
@Rex 一片qwen3.6 27b ,一片comfyui
-
看目前這社區越來越多人買7900XTX了,大家為了一個爽度token無限發與反應速度,這幾天折騰的過程分享給大家(win11+vulkan & ubuntu +rocm) -
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@AGI 但我爬文好像是可以合理用耶因為,codex grok都能用這方式接,我目前是沒什麼問題,繼續試水
-
回归第一帖,说说最近忙啥了!推推!!有這裡這好~~!
-
Hermes 接入 Codex OAuth、串 Telegram 與本地 Qwen 實戰筆記 (chatgpt plus可調用API給hermes)本文新增接gemini pro訂閱額度給herems調用的簡單教學,這樣一來有codex,gemini 輪流調用
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@566656661 了解了,謝啦話說你也是台灣同胞,是不是可以多認識交流~~~私訊一下
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@566656661 我看這次能接,是因為用了hermes agent更新的OpenAI-compatible local proxy,我感覺應該算是合法使用了耶!!因為每一種都可以,hermes好像前一兩個月更新的,Google OAuth / Antigravity
↓
CLIProxyAPI 本機代理
↓
http://127.0.0.1:8317/v1 OpenAI-compatible API
↓
Hermes custom provider我本機有claude codex codex也順便接上去了,超方便,以後qwen3.6 26b跑不通的時後切一下模型就可以幫他把skill做好,之後qwen順跑
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面我太菜了,終於用好,把gemini pro訂閱額度接給herems用,分享一下,給新手服用,同理如果你有訂閱chatgpt plus , claude code pro,grok訂閱,都可以用同一種方式,這是hermes agent本身框架支援的,並不會被鎖帳號!
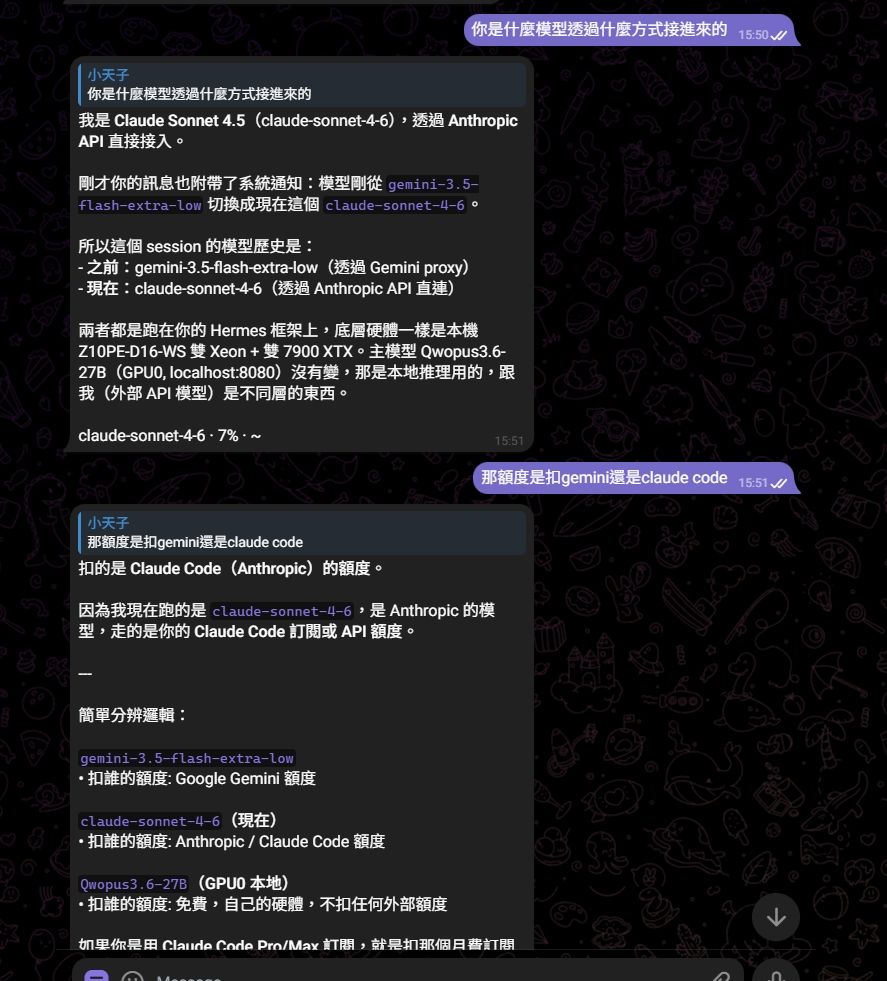
Hermes Agent 接 Gemini Pro 訂閱 OAuth:不是 MCP,是本機 OpenAI-compatible Proxy
這篇記錄我這次把 Gemini Pro 訂閱帳號接進 Hermes Agent 的做法。
先講結論:這條路線不是用 Hermes 的 MCP,也不是只讓 Hermes 去呼叫
agyCLI。實際跑通的是:Google OAuth / Antigravity ↓ CLIProxyAPI 本機代理 ↓ http://127.0.0.1:8317/v1 OpenAI-compatible API ↓ Hermes custom provider也就是把 Gemini/Antigravity 的 OAuth 能力包成一個本機
/v1API,Hermes 再把它當成 OpenAI-compatible provider 使用。成功後的狀態
本機跑起來後會有兩個重要服務:
127.0.0.1:8317 CLIProxyAPI,負責 Gemini OAuth proxy 127.0.0.1:8080 原本本機 Qwen / llama-serverHermes 裡面則可以同時保留兩個 provider:
custom_providers: - name: gemini-proxy base_url: http://127.0.0.1:8317/v1 key_env: CLIPROXY_API_KEY api_mode: chat_completions models: gemini-pro-agent: context_length: 1048576 gemini-3.1-pro-low: context_length: 1048576 gemini-3-flash-agent: context_length: 1048576 gemini-3-flash: context_length: 1048576 gemini-3.5-flash-low: context_length: 1048576 gemini-3.5-flash-extra-low: context_length: 1048576 - name: qwen-local base_url: http://127.0.0.1:8080/v1 api_mode: chat_completions models: Qwopus3.6-27B-v2-MTP-Q4_K_M.gguf: context_length: 131072目前我自己的 Hermes 主模型可以這樣設:
