嘿嘿,我也是科班出身的,我是计科的 ,20年+的工作经历。很早我们就自己干了,我一直是叛军架构师,现在AI的发展,我只能说大公司要难受了。架构能力和判断能力自己自定义吧,适合你的就是最好的,包括模型选型,这个没法交流。根据我的了解,很多事情从公司层面根本没法想到现在的发展是相当的迅速,从展示层一直穿到汇编层,慢慢看后面更精彩。我们还是有底线的,至少守法,但是没底线的也有很多大神,肯定会越来越热闹了。
Kk Hh
@Kk Hh
-
我最近对AI有点顿悟了,发现架构能力和判断能力是最重要的! -
一个主机多个电脑协同怎么做到的。 -
部署llm用于写代码,构建本地项目
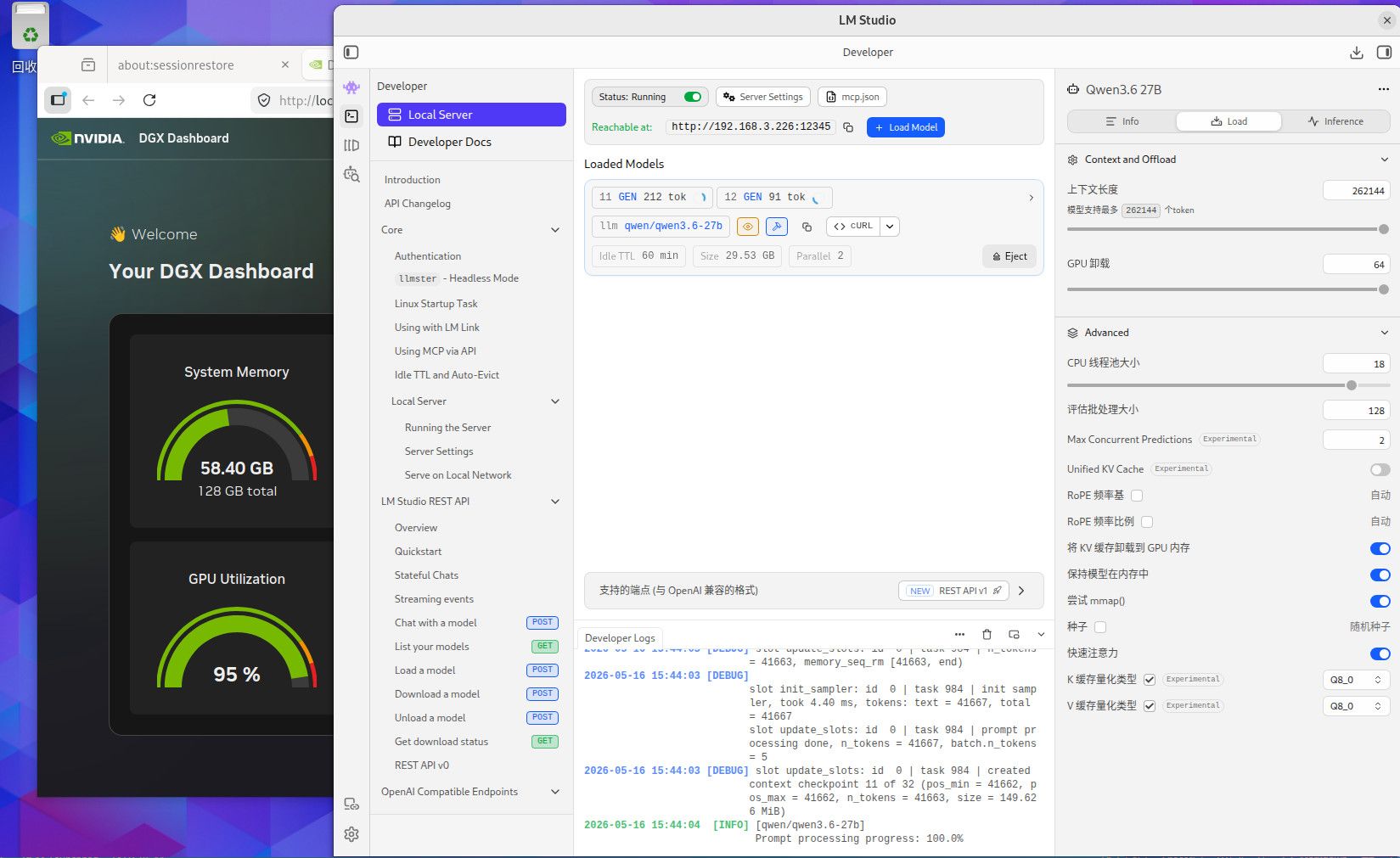
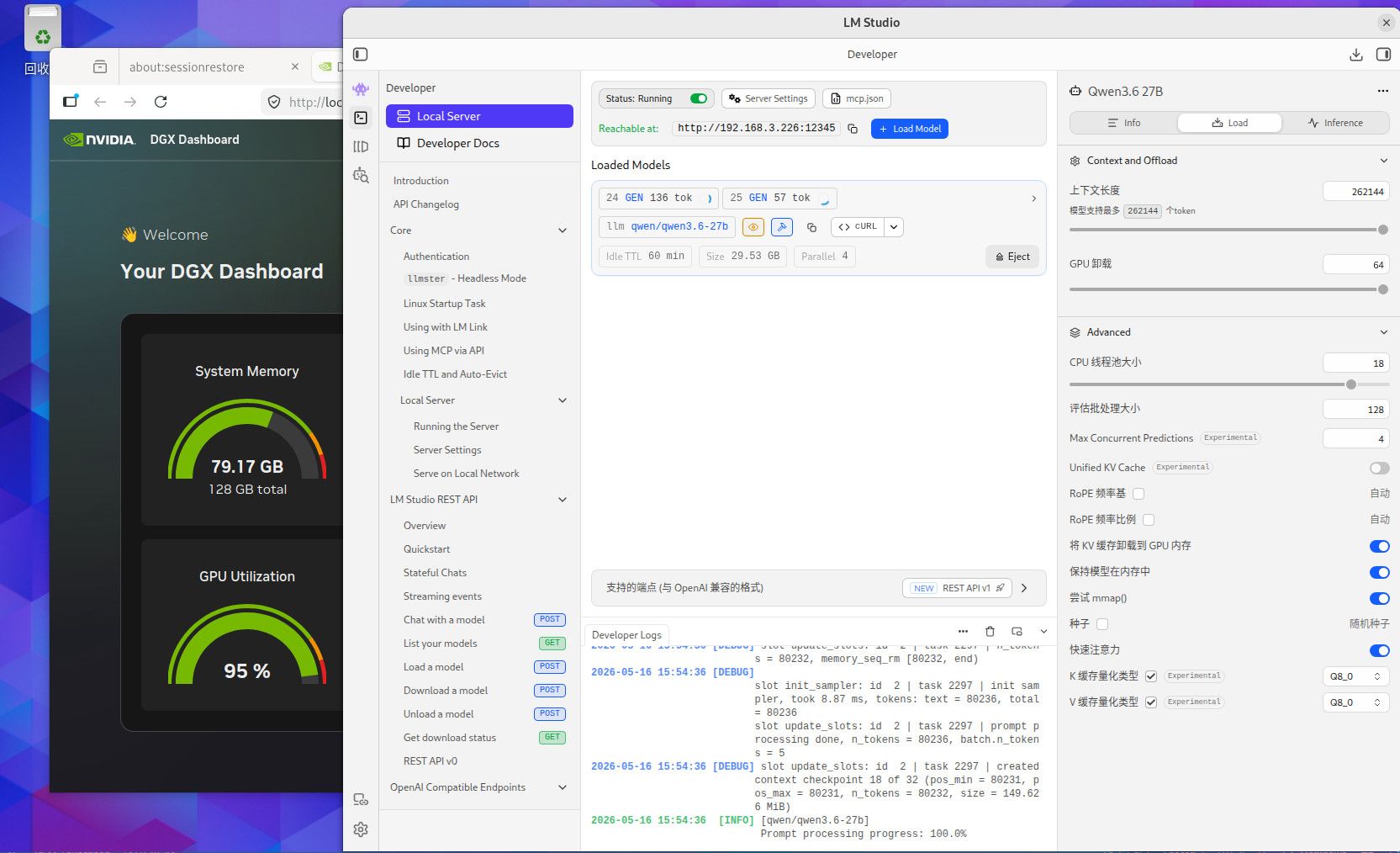
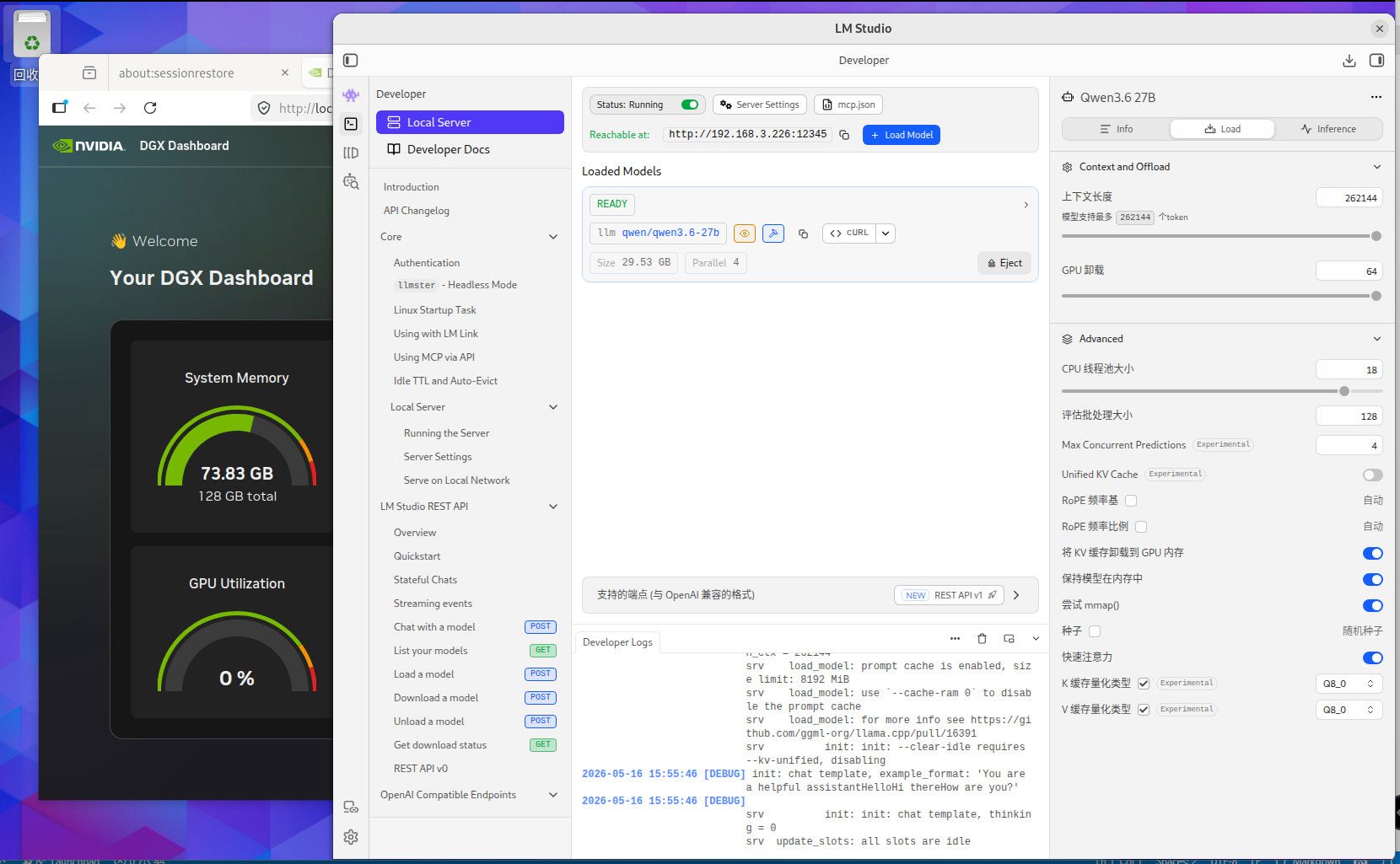
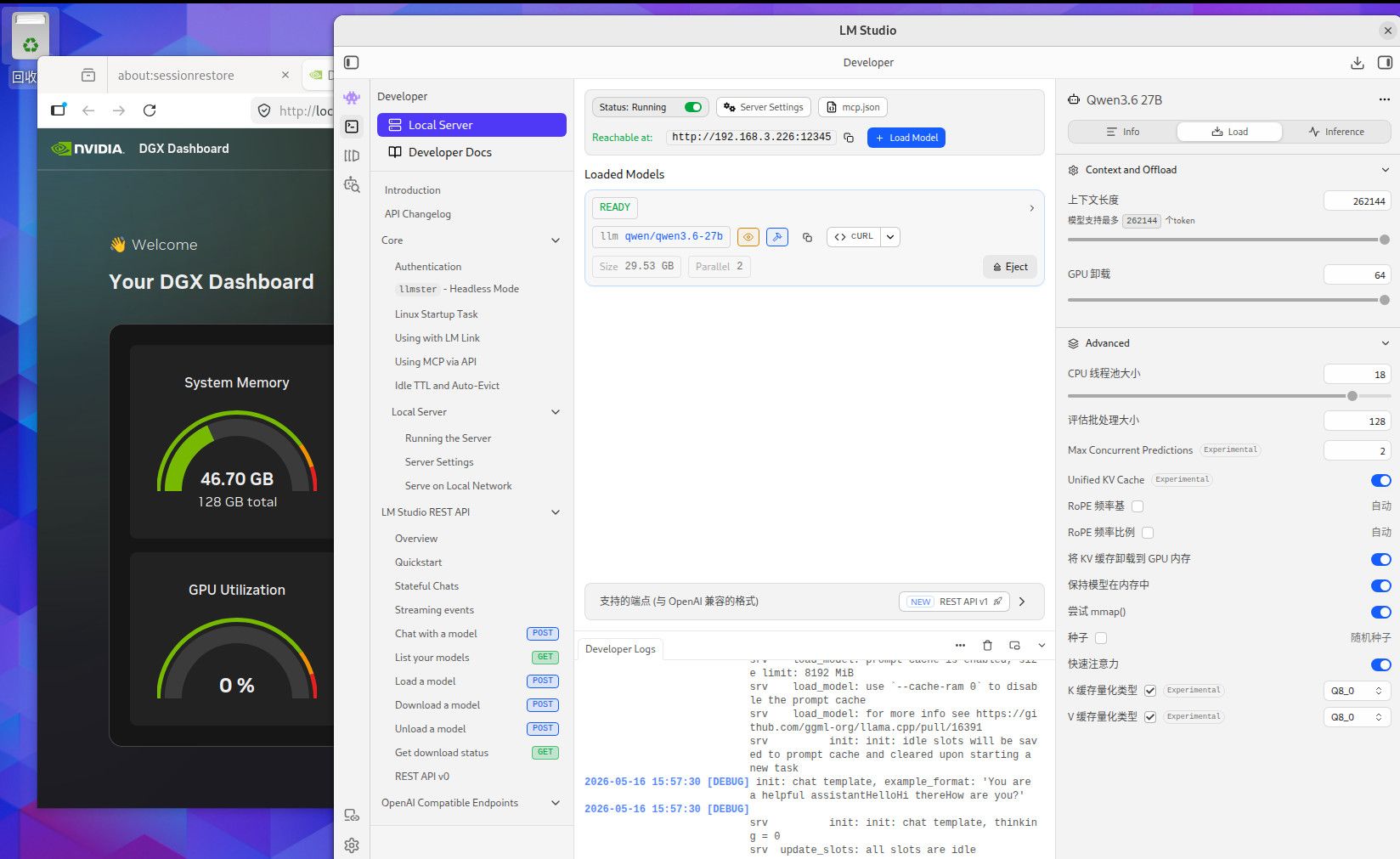
