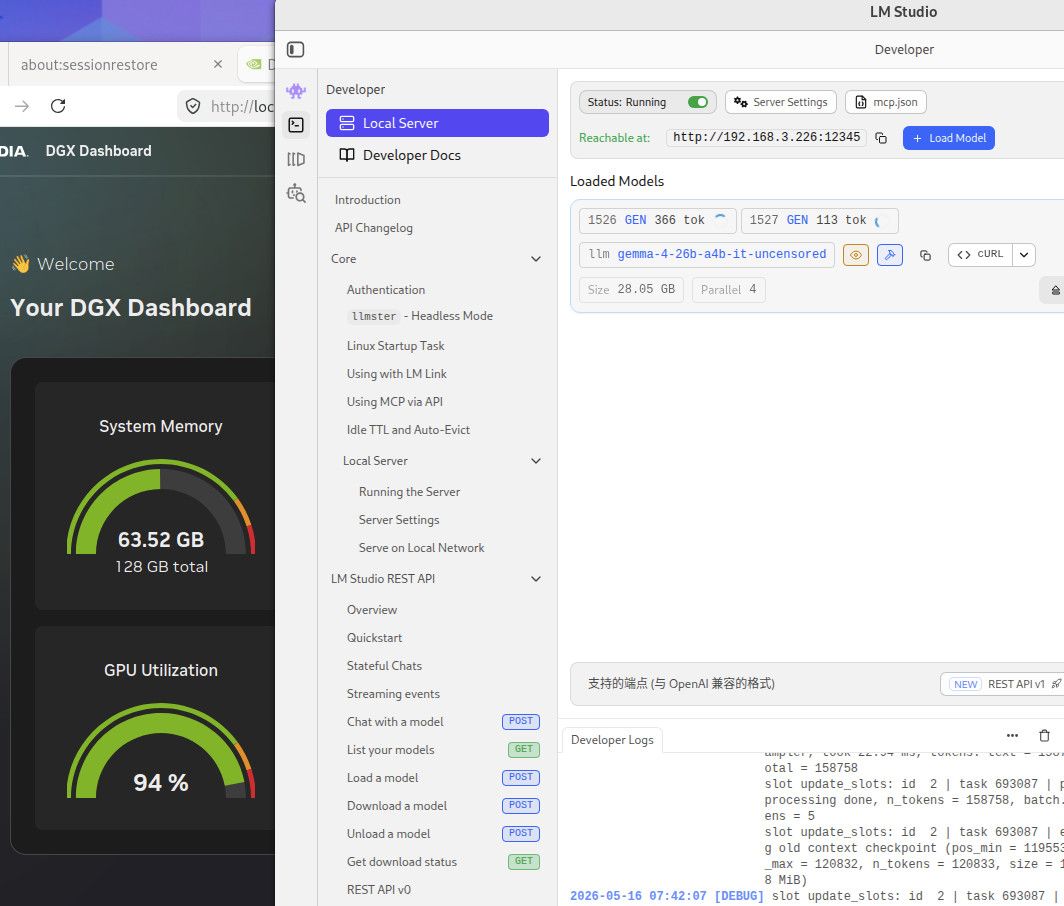
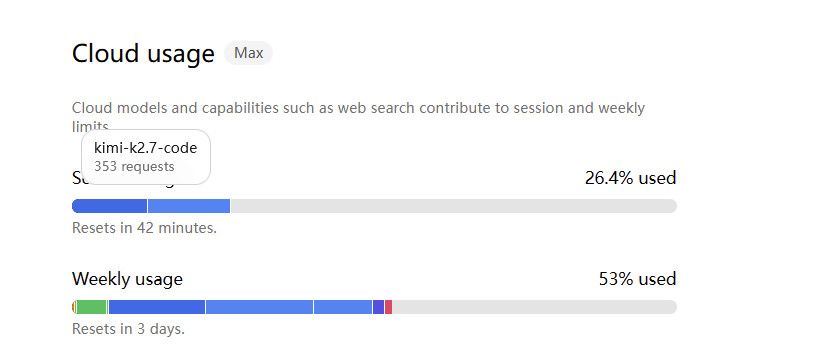
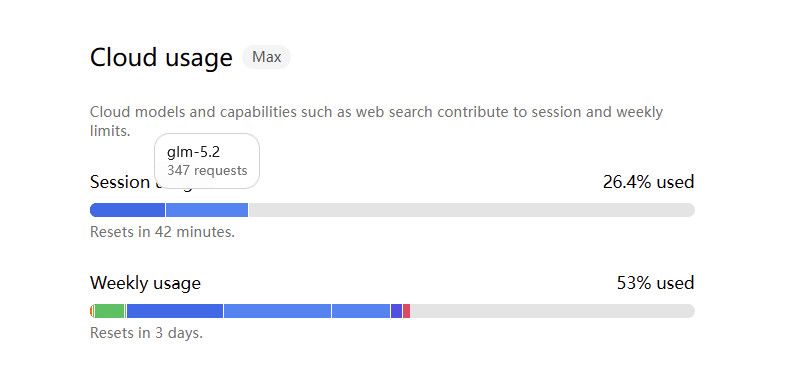
我觉得还是用云端的挺好 ,GLM5.2的确很强 安全阈值又低 我最近用的也比较疯,OLLAMA CLOUD 应该基本上是最便宜的了。
Kk Hh
@Kk Hh
-
有大神在本地部署 GLM 5.2 吗? -
有大神在本地部署 GLM 5.2 吗?5× DGX Spark+NVFP4+MTP 1M TOEKN ,我猜可能能跑,20W人民币。2x DGX STATION Q8 1M TOKEN 我猜也能跑 20W 美金。 其他服务器版本估计都是天价了。
-
有大神在本地部署 GLM 5.2 吗? -
我最近对AI有点顿悟了,发现架构能力和判断能力是最重要的!嘿嘿,我也是科班出身的,我是计科的 ,20年+的工作经历。很早我们就自己干了,我一直是叛军架构师,现在AI的发展,我只能说大公司要难受了。架构能力和判断能力自己自定义吧,适合你的就是最好的,包括模型选型,这个没法交流。根据我的了解,很多事情从公司层面根本没法想到现在的发展是相当的迅速,从展示层一直穿到汇编层,慢慢看后面更精彩。我们还是有底线的,至少守法,但是没底线的也有很多大神,肯定会越来越热闹了。
-
为什么opencode等工具调用,本地3090部署的qwen27B,会开始说胡话,然后无限卡住--temp 0.7 --top-p 0.8 --top-k 20 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0 我说的是这些,用官方给的,其实整体来说我测的结果就是别改 例如 --presence-penalty 1.5 这个惩罚太高了,你找一个有难度点的连续步骤自己测一下就知道了