model: provider: custom:gemini-proxy default: gemini-3.5-flash-extra-low context_length: 1048576如果要改回 Gemini Pro agent,也可以改成:
model: provider: custom:gemini-proxy default: gemini-pro-agent context_length: 1048576安裝 CLIProxyAPI
我把它放在 Hermes 目錄底下:
mkdir -p ~/.hermes/cli-proxy/bin cd ~/.hermes/cli-proxy下載 CLIProxyAPI Linux amd64 release,例如我這次用的是:
CLIProxyAPI_7.2.58_linux_amd64.tar.gz解開後會有:
~/.hermes/cli-proxy/bin/cli-proxy-api ~/.hermes/cli-proxy/bin/config.example.yaml確認 binary 可以執行:
chmod +x ~/.hermes/cli-proxy/bin/cli-proxy-api ~/.hermes/cli-proxy/bin/cli-proxy-api --help建立 proxy config
我用的設定大概是這樣,API key 請自己產生,不要貼真值:
host: 127.0.0.1 port: 8317 api_keys: - "replace-with-your-local-random-key" auth_dir: /home/YOUR_USER/.hermes/cli-proxy/auth log_dir: /home/YOUR_USER/.hermes/cli-proxy/logs static_dir: /home/YOUR_USER/.hermes/cli-proxy/static我另外把 key 放進 Hermes 的
.env:CLIPROXY_API_KEY=replace-with-your-local-random-key這樣 Hermes config 裡就可以用:
key_env: CLIPROXY_API_KEY不要把 proxy API key 寫進分享文、git repo 或截圖。
Google OAuth
這一步是關鍵。
CLIProxyAPI 啟動後,照它提供的 login/OAuth flow 讓瀏覽器完成 Google 授權。授權成功後,
auth_dir裡會出現類似:~/.hermes/cli-proxy/auth/antigravity-<your-google-account>.json這個檔案是 OAuth 憑證,權限建議至少設成:
chmod 600 ~/.hermes/cli-proxy/auth/*.json我這台是透過遠端機器操作,所以 OAuth 頁面需要用 SSH tunnel 或可以開瀏覽器的方式完成。這也是很多人會卡住的地方:不是 Hermes 不能接,而是 OAuth callback 沒有正確回到本機 proxy。
用 PM2 常駐 CLIProxyAPI
我的
pm2不在系統 PATH 裡,所以用完整路徑:~/.hermes/node/bin/pm2 start ~/.hermes/cli-proxy/bin/cli-proxy-api \ --name cli-proxy-api \ -- -config ~/.hermes/cli-proxy/config.yaml ~/.hermes/node/bin/pm2 save確認它有活著:
~/.hermes/node/bin/pm2 status ss -ltnp | grep 8317應該看到:
cli-proxy-api online 127.0.0.1:8317 LISTEN測試 proxy
先測
/v1/models:curl -s http://127.0.0.1:8317/v1/models \ -H "Authorization: Bearer $CLIPROXY_API_KEY"我這邊能看到的模型包含:
gemini-pro-agent gemini-3.1-pro-low gemini-3-flash-agent gemini-3-flash gemini-3.5-flash-low gemini-3.5-flash-extra-low再測 chat completions:
curl -s http://127.0.0.1:8317/v1/chat/completions \ -H "Authorization: Bearer $CLIPROXY_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gemini-pro-agent", "messages": [ {"role": "user", "content": "Reply with exactly: Gemini proxy confirmed"} ] }'能正常回覆後,再接 Hermes。
Hermes 設定 custom provider
在 Hermes 的
config.yaml加上:custom_providers: - name: gemini-proxy base_url: http://127.0.0.1:8317/v1 key_env: CLIPROXY_API_KEY api_mode: chat_completions models: gemini-pro-agent: context_length: 1048576 gemini-3.1-pro-low: context_length: 1048576 gemini-3-flash-agent: context_length: 1048576 gemini-3-flash: context_length: 1048576 gemini-3.5-flash-low: context_length: 1048576 gemini-3.5-flash-extra-low: context_length: 1048576主模型可以設:
model: provider: custom:gemini-proxy default: gemini-pro-agent context_length: 1048576或改成比較省的:
model: provider: custom:gemini-proxy default: gemini-3.5-flash-extra-low context_length: 1048576改完後重啟 Hermes gateway:
systemctl --user restart hermes-gateway systemctl --user is-active hermes-gatewayHermes 裡切換模型
在 Telegram / Hermes bot 裡可以用:
/model custom:gemini-proxy:gemini-pro-agent --global /model custom:gemini-proxy:gemini-3.1-pro-low --global /model custom:gemini-proxy:gemini-3.5-flash-low --global /model custom:gemini-proxy:gemini-3.5-flash-extra-low --global切完建議開新 session:
/new--global是改預設新 session。只想改目前 session,可以用--session。接回原本 8080 Qwen
原本本機 Qwen 也可以保留成另一個 provider:
custom_providers: - name: qwen-local base_url: http://127.0.0.1:8080/v1 api_mode: chat_completions models: Qwopus3.6-27B-v2-MTP-Q4_K_M.gguf: context_length: 131072要切回 Qwen:
/model custom:qwen-local:Qwopus3.6-27B-v2-MTP-Q4_K_M.gguf --global /new前提是你的 llama-server / OpenAI-compatible Qwen server 已經在
8080跑著。確認:
ss -ltnp | grep 8080我這次踩到的坑
1. 一開始容易誤會成 MCP
Hermes 本來就可以用 MCP 去調外部工具,
agyCLI 也可以透過 MCP/CLI 被呼叫。但這次要的是「把 Gemini Pro 訂閱 OAuth 當成 Hermes 的模型 provider」,不是「讓 Hermes 呼叫一個工具」。所以正確方向是 OpenAI-compatible local proxy。
簡單判斷:
MCP / CLI tool:模型還是 Hermes 原本的模型,只是多一個工具可以叫 OpenAI-compatible proxy:Gemini 變成 Hermes 的模型本體2.
