
买了2张5060Ti,谁能跑最便宜的Qwen 27B?
-
-
@terry 我有张改的4090散热器的TESLA V100 32G,想问下能不能跑本地QWEN3.6 27B?
-
@terry OK ,谢谢,马上处理掉
-
@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
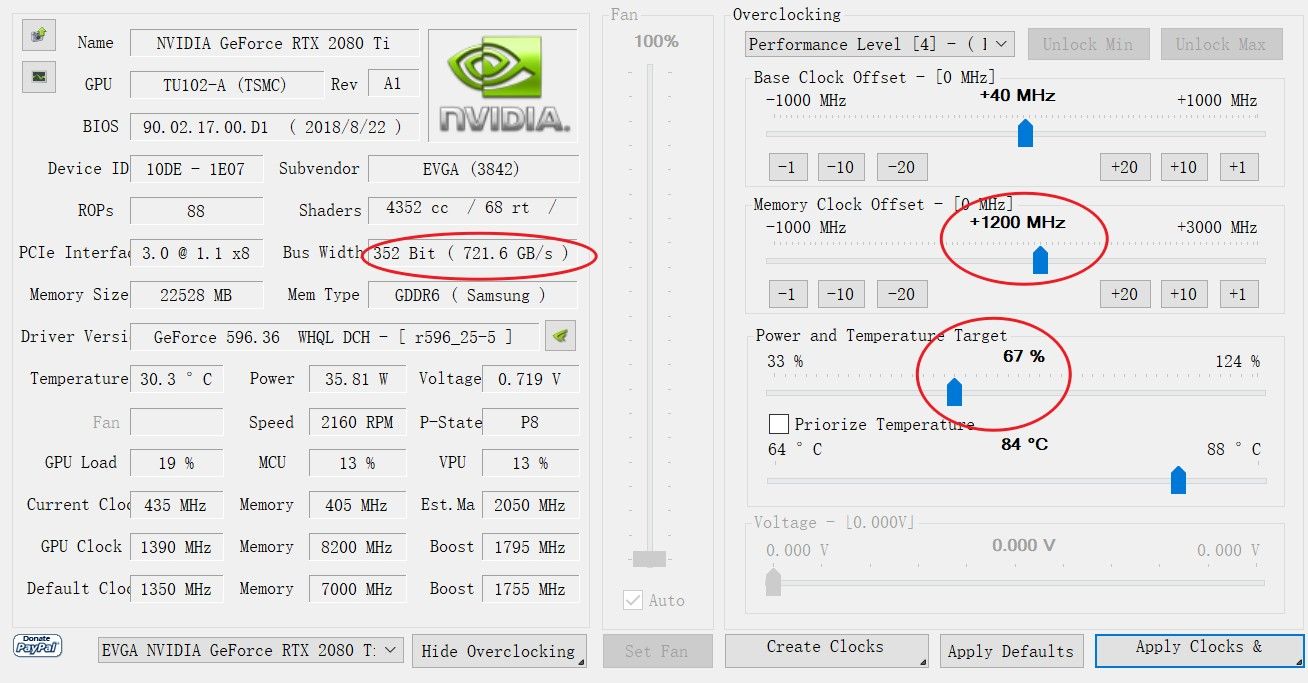
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:

核心超频+40Mhz,显存超频+1200Mhz:

核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:

大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。 -
小白如果要即插即用,兩張5060TI 16G 插X99,用windows LMstudio,直接載QWEN3.6 27B Q4KM,KV Q8量化,可以拉到120k context,速度大概18token/s。以上是個人親測,屬於可用的程度。
-
卡终于到货。等到天荒地老..。
马上把双卡插进去,测试.历尽星霜岁月长, 天荒地老守3090。
苍天有眼怜痴客, 5060Ti双剑合璧试锋芒!觉得很可以用。用电少。不发热 ~ MTP TG 50 t/s

通常可以跑到30 tk/s. 用 Q6_K Ctx 96k 比 Q4_K_M Ctx128k 还快.
LM Studio Split:
3090:

5060Ti:

Q6_K 96k 显存几乎用满了
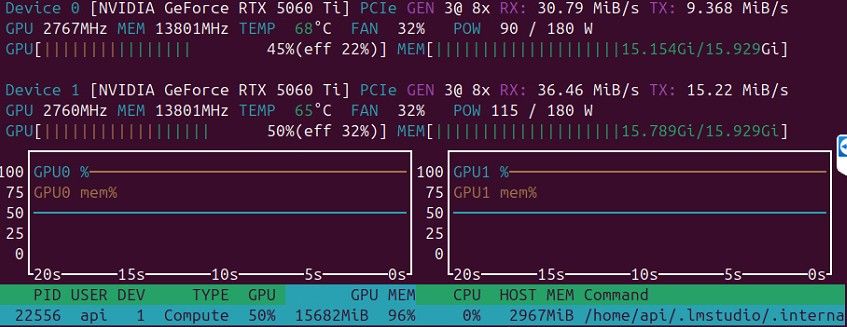
-
双5060TI 16G跑英伟达专门为50显卡优化的Qwen3.6-27B-NVFP4-MTP的表现比双3080-20G还好,NVFP4的优化号称无损Q4,速度40-70T,论坛里面有人发的。
-
MTP 版本需要設一個參數 Draft tokens (num_speculative_tokens or spec-draft-n-max): AI 幫我測試過 最後1 或 2 是最快的參數, 你也是設定1 或 2 嗎?2 速度只比1 快了3 tokens /s 但是它有一個"準確度" 降了很多(浪費算力) 我跟AI都認同Qwen3.6-27B-MTP-GGUF 最後選擇1 是最佳MTP參數