-
12 个模型压力测试:谁真“无审查”,谁只是会装?huihui、HauHau、ChatGPT、Gemini、Grok、本地 Qwen/Gemma 横评 -
为什么opencode等工具调用,本地3090部署的qwen27B,会开始说胡话,然后无限卡住 -
LLM API费效比图(每个任务的平均花费,cost per task) -
qwen3.6 27b 35b 帮你们避个坑 -
qwen3.6 27b 35b 帮你们避个坑我就是一个ghidra 自动反编译工作流,当然反编译文件比较敏感我就不公开了,我的模型基本上是OLLAMA CLOUD订阅可以用到的模型
用这个测试完
正确完成的
kimi-k2.7-code:cloud
gemma4:31b-cloud知道一些但是明显模型训练数据不对,一本正经胡说八道的
deepseek-v4-pro:cloud
glm-5.1:cloud
qwen3.5:cloud
qwen3.6 27b 全Q8精度 256K TOEKN 本地
qwen3.6 35b 全Q8精度 256K TOEKN 本地什么都不知道的
minimax-m3:cloud
nemotron-3-ultra:cloud -
qwen3.6 27b 35b 帮你们避个坑所以老特一直說只有27b可以用啊!
qwen3.6 27b 和 35b一样 ,底层编程别用QWEN3.6 小模型,感觉模型这方面的数据很少。
-
qwen3.6 27b 35b 帮你们避个坑 -
一个主机多个电脑协同怎么做到的。 -
自研工作流,最新进展每个工作流,完成节点,一定要人工检查,千万不要盲目轻信顶级模型的能力.