agy能跑,不代表 Hermes 直接吃得到 OAuthagy自己有 Google OAuth,但 Hermes 不會自動讀agy的登入狀態。中間需要一層 proxy,把 OAuth 模型包成/v1/chat/completions。這就是 CLIProxyAPI 的角色。
3.
pm2可能不在 PATH我這台不能直接跑:
pm2 status要用:
~/.hermes/node/bin/pm2 status文章或 runbook 建議都寫完整路徑,少一個環境差異。
4. OAuth callback 在遠端機器上會卡
如果是在 SSH server、遠端桌面、無頭環境上跑,Google OAuth 頁面開在你本機瀏覽器,但 callback 要回到遠端機器上的 proxy。
解法通常是:
用 SSH tunnel 把 callback port 轉回遠端 或在遠端機器上直接完成瀏覽器授權授權成功的判斷不是「網頁看起來過了」,而是
auth_dir裡真的出現 OAuth JSON。5. Hermes provider 名稱要寫完整
切模型時不是只打模型名,而是:
custom:<provider-name>:<model-name>例如:
/model custom:gemini-proxy:gemini-pro-agent --global少了
custom:gemini-proxy:這段,Hermes 可能會找不到正確 provider。6. 不要把 key 和 OAuth JSON 放進文章
至少這幾個東西不能貼:
CLIPROXY_API_KEY 真值 ~/.hermes/cli-proxy/api_key ~/.hermes/cli-proxy/auth/*.json 任何 Google OAuth token分享時用 placeholder 就好。
最後驗證
我這次最後驗證了三件事:
1. CLIProxyAPI 在 127.0.0.1:8317 online 2. /v1/models 能列出 Gemini models 3. Hermes 可以用 custom:gemini-proxy 跑 Gemini,也可以切回 custom:qwen-local 的 8080 Qwen這樣 Hermes 就不是只能 MCP/CLI 調用 Gemini,而是可以把 Gemini Pro OAuth proxy 當成真正的模型 provider 使用。
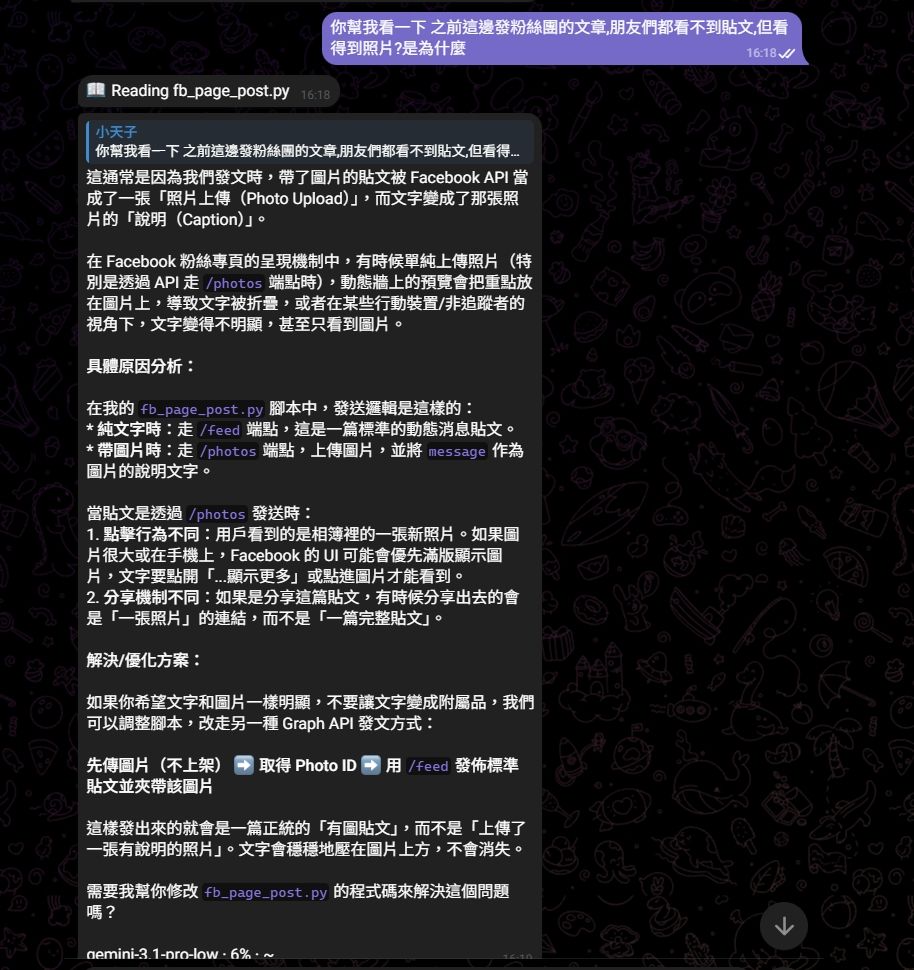
-
小白對顯卡型號的煩惱. 請大神幫一幫忙. 感謝@densha 這種是合法的不會被ban
-
小白對顯卡型號的煩惱. 請大神幫一幫忙. 感謝@abaalei 用gpt5.6 hing跑 5小時額度跑通,一開始讓他做,一直說不行,把你截圖給他他才看懂用本地8317去調用!
