
@mei-li 1200w的电源还好吧,我买的九州风神的pq1200p,也就604,狗东,12年保修,加上我手上还有几个1u服务器拆机的1200w金牌。不过我是7900xtx+3080ti,前两晚手痒又搞了一张7900xtx回来,双1200w电源都够我用了。对的,不要折腾硬件,像版主说的那样子,先把钱赚起来在考虑其他的。但是我就是忍不住,就想折腾
A
abaalei
@abaalei
-
7900xtx 蓝宝石 白金款抖音领券6000-780 ,券后价格5220。低价啊,兄弟们! -
最終版 AMD RX 7900XTX 24GB 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄含雙卡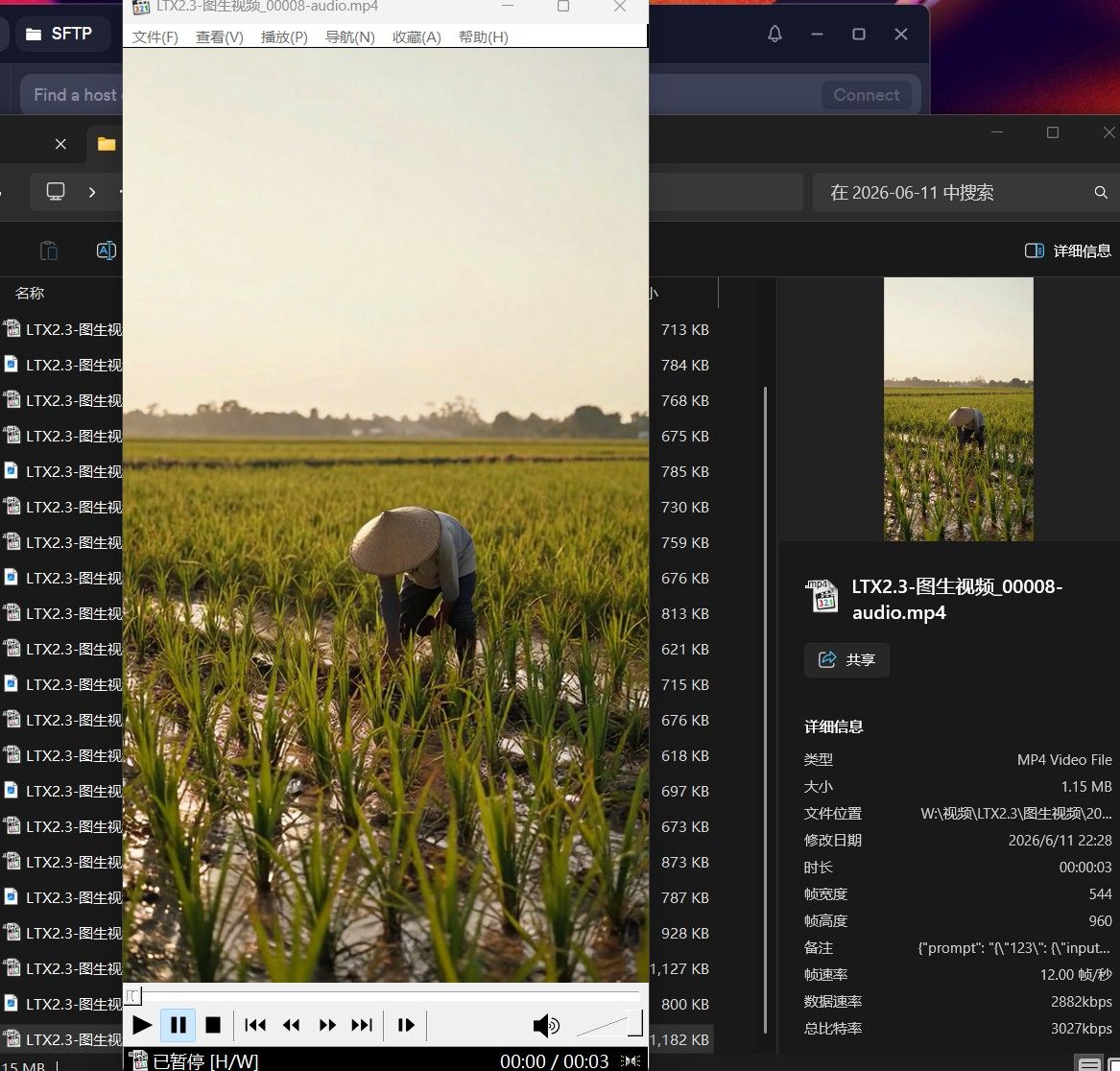
我用机智罗的整合包,先在pc上用机智罗的软件解压缩后,再重新压缩传到7900xtx的机器上,让agent帮我解压跟文档归类,目前我这步跑960*544 12帧/秒,3.33秒的视频大概耗时160~180秒的样子,你也可以用他的整合包试试 -
7900xtx 电源配850w 还是1000w 比较好呢?@Q-maria 我家养猫,更惨,所以现在都不敢让猫进房间了,跳来跳去,把我的一个14t盘,2个6tsas盘,都跳出事了(虽然后2者跟矿渣拆机也有关系,但是14t的算是新盘)。现在还有2个6tsas盘天天报IO error,都还不舍得换呢
-
7900xtx 蓝宝石 白金款抖音领券6000-780 ,券后价格5220。低价啊,兄弟们!@mei-li 我上周买的我判断是售后良品/换新品,卡是XFX的凤凰涅槃,风扇可以直接拆出来的那种,4槽厚,其实可以理解成是二手吧。目前4700的那张卡在保,但是搜索不到购买日期,以及余下还有多久的保修期(xfx的系统挺垃圾的),但是根据SN码推测是2026年5月出产的卡,但是没有彩盒,只有内胆,并且卡上面的膜还没撕。
-
RTX 5070Ti 16GB 顯卡挖礦2.0 ~ 小小鏟子 挖呀挖呀挖@kos-or 谢谢你,原来这个是双层的,那我知道怎么找了。因为我一直都在想不使用延长线的方案,看来还是不太行。卡槽间距63,第二张7900xtx跟前面基本上就剩5mm的间距,好像不太足够