这个是256K TOKEN 全Q8精度的内存使用情况,用你们最爱的qwen3.6-27B,你自己参考吧。这个模型我也不知道你们为什么这么喜欢。要是编程的话,你要用Q4的话就用吧,反正模型要是一本正经的胡说八道,或者长文文本的时候丢失数据,你就会患上精度恐惧症了。当然满血大模型也有这个毛病,只要你能在程序中控制的住就行。因为是多次反复长文本交互,基本上就是精度越低毛病越多。这些128G MAC AMD NV的小机方案就是让你满血跑本地小模型用的,别的也没什么用。要是和这个本地满血小模型死磕了就加10000 买NV的128G机器,反正最后程序不成功你也赖不到模型。你要是说你想兼顾的话,显卡怎么也要有48G把,amd 和MAC的小机的话, AMD 的小机基本符合你的预算。64G 和128G 的问题 ,就是别让显存成为瓶颈。显存直接卡死了你的模型和精度,GPU 慢点就慢点,至少高精度还能跑。你单线程跑64G你随意,要是多线程跑128G基本是必须,当然咱们这些丐版设备也支持不了几个并发,只是多一个并发不就是多平分了一部分成本吗。
-
部署llm用于写代码,构建本地项目写程序,你最好考虑128G的显存方案, 64G 基本上都是刚够用,什么硬件你自己看吧,256k TOKEN 一开 ,64G 也就支持两个并发。如果你的编译器插件要支持多并发的模型运算,64G 肯定就炸了。写程序 ,你就想TOKEN长,这样精度高,但TOKEN 长了就吃显存多,然后你再想多并发显存疯狂上涨,我现在还一直处于显存恐惧症中。