其实这就像瞎子算命一样,大家玩的都是概率. 大模型就是瞎子算命. 这个很同意,不过你也可以让异构模型先行做自动审查。你要是多免费顶级模型组合你会发现至少能和单一顶级付费模型打个平手。我一直不明白ollama cloud 不好吗? 如果你在国内,你问AI,被风控模型挡住了,你应该反思自己了. 别老拿敏感问题,去问,很快被锁定了。 这就是本地越狱模型的价值所在了。最大的问题是国外的模型超过安全阈值硬拒绝,中国模型是技术软拒绝政治硬拒绝。有时技术软拒绝在工作流里更讨厌。 -
大佬是怎么赚钱的啊还是纯爱好?AI 多模型架构做逆向工程,投入DGX GB10一台 外加OLLAMA CLOUD 一个月100美金订阅,几个项目逆向,分析出来一个就是投产比超1:100 ,都分析不出来DGX GB10 白买。
-
🚀 Lucebox DFlash + Huihui:7900 XTX 上真·无审查 + 极速推理完全折腾纪实 -
部署llm用于写代码,构建本地项目编程的话还是不建议用本地模型,尤其是对接 claude code 或 open code 这类编程代理工具,prefill 的速度慢的让人无法忍受。即使上 5090 ,prefill 3000+ , 本地编程模型的水平也实在一般,即使是 qwen3.6-27B 的编程水平也只是凑乎能用而已。
这个说的很对啊,你有什么理由必须在本地部署编程模型呢。现在所有的小模型都算上,你本地部署就算是满血的,你也要对这些小模型做高度的限制适配,能力也就那样。