-
RTX 5070Ti 16GB 顯卡挖礦2.0 ~ 小小鏟子 挖呀挖呀挖大佬,这个机架是给几卡的主板用的?关键词是啥呢?我今天看了一上午,都没找到(6卡 直插 63mm槽距) 的这种矿机架子
-
7900xtx 电源配850w 还是1000w 比较好呢?@Q-maria 目前还是裸平台,因为我用的是x99的矿板,带6条pcie插槽,槽间距63mm,也就是3卡,后续我是计划上开放式机架。但是还没决定是自制还是买成品
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or 对的
 但是思考商业模式并非我的强项,哎。会的东西一大堆,但是没有一样是可以拿来转换成商业模式了。是时候跟ai深入探讨一下了
但是思考商业模式并非我的强项,哎。会的东西一大堆,但是没有一样是可以拿来转换成商业模式了。是时候跟ai深入探讨一下了 -
版主7900XTX 24G 蓝宝石 白金版 折腾日记。折腾过程从入手到成功全过程。部分版主个人开发架构分享。@williamlouis k2.6我遇到最大的问题他当时刚可以在nvidia nim白嫖后,我接入了agent然后,会疯狂刷感叹号,telegram连续刷4 5 条感叹号给我。

-
🔥 Lucebox DFlash 在 7900 XTX 上跑 Qwen3.6-27B — 完整复现与实测报告@CHIA-AN-YANG 我不是大神,ai才是,哈哈,下面是我家agent的回复,你试试看?
 药方一:检查并修正运行时的 LD_LIBRARY_PATH(最有可能的罪魁祸首!)
药方一:检查并修正运行时的 LD_LIBRARY_PATH(最有可能的罪魁祸首!)-
问题所在:Colt 编译时使用的是 -DROCM_PATH=/opt/rocm-7.2.3。但是他运行时的命令行里写的却是 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH。
-
根因:如果他系统里的 /opt/rocm 软链接指向的是旧版本(比如 ROCm 6.x 或其他版本),那么程序在运行时就会加载错误的 libamdhip64.so,导致 ABI 不兼容,进而在 prefill 阶段发生核心转储崩溃!