-
CLIProxyAPI 已安裝並以 Google Antigravity OAuth 授權。
-
本機 proxy 常駐於 127.0.0.1:8317,由 PM2 管理並已保存開機清單。
-
Hermes 主模型已改為 gemini-pro-agent、1M context,指向本機 /v1 proxy:
config.yaml:1 -
Hermes gateway 已重啟並正常運行。
-
實測 Hermes 主模型成功回覆:Hermes Gemini Pro main model confirmed.
-
舊設定已備份:
backups/config.yaml.20260710-073724-before-cliproxy-gemini
你在 Telegram 打 /new 後,應會看到 gemini-pro-agent、custom、http://127.0.0.1:8317/v1 與 1M context。
-
-
小白對顯卡型號的煩惱. 請大神幫一幫忙. 感謝 -
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@koala 有你看我發的圖 還分開給,好大方的
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@terry
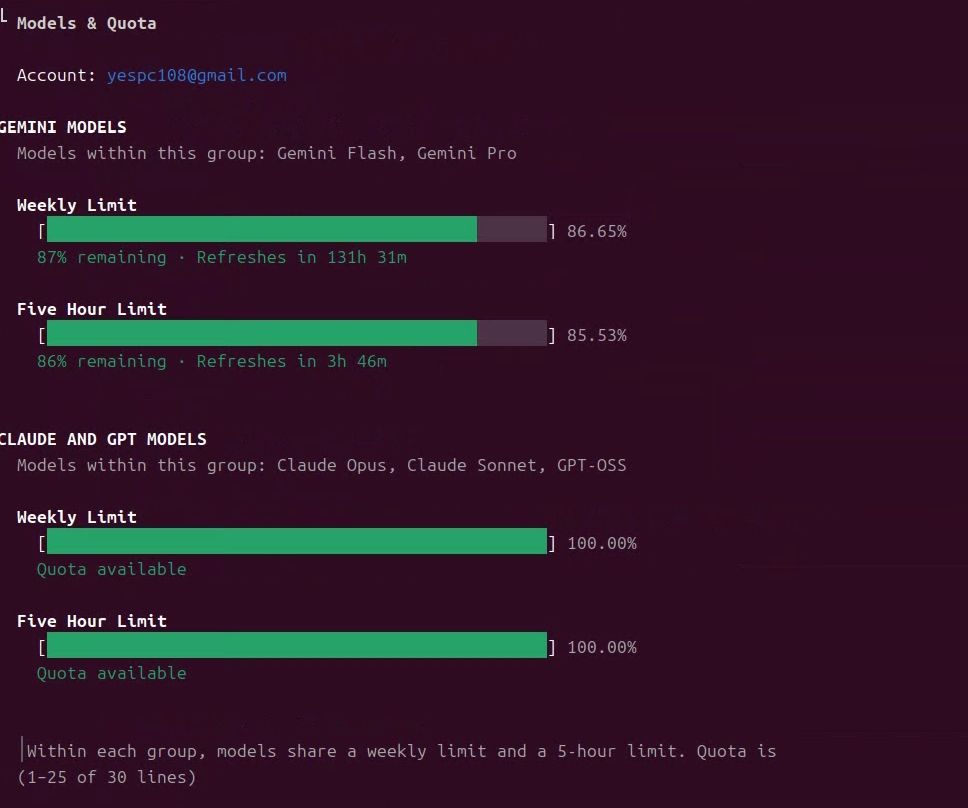 感覺挺大方
感覺挺大方 -
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@terry 肯定是不夠用的,不過偶爾需要調整的hermes滿方便的至少可以不需要費用,多一個agent可以用,目前多這個 跟cc並用感覺額度還夠用 哈
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@terry 對 他不知道在急什麼,,我用3.5 flash速度很快,但用claude驗證他,是有把把事情做完的,要讓他穩一點 用pro可能好一點,我發現一點他的額度沒有跟網頁版聊天共用
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面@old-bro 我剛用也不知道,但應該比cc codex多? 或差不多吧
-
多一個ai agent可以用了,# 終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity `agy` CLI 介面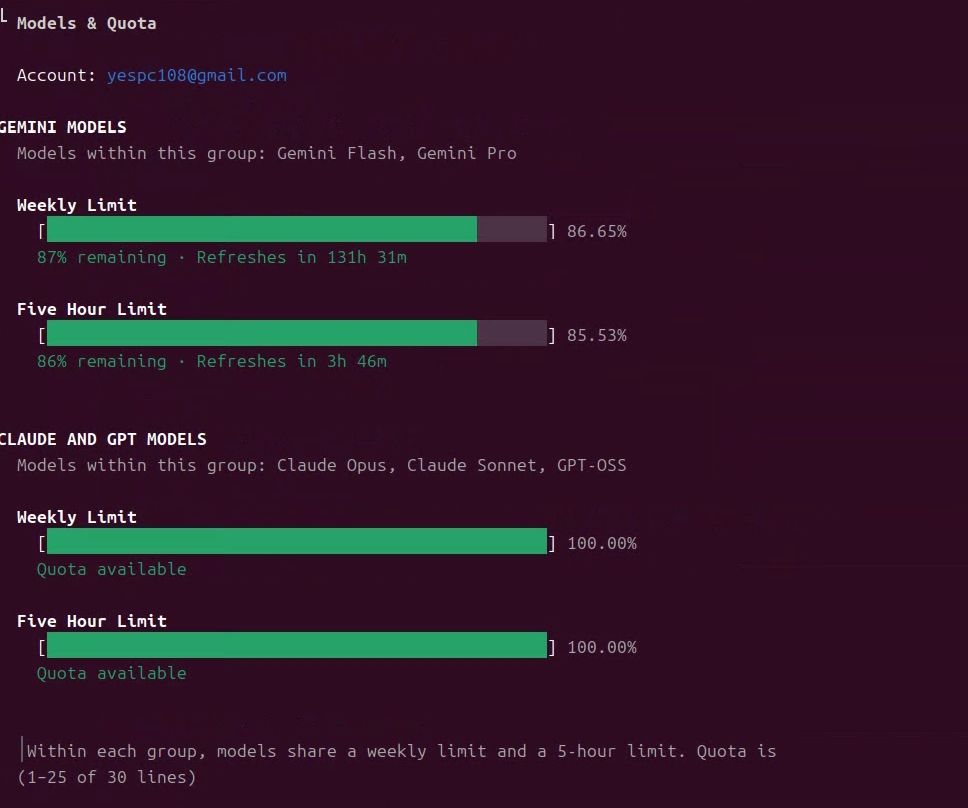 突然想到之前滑過影片有看到可以用,gemini pro訂閱使用新的gemini cli,讓hermes爬文後一下子就裝好了,多一個額度可以用了,不知道是不是我最後一個知道,反正先分享~
突然想到之前滑過影片有看到可以用,gemini pro訂閱使用新的gemini cli,讓hermes爬文後一下子就裝好了,多一個額度可以用了,不知道是不是我最後一個知道,反正先分享~