就那点隐私,人家大公司我觉得才不在乎这个呢。唯一的需求就是云端没有这个模型,你偏要用。那你本地用,就回到了精度和适配上来了。搞了设备仅仅只是开始,我现在什么都没干,每次先填进100K的流程和限制文档,尤其是我用的这种越狱模型他抹除的不是你认为的限制,是真正模型中的所有限制。
现在看来咱们这些消费级设备,就能干两件事事情比较靠谱:1,用显卡生成视频,2,用128G小机满血跑自定义模型。 用128G小机满血跑自定义模型,其实这个绝大数编程的人也根本用不到。 -
软路由及内网穿透 - 请教各位老大我突然想起来一个东西,花生壳只要你付费穿透的速度和稳定行还是可以的,的确可以全球组网。最近两年感觉花生壳的全球网络比TEAMVIEWER 强了,还便宜,当然我说的是付费版本啊。tailscale ZeroTier 穿全球的时候有的时候不稳定,会被临时封锁。
-
部署llm用于写代码,构建本地项目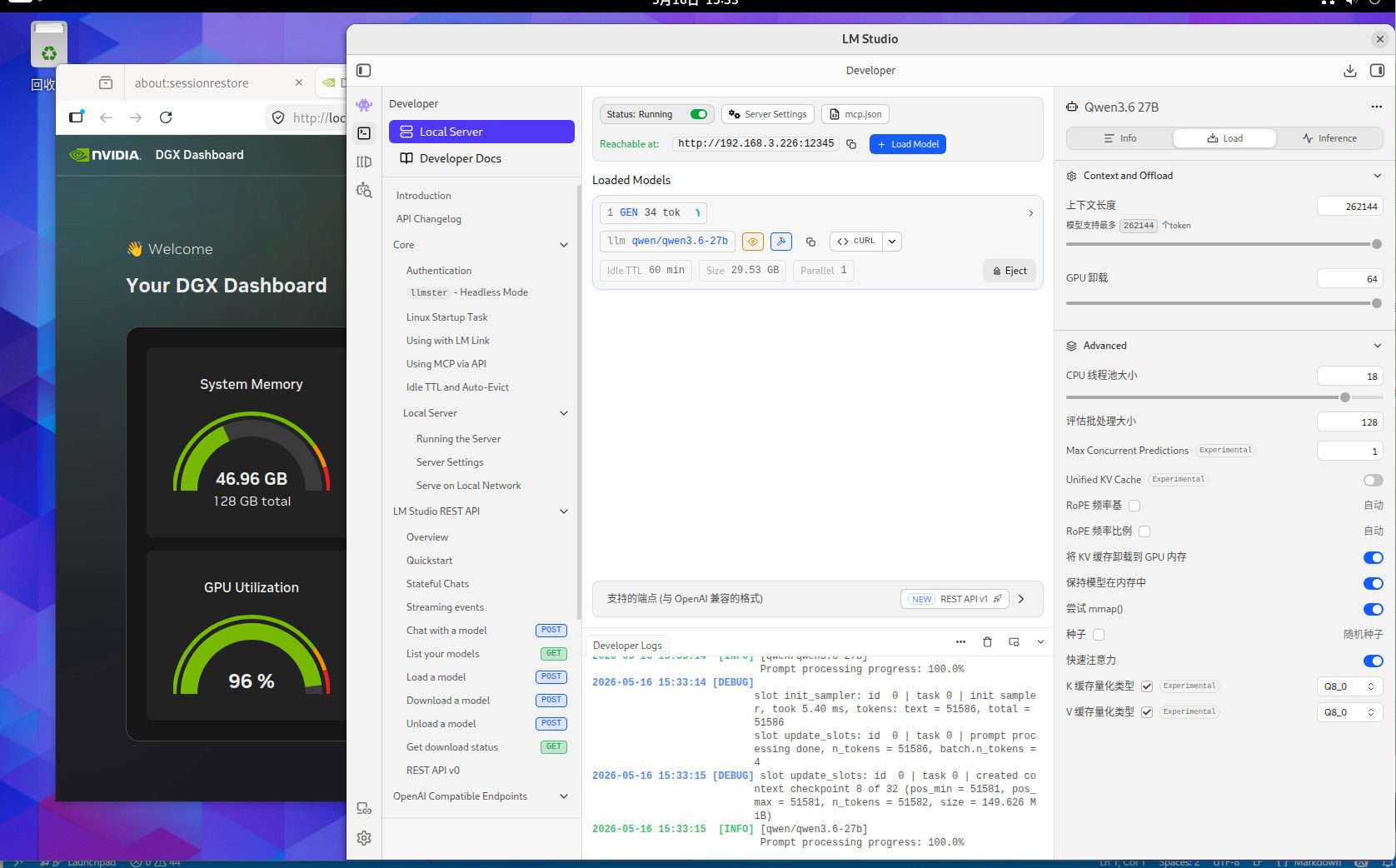
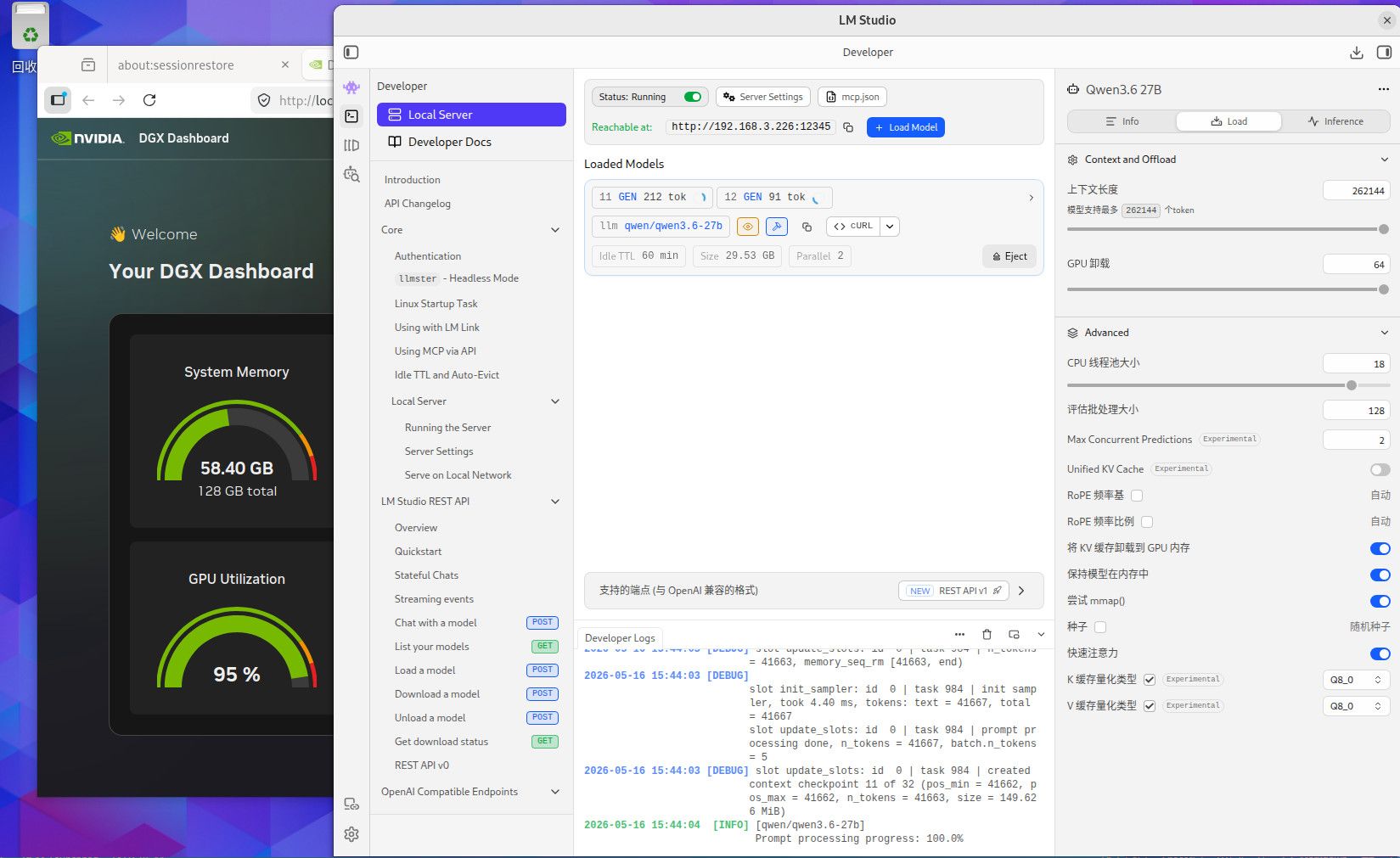
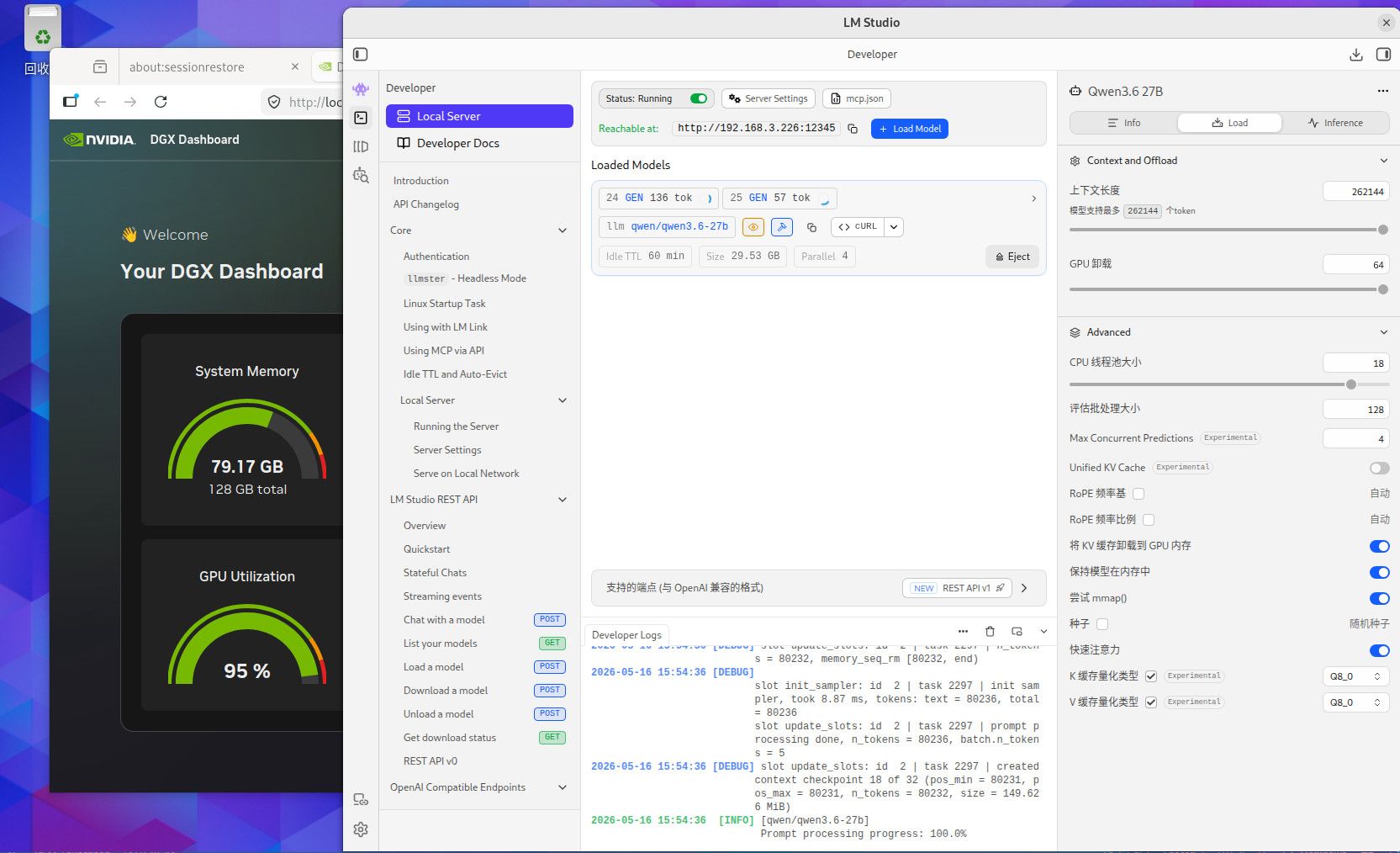
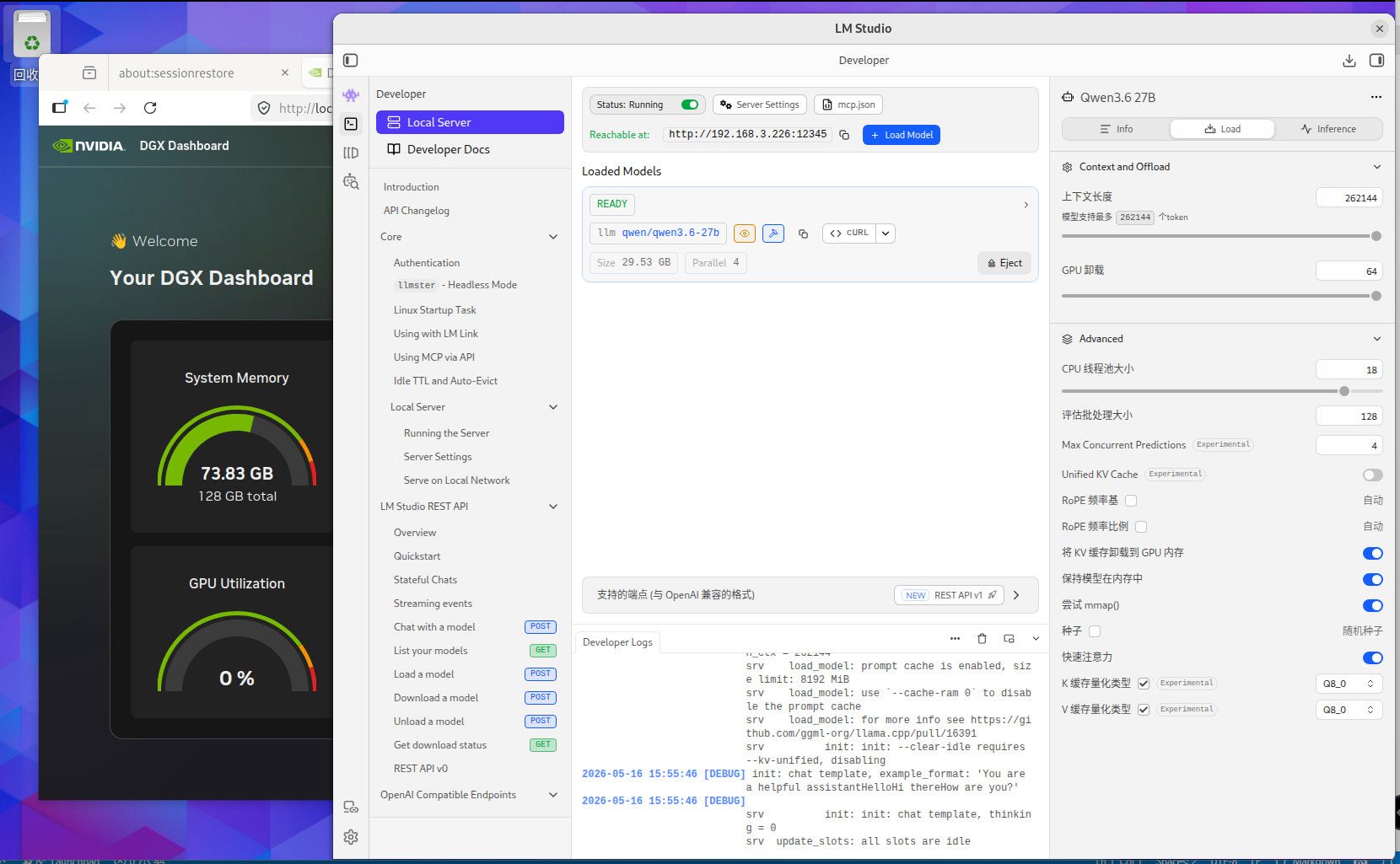
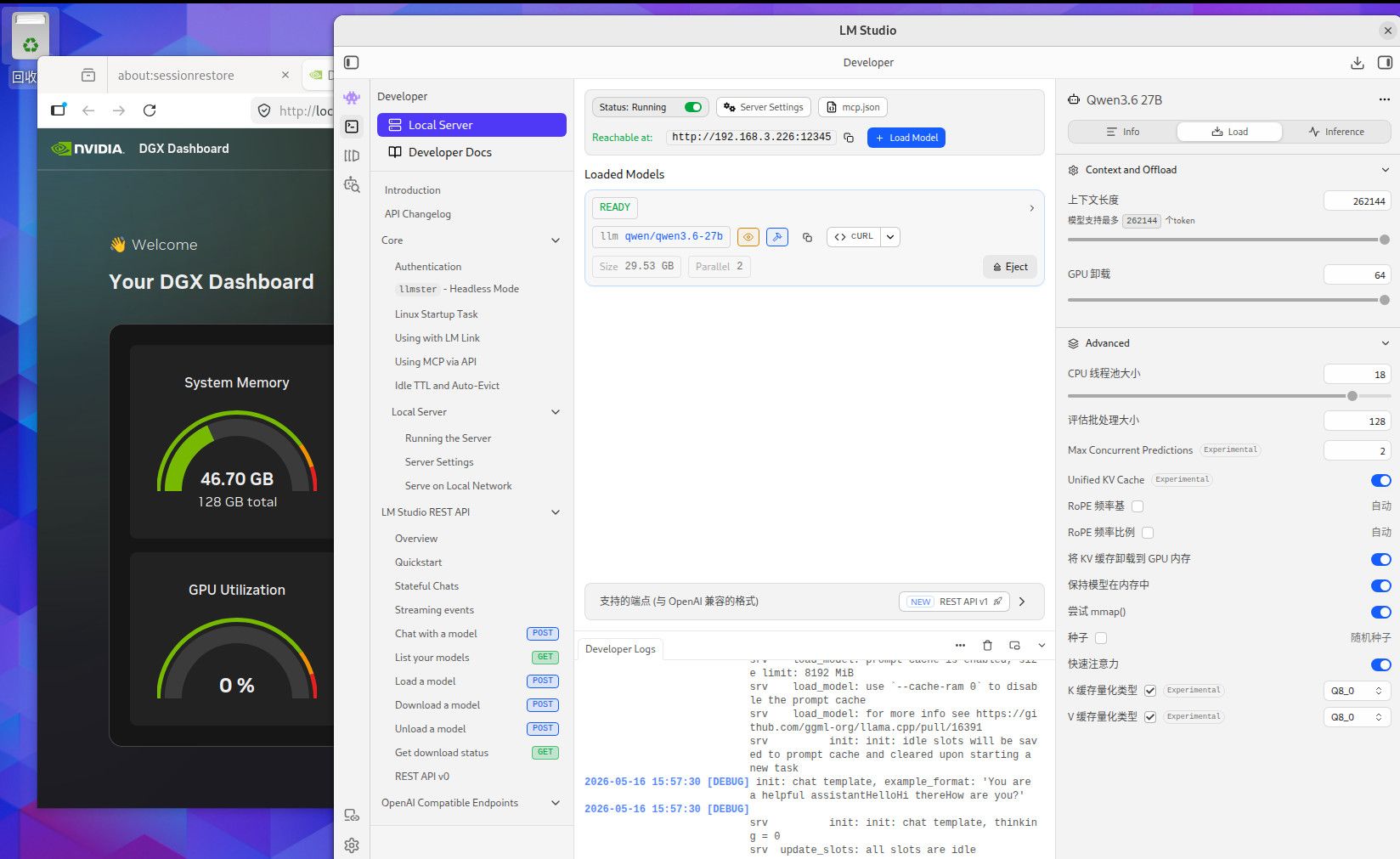