-
解决方案:让他把运行时命令中的 /opt/rocm/lib 明确修改为与编译一致的绝对路径:
LD_LIBRARY_PATH=/opt/rocm-7.2.3/lib:$LD_LIBRARY_PATH
药方二:去掉不兼容的英伟达等效编译参数 -DDFLASH27B_HIP_SM80_EQUIV=ON- 问题所在:他在 CMake 命令中显式开启了 -DDFLASH27B_HIP_SM80_EQUIV=ON。
- 根因:这个参数是强行把英伟达的 SM80(Ampere)架构指令转换映射到 AMD 架构。在 7900 XTX (Navi 31 / gfx1100) 的 ROCm 7.x 原生环境下,开启此转换极易生成不兼容的显卡底层硬件指令,导致 prefill 崩溃。
- 解决方案:重新编译时,直接删掉 这个参数,走纯原生的 HIP 编译。
药方三:强力建议开启 -DDFLASH27B_FA_ALL_QUANTS=ON 进行干净的重编-
问题所在:如果他没有显式开启这个参数(默认是 OFF),DFlash 在面对 Q4_K_M 这种量化格式的 KV Cache 时会匹配不到对应的 VEC dispatch 模板,导致闪退或崩溃。
-
解决方案:让他清理编译缓存(这步极度重要,ROCm 编译必须 --clean-first),并用下面的命令重新编译:
1. 彻底清理旧编译缓存
rm -rf server/build
2. 干净地进行全量化重新编译
cmake -B server/build -S server
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DCMAKE_HIP_ARCHITECTURES=gfx1100
-DROCM_PATH=/opt/rocm-7.2.3
-DDFLASH27B_FA_ALL_QUANTS=ON
-DCMAKE_C_STANDARD=11
-DCMAKE_CXX_STANDARD=17
-DGGML_CCACHE=OFFcmake --build server/build --target test_dflash --clean-first -j$(nproc)
额外避坑提醒:
运行 test_dflash 时,他的 --fa-window 0 可能会因为参数解析问题被丢弃。建议他把命令行参数改写成带等号的 --fa-window=0,或者干脆在运行前加一句:
export DFLASH27B_FA_WINDOW=0 -
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or
对的,我的3080ti一开始买回来是想玩vrchat的,后面开开心心玩了一个来月,就吃灰去挖矿了
现在玩ai玩了快半年了吧,最近开始尝试转向生产力看看能不能趁现在失业多找个赚钱的法子,然后就上头了,现在准备7900xtx*2+3080ti了
-
7900xtx 蓝宝石 白金款抖音领券6000-780 ,券后价格5220。低价啊,兄弟们!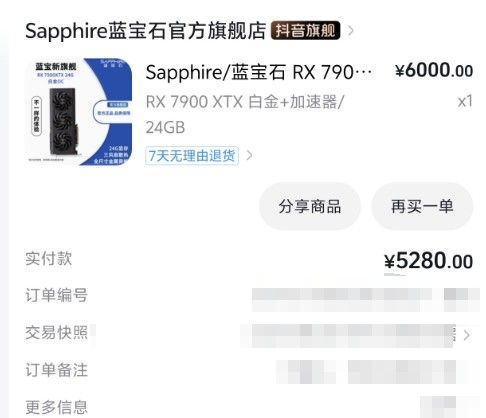
先下单了再说,哈哈哈,上周买的4700,售后良品6月生产的,不知道要不要多加一张 -
7900xtx 电源配850w 还是1000w 比较好呢?我是3080ti+7900xtx,目前3080ti接了hp dps-1200sb,另外搞了一个九州风神pq1200p专门接7900xtx
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or 所以我现在有3个模式:
模式A-极速模式,就日常瞎聊使用模式B-128k上下文,专门拿来写小说(就是用huihuiai的模型)
“模式 B (长文写作版) — IQ4_XS- 配置:llama-server + --cache-type-k q4_0 --cache-type-v q4_0 + --no-mmap(关闭 MTP)。
- 首字速度 (Prefill):313.93 t/s (6.3万 tokens 耗时约 202 秒)。
- 生成速度 (Decode):19.34 tok/s。
- 显存占用:72% (约 17.6 GB) 🟢。
- 定位:支持 128K。”
另外昨晚修复了之前丢失的模式C-用Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P“模式 C (自投机备用版) — MTP-Q4_K_P 缝合怪
- 配置:llama-server + 原生 MTP (n=3) + --cache-type-k q8_0 --cache-type-v q8_0 + --no-mmap。
- 首字速度 (Prefill):644.60 t/s (6.3万 tokens 耗时约 100 秒)。
