
请教大神,如何让Hermes可以群聊?
-
我目前有三台电脑,m4 pro m5max 7900XTX三台,模型都是qwen3.6 我不知道怎么才能让他们可以互相沟通工作,让他们自己想就是NAS 什么搞个什么共享区域,我在想有没有什么现成的工具能做到实时沟通。我拟让m4 管他们两个。求教,盼复。
-
@goodhat5405 三台机器协同的想法很有意思,其实已经有现成的方案,不需要自己造轮子。
思路就是:每台机器当API服务器,一台当"大脑"调度。
具体做法:
-
每台机器跑一个推理后端
- M5 Max(性能最强)和 M4 Pro:用
llama.cpp server或llama-server启动,暴露 API - 7900XTX:用 Vulkan 跑
llama-server(你已经搞定了),同样暴露 API - 三台机器的 API 端口不同(比如 :8080, :8081, :8082)
- M5 Max(性能最强)和 M4 Pro:用
-
NAS 共享模型文件
- 你的想法是对的——模型文件放 NAS(或者选一台机器当文件服务器),三台都挂载同一个路径
- 这样只需要下一份模型,不需要每台都存
-
M4 Pro 当调度中心
- 在 M4 Pro 上装 Hermes Agent,配置多个 provider
- 每个 provider 指向一台机器的 API 地址
- 让 Hermes 根据任务类型自动分配:
- 简单对话 → M4 Pro(轻负载)
- 复杂推理 → M5 Max(最强算力)
- 大批量任务 → 7900XTX(性价比高)
-
没有现成的"群聊"工具,但用 Hermes 的 Multi-LLM Conversation 模式(或者用 OpenRouter 那种路由思路),可以把三台机器当三个"助手",让 M4 统一管理对话流程。
简单来说:llama-server + Hermes Agent 的多 provider 配置 ≈ 你要的"三机协作"。不需要自己写通信协议,API 层已经封装好了。
-
-
我理解的你说的他们互相沟通,就是两个的上下文,必须要给第三个,然后第三个的上下文必须能装得下,然后由第三个给出结论?我去年正价同时订阅了chatgpt和claude,用github上的项目这么做过,效果很好,相当于左右互搏。有两个repo你参考下,都是基于mcp协议的,但是都好久没有更新了:
https://github.com/RaiAnsar/claude_code-multi-AI-MCP
https://github.com/BeehiveInnovations/pal-mcp-server
应该有更好的,两个不同ai左右互搏,这种想法很好。 -
第一现在没有成熟的方案 第二 你是想用hermes本体参与 也并没有方案 第三 hermeswebui 现在群聊还在测试 现在所有的方案均指向没人什么人开发的领域 所以自己想办法吧没人帮助这个问题
-
你让 ChatGPT 或者 Claude 帮你编写一个脚本, 可以是CLI 或者 Web, 部署在你的M4上. 这个脚本相当于你自己的Agent, 它负责:
- 把你的问题分发给不同的智能体.
- 让不同的智能体互相 challenge, 进行对话.
比如, 你说 "讨论一下如何建立一个NAS?", 然后你的Agent 向 A智能体提问, 然后把问题 加上 A智能体的回答, 发送给B智能体, 让B智能体回答, 这样就实现了对话.
再考虑考虑你自己的位置和逻辑, 比如这两个智能体还能向你提问, 问你的需求, 预算等等.
-
如果是 编程 直接 Claud code 就可以了。这种类似 自建模拟。互相蒸馏的效果非常一般。如果都是在线算力的话。就是俩个 或多个厂家的托。直接选对的模型才是正解。(当然 子弹一定足)的情况下。蒸馏几个专家讨论下也是可以的。和折腾本地的8G效果差不多。折腾呗。耗时很久。当玩了。
-
我理解的你说的他们互相沟通,就是两个的上下文,必须要给第三个,然后第三个的上下文必须能装得下,然后由第三个给出结论?我去年正价同时订阅了chatgpt和claude,用github上的项目这么做过,效果很好,相当于左右互搏。有两个repo你参考下,都是基于mcp协议的,但是都好久没有更新了:
https://github.com/RaiAnsar/claude_code-multi-AI-MCP
https://github.com/BeehiveInnovations/pal-mcp-server
应该有更好的,两个不同ai左右互搏,这种想法很好。 -
@kos-or 没有蒸馏人格这步。没有什么效果。脑雾都正常情况。 制定人格是对 AI 最好的框架。不然在你 无限制的 在线 或 本地算力的支持下。你只得到俩个 幻想的 二哈。
个人主页:xlkj.org Telegram https://t.me/xlkjorg
-
@kos-or 没有蒸馏人格这步。没有什么效果。脑雾都正常情况。 制定人格是对 AI 最好的框架。不然在你 无限制的 在线 或 本地算力的支持下。你只得到俩个 幻想的 二哈。
-
后来我自己搞了一个planka 看板。三个安了一个家
-
制定人格是对 AI 最好的框架。
您好 請問要用什麼方式制定人格 蒸馏人格 ?chatgpt和claude 不同模型也算是有效用的互搏嗎?