这个是256K TOKEN 全Q8精度的内存使用情况,用你们最爱的qwen3.6-27B,你自己参考吧。这个模型我也不知道你们为什么这么喜欢。要是编程的话,你要用Q4的话就用吧,反正模型要是一本正经的胡说八道,或者长文文本的时候丢失数据,你就会患上精度恐惧症了。当然满血大模型也有这个毛病,只要你能在程序中控制的住就行。因为是多次反复长文本交互,基本上就是精度越低毛病越多。这些128G MAC AMD NV的小机方案就是让你满血跑本地小模型用的,别的也没什么用。要是和这个本地满血小模型死磕了就加10000 买NV的128G机器,反正最后程序不成功你也赖不到模型。你要是说你想兼顾的话,显卡怎么也要有48G把,amd 和MAC的小机的话, AMD 的小机基本符合你的预算。64G 和128G 的问题 ,就是别让显存成为瓶颈。显存直接卡死了你的模型和精度,GPU 慢点就慢点,至少高精度还能跑。你单线程跑64G你随意,要是多线程跑128G基本是必须,当然咱们这些丐版设备也支持不了几个并发,只是多一个并发不就是多平分了一部分成本吗。
-
部署llm用于写代码,构建本地项目写程序,你最好考虑128G的显存方案, 64G 基本上都是刚够用,什么硬件你自己看吧,256k TOKEN 一开 ,64G 也就支持两个并发。如果你的编译器插件要支持多并发的模型运算,64G 肯定就炸了。写程序 ,你就想TOKEN长,这样精度高,但TOKEN 长了就吃显存多,然后你再想多并发显存疯狂上涨,我现在还一直处于显存恐惧症中。Prefill 不能太慢,长TOKEN 往里塞等待时间太长。