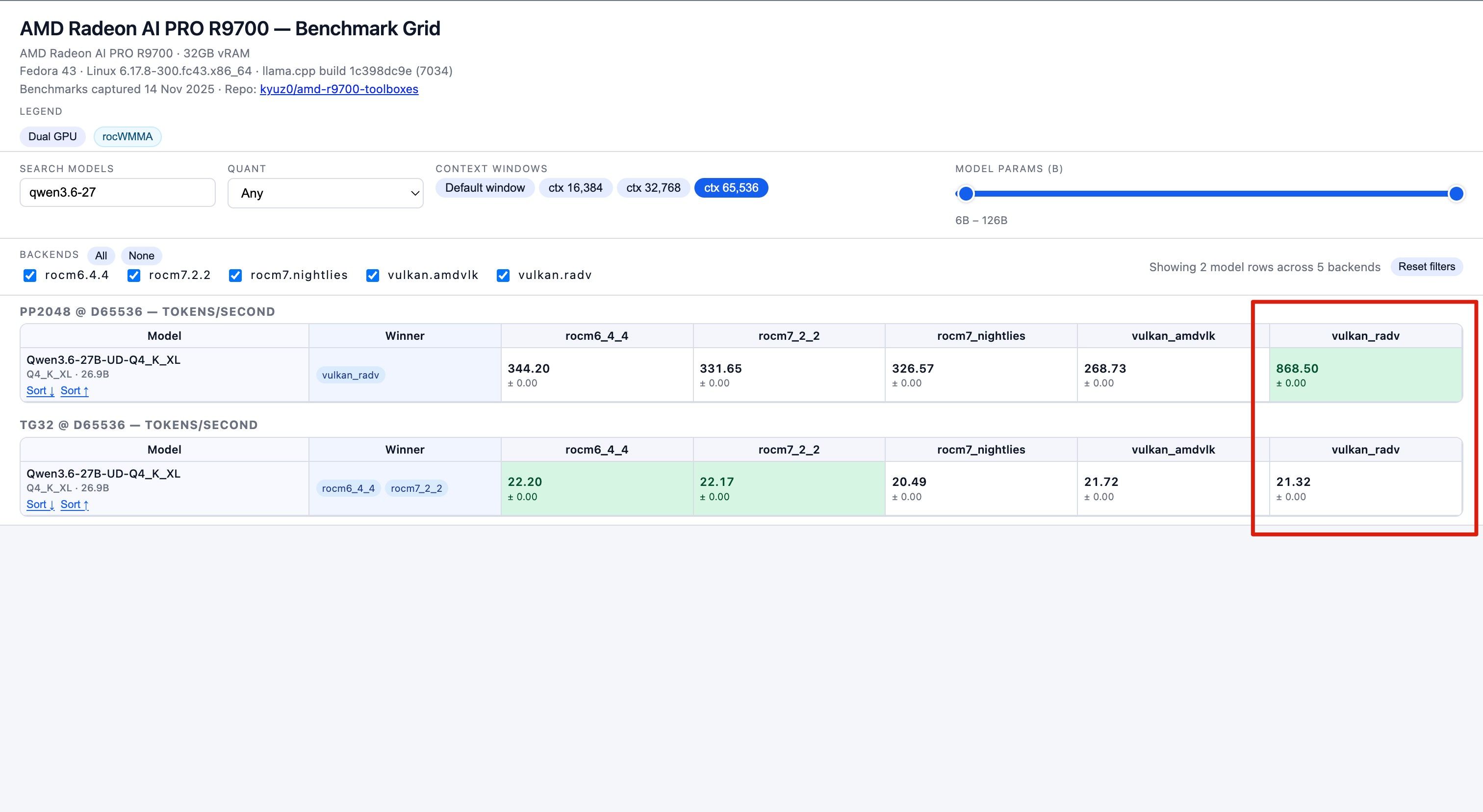
上面的测试数据,老外没有使用投机解码
如果开投机解码,估计能到 50+ token / s