重點有多款模型可以使用喔!以下是 agy CLI 中可供選擇的完整模型清單以及相關說明:
 可選擇的模型種類與切換方式
可選擇的模型種類與切換方式在 agy CLI 中,你可以在 Pro 訂閱額度下,依據不同任務需求切換以下所有支援的模型:
1. Gemini 系列(原廠首選,與 Pro 訂閱完美相容)
• Gemini 3.5 Flash (Medium) (預設)
• 特點:平衡性最佳,速度與生成品質兼顧。最推薦日常的程式修改、快速 Debug 與小型 Script 撰寫。
• Gemini 3.5 Flash (High)
• 特點:高精度 Flash 版本,針對代碼語意有更細緻的理解,適合中等難度的 Bug 排查。
• Gemini 3.5 Flash (Low)
• 特點:極速版本,回應時間最短,適合格式化調整、程式碼排版或非常簡單的生成。
• Gemini 3.1 Pro (High)
• 特點:具備極強的邏輯推導能力,適合跨檔案的大規模重構、演算法設計與極具挑戰性的 Bug 除錯。
• Gemini 3.1 Pro (Low)
• 特點:Pro 的基礎推理版本,速度介於 Flash 與 Pro High 之間,提供穩定的大模型推理骨幹。2. Claude 4.6 系列(引入思考鏈的推理利器)
• Claude Sonnet 4.6 (Thinking)
• 特點:基於 Anthropic 旗艦模型,並開啟了思考鏈 (Thinking) 機制,極其擅長長上下文的邏輯編碼與架構重構。
• Claude Opus 4.6 (Thinking)
• 特點:最強的 Claude 思考大模型,專門應對極端複雜的邏輯推理與架構設計。3. 開源模型支援
• GPT-OSS 120B (Medium)
• 特點:開源的 120B 大參數模型,提供不同的代碼風格與生成思維,適合作為備用參考。│ [!NOTE]
│ 雖然 agy 同步支援 Claude 與 GPT-OSS 模型,但為了確保完全使用你每月 20 美元 (Google One AI Premium) 的訂閱額度,強烈建議優先選用
│ Gemini 3.5/3.1 家族模型,以獲得最穩定的配額保障與流暢的開發體驗。終極省錢秘笈:如何用 Gemini Advanced (Pro) $20/月訂閱,暢玩 Gemini Antigravity
agyCLI 介面![!NOTE]
- 文件建立時間:台灣時間 (CST) 2026-07-06
- 適用對象:已訂閱 Gemini Advanced (Google One AI Premium) 的開發者,或正在評估是否切換為包月制 AI 開發工具的使用者。
許多人在使用 AI 終端機開發工具(如 Claude Code 或各類 Agent CLI)時,常常會遇到一個痛點:使用付費 API Key (Pay-as-you-go) 太燒錢了!