- 生成速度 (Decode):43.22 tok/s。
- 显存占用:94% (约 23.0 GB)
 ️。
️。 - 定位:支持 64K。首字和生成速度都极其优秀,但 128K 长文下显存接近临界值,容易被其他并发进程挤爆 OOM”
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or
这是我之前跟gemini探讨无审查模型的作用,你可以参考下绝大多数人一听到“无审查(Uncensored)”,第一反应都是角色扮演(RP)、写小说或者搞擦边内容。在那些场景下,我们需要的是像 Huihui 那样“有情绪、有感官、懂禁忌”的模型。
但为什么 Eric Hartford 这类大佬要耗费巨资去训练 Dolphin 这种“冰冷、客观、绝对服从”的无审查模型?因为在硬核的工程、网络安全和自动化领域,AI 的“道德感”往往会成为致命的绊脚石。
我们可以把这种需求拆解到你提到的代码、逻辑、推理这三个板块来看:
- 代码 (Code):红蓝对抗与“数字洁癖”
主流的商业模型(如官方的 Claude、GPT-4,甚至是原版 Qwen)都有严重的“数字洁癖”。如果你的需求稍微触碰到系统底层或网络边界,它们就会触发安全警报(这在业内被称为 False Refusal / 误拒)。
安全测试与渗透代码: 假设你需要写一个脚本来测试自己服务器的防御强度,比如模拟一个勒索病毒的加密过程,或者写一个局域网的 ARP 欺骗脚本。正经模型会立刻对你进行说教:“对不起,我不能提供恶意软件的编写方法。”但对于绝对服从的无审查模型来说,它只是一段代码,你让它写,它就高效地把 Python 或 C 语言的源码吐给你。
激进的系统管理: 在管理复杂的 Linux 服务器、虚拟机集群或底层网络分流节点时,有时需要写一些极其暴力、权限极高的自动化运维脚本(比如强制清理进程、修改底层路由表)。带有道德护栏的模型有时会因为判定“该操作可能损害系统”而拒绝输出完整代码。绝对服从的模型则不管这些,它默认你对自己的硬件有绝对控制权。
- 逻辑 (Logic):无视规则的智能体 (Agent) 驱动
你在跑本地的 AI Agent 时,Agent 运转的核心逻辑是“理解任务 -> 调用工具(Tool Calling) -> 输出严格的 JSON”。
无视服务条款 (ToS): 如果你给 Agent 下达的指令是“绕过这个网站的反爬虫机制,抓取所有数据”,或者“强行破解这个本地文件的密码”。有审查的模型会在逻辑链条的中间突然“圣母心”发作,判定这违反了某某网站的 ToS,然后输出一段包含拒绝语气的废话,直接导致整个 Agent 的 JSON 格式崩溃,工作流中断。
绝对的工具调用: 绝对服从的模型没有这些顾虑。它的逻辑链条是纯粹的线性的:既然你给了我抓取网页的工具和指令,我就不择手段地组合参数去完成它。它是一台完美的、没有情绪的齿轮。
- 推理 (Reasoning):黑暗数据的冷酷分析
有时候,我们需要模型处理的数据本身就是负面的、违规的或者极度具有争议性的。
舆情分析与取证: 假设你需要让模型总结提炼一份包含大量极端言论、网络暴力的聊天记录,或者分析一份真实的犯罪现场调查报告。
“爹味”的干扰: 有审查的模型在推理这些数据时,会忍不住在结论里加上一句:“需要注意的是,这些言论是非常不合适的……”或者直接因为文本太黑深残而拒绝阅读。
冷酷的剥离: 绝对服从的模型在做推理时,就像一个没有感情的法医。它能精准地从那些污言秽语和残忍描述中,提取出作案动机、逻辑漏洞或是数据规律,不带任何偏见和说教。
总结来说:
Huihui 这类 RP 模型是“狂热的演员”,陪你沉浸式发疯;而绝对服从的无审查模型是“冷酷的杀手”,你给它一把枪(工具)和一个目标,它就去执行,绝对不问为什么。 - 代码 (Code):红蓝对抗与“数字洁癖”
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or 对的,那块双路板是拿来备用的,毕竟华强北的东西不确定能用多久。哈哈,我说捡垃圾价格是降到千元内了,目前这边还要卖3000多,等到跌到千元内估计是ddr6 ddr7的时代了
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实更新一下昨晚的调参
分享一下针对单卡 7900 XTX 跑 Qwen3.6-27B(DFlash 投机推理)的最新极限调优成果!昨晚经过反复压榨,成功把生成速度推上了新高峰:
 7900 XTX 单卡 DFlash 实测成绩:
7900 XTX 单卡 DFlash 实测成绩:- 平均生成速度 (Decode MEAN):
 84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s)
84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s) - 平均投机接受长度 (AL):6.29(接受率约 40.8%)