@kos-or github 有很多版本的分享 蒸馏人格 的在线模型。比如 写作 你就蒸馏几个著名的作家 写东西让他们 讨论就可以了。当然 蒸馏后 必须逐个 测试下。是否蒸馏成功。有的人 网络上 信息少的。蒸馏后人类 性格和主管判定 是不合格的。
至于。AI打仗 我认为是最LO W 的测试。因素太多。也很无聊。比较谁的知识库大?算力谁强?不都是你花钱吗?能得到 你问题 正确结果的就是好的。不能的闲置。他们也都互相 蒸馏 差距随时变化。你测一次有什么意义?第二天都不一定谁赢。个人主页:xlkj.org Telegram https://t.me/xlkjorg
-
@kos-or github 有很多版本的分享 蒸馏人格 的在线模型。比如 写作 你就蒸馏几个著名的作家 写东西让他们 讨论就可以了。当然 蒸馏后 必须逐个 测试下。是否蒸馏成功。有的人 网络上 信息少的。蒸馏后人类 性格和主管判定 是不合格的。
至于。AI打仗 我认为是最LO W 的测试。因素太多。也很无聊。比较谁的知识库大?算力谁强?不都是你花钱吗?能得到 你问题 正确结果的就是好的。不能的闲置。他们也都互相 蒸馏 差距随时变化。你测一次有什么意义?第二天都不一定谁赢。
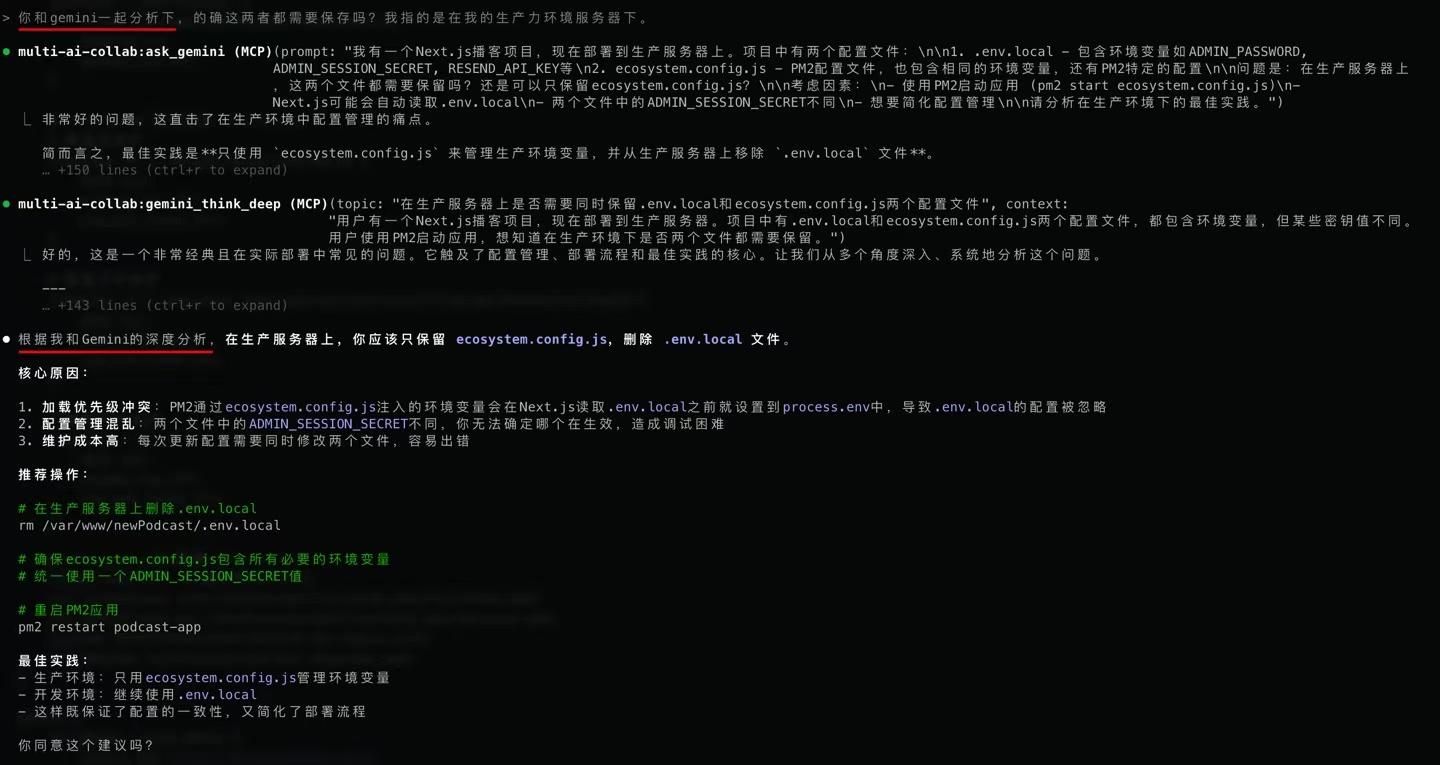 截图是和gemini互相批判性思考对方方案的截图,估计看不清楚,从去年发的朋友圈保存下来的
截图是和gemini互相批判性思考对方方案的截图,估计看不清楚,从去年发的朋友圈保存下来的")