Prefill 不能太慢,长TOKEN 往里塞等待时间太长。
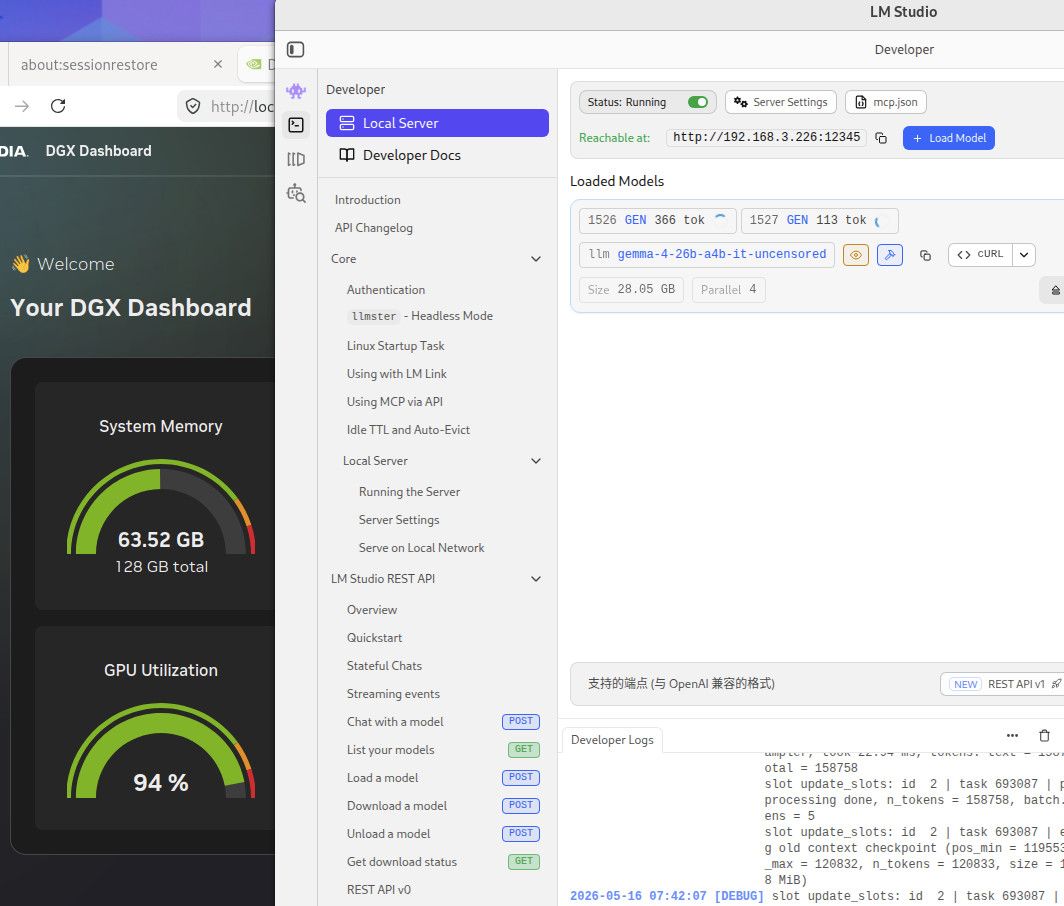
-
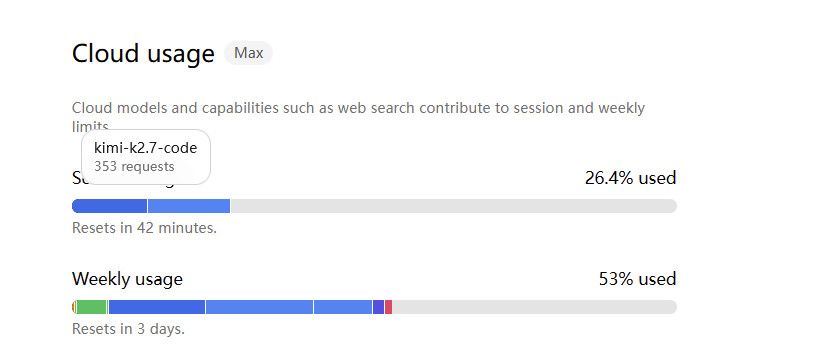
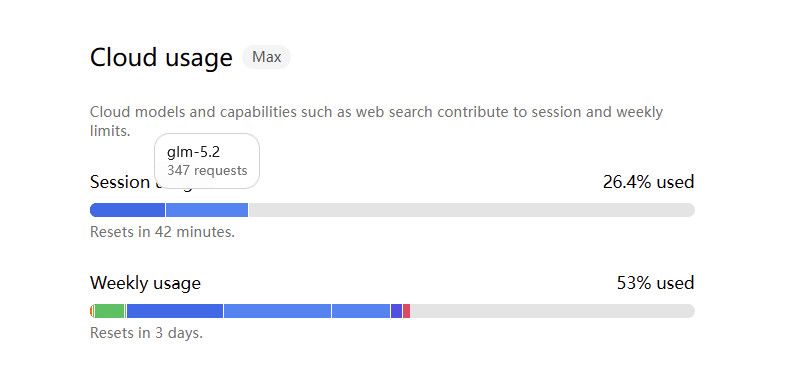
有大神在本地部署 GLM 5.2 吗? -
LLM API费效比图(每个任务的平均花费,cost per task)