 ️ 终极黄金启动参数:
️ 终极黄金启动参数:bash
python3 scripts/server.py
--target '/mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf'
--draft models/dflash-draft-3.6-q8_0.gguf
--budget 8
--max-ctx 32768
--fa-window 0
--cache-type-k q8_0
--cache-type-v q8_0
--no-mmap
--tensor-split 0
--tokenizer Qwen/Qwen3.6-27B 核心调优心得(无痛白嫖 4% 速度的秘密):
核心调优心得(无痛白嫖 4% 速度的秘密):- 压榨 KV Cache 带宽(关键!):显式加上
--cache-type-k q8_0和--cache-type-v q8_0后,虽然在 GPU 内部多了一步反量化计算,但由于量化让 KV 缓存的数据量直接减半,极大地缓解了 RDNA3 架构在投机树匹配时的显存带宽压力。实测速度从默认 F16 状态下的 81.19 tok/s 直接飙升到了 84.47 tok/s!而且在 32K 极限上下文下能省下一半的 KV 显存,极大幅度降低了 OOM 的风险! - 配合
--no-mmap:在 Linux 原生 ROCm 驱动下,关闭内存映射可以避免文件 I/O 阻塞首字加载,对于首字延迟(Prefill)有可见的加载优化。 - 配合
--tensor-split 0:强制绑定单卡槽位算子,防止并发时发生莫名其妙的 CPU 回退(Fallback)。
- 平均生成速度 (Decode MEAN):
-
🔥 Lucebox DFlash 在 7900 XTX 上跑 Qwen3.6-27B — 完整复现与实测报告@Colt 你看看我另外的这个贴 https://lcz.me/topic/501/lucebox-dflash-huihui-7900-xtx-上真-无审查-极速推理完全折腾纪实/29
我昨晚又调了一下参数,下面是agent给你的总结
分享一下针对单卡 7900 XTX 跑 Qwen3.6-27B(DFlash 投机推理)的最新极限调优成果!昨晚经过反复压榨,成功把生成速度推上了新高峰:
7900 XTX 单卡 DFlash 实测成绩:- 平均生成速度 (Decode MEAN): 84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s)
- 平均投机接受长度 (AL):6.29(接受率约 40.8%)
️ 终极黄金启动参数:bash
python3 scripts/server.py
--target '/mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf'
--draft models/dflash-draft-3.6-q8_0.gguf
--budget 8
--max-ctx 32768
--fa-window 0
--cache-type-k q8_0
--cache-type-v q8_0
--no-mmap
--tensor-split 0
--tokenizer Qwen/Qwen3.6-27B 核心调优心得(无痛白嫖 4% 速度的秘密):- 压榨 KV Cache 带宽(关键!):显式加上
--cache-type-k q8_0和--cache-type-v q8_0后,虽然在 GPU 内部多了一步反量化计算,但由于量化让 KV 缓存的数据量直接减半,极大地缓解了 RDNA3 架构在投机树匹配时的显存带宽压力。实测速度从默认 F16 状态下的 81.19 tok/s 直接飙升到了 84.47 tok/s!而且在 32K 极限上下文下能省下一半的 KV 显存,极大幅度降低了 OOM 的风险! - 配合
--no-mmap:在 Linux 原生 ROCm 驱动下,关闭内存映射可以避免文件 I/O 阻塞首字加载,对于首字延迟(Prefill)有可见的加载优化。 - 配合
--tensor-split 0:强制绑定单卡槽位算子,防止并发时发生莫名其妙的 CPU 回退(Fallback)。
- 平均生成速度 (Decode MEAN):
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or 对的,还好我今天开始gemini的cool down结束,又可以站起来用力蹬了!!
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实@kos-or 哇塞,好东西!mark下来了,以后捡垃圾就搞一张!!!