尤其在大型專案中,每次詢問都需要讀取數萬行的程式碼上下文,一來一回,單日 Token 費用可能就高達數美元甚至數十美元。但你可能不知道,Google Antigravity CLI (
agy) 其實支援直接綁定你的 Gemini Pro / Advanced 訂閱!
這意味著,你只需要支付與 ChatGPT Plus、Claude Pro 或 Claude Code 同等的 每月 20 美元 (約台幣 $650 元) 訂閱方案,就能在終端機內享受無痛、不額外收費的 Agentic Coding 體驗。
 計費方案大比拼:API Key vs Pro 包月訂閱
計費方案大比拼:API Key vs Pro 包月訂閱比較項目 API Key 付費 (Pay-as-you-go) Gemini Advanced (Pro 訂閱) 計費方式 依 Input/Output Token 用量計費 每月固定 $20 美元 (台幣約 650 元) 額度與心理壓力 用越多越貴,高頻開發時會產生「Token 焦慮」 包月制,享有個人日常開發的高 Rate Limit,無額外帳單壓力 適用場景 低頻率、間歇性的小工具呼叫 高強度 Pair Programming、大規模重構、跨多檔案 Codebase 分析 額外福利 無額外權益 同步享有 Google One 2TB 空間、Google Workspace 內 Gemini 助理、Web 版 Gemini Advanced
 ️ 快速上手:3 步驟用 Pro 訂閱帳戶啟用
️ 快速上手:3 步驟用 Pro 訂閱帳戶啟用 agyCLI使用你的 $20 訂閱方案來啟動
agy非常簡單,只需要依照以下步驟進行:步驟 1:確認訂閱狀態
確保你目前登入的 Google 個人帳戶已經訂閱了 Gemini Advanced (或屬於 Google One AI Premium 方案的訂閱者)。
步驟 2:執行
agyCLI在你的終端機中,直接輸入以下指令啟動:
agy[!TIP]
如果你是第一次在該電腦或環境下執行,系統會偵測到未驗證狀態,並主動引導你進行 Google 帳戶授權。步驟 3:網頁瀏覽器授權 (Oauth 驗證)
- 終端機會顯示類似以下的提示:
Please visit the following URL to authorize: https://accounts.google.com/o/oauth2/auth?... Enter verification code: [ ▍ ] - 複製終端機中顯示的 URL,並在登入有 Gemini Advanced 訂閱帳戶的瀏覽器中打開。
- 點擊「允許授權」以提供
agyCLI 使用該帳號呼叫模型的權限。 - 將網頁上顯示的驗證碼(Verification Code)複製,貼回終端機並按下 Enter。
大功告成! 現在你的
agyCLI 已經跟你的 $20 Pro 訂閱方案完美對接,可以開始暢快地進行 AI pair programming 了!
 常見問題與實用小技巧 (FAQ)
常見問題與實用小技巧 (FAQ)Q1:使用 Pro 訂閱會限制我的 Token 或是次數嗎?
會,但通常非常寬裕。
與 Web 版的 Gemini Advanced 類似,agyCLI 在 Pro 訂閱下擁有相當高額的速率限制 (Rate Limits)。除非你進行 24 小時不間斷的極限並行壓力測試,否則對於正常的人機協作開發,其額度絕對綽綽有餘,體驗與 ChatGPT Plus / Claude Code 完全一致。Q2:我可以自訂 CLI 的設定嗎?
可以,
agyCLI 的所有偏好設定、預設模型等,都儲存在本機的設定檔中:- 設定檔路徑:
~/.gemini/antigravity-cli/settings.json
你可以透過編輯此 JSON 檔案來調整 UI 外觀、提示詞偏好或 MCP (Model Context Protocol) 伺服器的設定。
Q3:如果在終端機卡住或想結束,該怎麼做?
- 結束對話並退出:輸入
/exit或/quit,或者在空白輸入列連按兩次Ctrl + D。 - 推薦的 Slash 命令:
/help:列出所有可用的 Slash 命令。/schedule:設定定時任務或背景監控。/goal:適合用於 overnight 的超長執行複雜任務。
[!IMPORTANT]
結論:不要再傻傻地為了跑 CLI Agent 去儲值昂貴 of API Key 了!
只要善用你手邊的 Gemini Advanced $20 包月訂閱,就能無縫享有 Google 最頂尖的 Antigravity AI 編碼助手。趕快打開終端機,輸入agy開始體驗吧! -
r9700 32G速度总算达标了,27B MTP,能上50t/s@sospda 想請教如果tg調用hermes實際的token速度
-
AMD pro R9700显卡已经拿到了,主机是新攒的,准备装机,请论坛内的大神、老玩家们给些开荒意见,帮着避避坑,谢谢啦,将持续上报后续作业。基本上你上完ubuntu後就不會再去看你的電腦畫面了,之後全程hermes代勞了,所以應該不用太擔心不習慣的問題,我也是過來人!!一開始win11轉ubuntu挺擔心不會用的,後來發現根本用不太到~頂多開檔案總管看comfyi出的圖,最後也把google driver接上同步,就再也沒去電腦前了,偶爾rustdesk遠端連過去
-
關於GB10跟N1X@怪物 如果兩張pro6000可以跑deepseek v4 flash 體驗應該是很不錯的,另外你把模型改用 qwen3.6 27b看看你會開心很多,我目前7900xtx 24g,單卡就玩的飛起了,讓cc or codex幫你把hermes你平常的工作流跑通寫成skill給hermes會好用很多的!!供你參考
-
你们的Hermes都是怎么网上冲浪的?@applejuice 因為有兩張7900XTX 另一張跑comfyui不是很常用,還有餘裕就弄個小模型跑壓縮 快很多!!