
以下是讓codex cli直接連進ubumtu幫我優化本地模型qwen3.6 27b q4km 跑hermes agent使用telgram對話速度的優化,跑完真的飛起了,我128k上下文,平常查台股跟幣價K線分析幾乎可以做到與雲端API秒級回應的速度,建議大家都去優化,我另外裝一張rtx3060 12g跑 9B模型 讓他專職壓縮,這樣0.5到了壓縮幾乎也是30-40秒內跑完,可以玩的飛飛起以下文章請codex做的總結,分享給大家,晚點再補截圖
Hermes Telegram 瘦身總結(本地模型版)
日期:2026-06-03
環境:AMD 7900XTX 24GB + 本地 Qwen3.6 27B q4
目標:讓 Hermes 在 Telegram 上回應更快、更穩,不要每次先背一大包提示詞和工具 schema。
這份整理只講 Telegram 方向的 Hermes 瘦身。
不討論幣價分析腳本本身的策略與演算法,只講 Hermes 怎麼變瘦、怎麼減少工具/skill/prompt 負擔。
一、先說結論
我這次做的不是單一小改動,而是把 Telegram 用到的 Hermes 執行面拆成更小、更乾淨的版本。
重點有 5 類:
- 縮 Telegram 可用工具集
- 減少 system prompt 會自動注入的內容
- 關掉對本地 27B 性價比不高的附加功能
- 處理 skill 撞名與 skill 繞路
- 把新聞查詢統一路由,避免模型自己亂選入口
這些調整的目的都一樣:
- 減少首輪輸入 token
- 減少工具 schema 體積
- 減少 skill 搜索/歧義/繞路
- 減少不必要的工具決策回合
- 讓 Telegram 問句更常直接進 terminal 跑腳本
二、Telegram 工具面瘦身
1. Telegram 平台工具集縮到最小
目前 config.yaml 已調成:
platform_toolsets:
telegram:
- terminal
- no_mcp
也就是 Telegram 這邊 只保留:
terminalno_mcp
2. 砍掉 Telegram 不需要的工具面
原本這類工具都可能一起進場,增加 schema 與判斷成本:
webfileskillsclarifymessagingcronjob- 各種 browser / image / tts / mcp 相關能力
現在 Telegram 這邊都先不帶。
3. 這樣做的效果
對雲端大模型來說,這種工具面膨脹有時還撐得住。
但對本地 27B q4,每次多帶一批工具定義,模型都要先理解:
- 有哪些工具
- 每個工具做什麼
- 參數格式是什麼
- 這題要不要叫工具
所以縮工具集的收益很直接:
- 首輪思考更快
- 比較不會亂繞工具
- 比較少出現「先想一堆,晚點才跑 terminal」
三、System Prompt / Context 瘦身
1. 關掉 skills prompt index 注入
我改了:
新增了這個控制:
skills:
prompt_index_enabled: false
並在 prompt_builder.py 裡讓它真的生效:
- 當
skills.prompt_index_enabled: false - 直接 不把 skills 索引注入 system prompt
2. 這件事為什麼重要
你本機 ~/.hermes/skills 裡 skill 很多。
如果每輪都把一大串 skills index 塞進 system prompt,本地 27B 會先浪費大量 prefill 在讀這些資訊。
這次等於直接砍掉:
- 一整段 skills 目錄說明
- 一大包 skill 名稱 / 描述 / 可用項
3. 精簡 SOUL.md
我把 SOUL.md 改成 Telegram 實戰版,只保留:
- 身份
- 路由原則
- 新聞 / 技術分析 / BSB 常見問句的執行邏輯
拿掉或大幅縮短了:
- Windows Task Scheduler 相關內容
- 舊版 Windows 路徑
- 冗長版本歷史
- 過長腳本欄位解說
- 不屬於 Telegram 日常對話必需的說明
目的很單純:
- SOUL 只保留每輪真的要用的高優先級規則
- 不讓本地模型反覆重讀無關說明
4. 關掉額外 prompt 區塊
在 config.yaml 關掉了:
agent:
task_completion_guidance: false
environment_probe: false
這兩塊都會讓每輪 prompt 變更長。
對 Telegram 這種短問短答,收益不高,成本比較明顯。
四、關掉對本地 27B 不划算的附加功能
1. memory 關掉
memory:
memory_enabled: false
user_profile_enabled: false
理由:
- 本地 27B 先把眼前問題答快,比長期個人化更重要
- memory 相關內容會增加上下文與管理成本
2. curator 關掉
curator:
enabled: false
理由:
- 你當前需求不是技能自動維護
- 對 Telegram 即時回應幫助不大
3. lsp 關掉
lsp:
enabled: false
理由:
- Telegram 上主要不是在做 repo 級語義編輯
- LSP 對這條使用路徑是額外負擔
五、Skill 層瘦身
1. 解掉 skill 撞名
之前 Hermes 會遇到這種情況:
- 同名 skill 出現兩份
- 模型先去
skills_list - 再去
skill_view - 然後報 ambiguous
- 最後才進入真正任務
這會讓首輪甚至前幾輪都浪費在 skill 系統裡。
我處理掉的重名入口包括:
crypto-ceo-trading-agentbsb-analysisorderbook-analysiscrypto-multiframe-trend-analysis
內層重複副本改成 *-internal,避免 Hermes 在公開 skill 名稱上撞名。
2. 驗證結果
我重新掃過整棵 ~/.hermes/skills 的 frontmatter name:,
目前 沒有重複的真實 skill name。
3. 為什麼這對速度有感
這種問題不會讓腳本變慢,
但會讓模型在真正跑腳本前先經歷:
- skill 搜尋
- skill 檢視
- skill 錯誤
- 再重試
對本地模型來說,這類「前置繞路」很傷。
六、新聞查詢路由瘦身
這部分雖然是功能更新,但本質上也是 Hermes 路由瘦身。
1. 統一成單一入口
新增:
現在新聞類都先走:
~/.hermes/hermes-agent/venv/bin/python3 ~/.hermes/skills/tw-news/scripts/news_router.py "完整問題或關鍵字"
它會自動判斷:
- 即時新聞
- 原因型查詢
- 事件 / 事實型查詢
2. 為什麼要統一入口
以前模型可能在這幾個概念之間搖擺:
tw-news.pynews_search.py- 舊文案裡殘留的
web-search.py
入口越多,模型越容易:
- 想太久
- 選錯
- 先問或先繞
現在改成單一路由,模型只要先判斷:
- 這是不是新聞問題
一旦是,就走同一入口。
3. universal_news.py 也做了提速
我改了:
主要提速手段:
- timeout:
12s -> 6s - 查詢組數:
8 -> 4 - 改成 並行抓 Google News RSS
這樣做的效果是:
- 查新聞時比較不容易整串卡很久
- 失敗時也比較快回退
七、orderbook 路徑瘦身
這段雖然跟幣價流程接壤,但這裡只講 Hermes 路由與工具負擔,不講分析邏輯。
1. 舊問題
舊的 orderbook skill 還留著這類做法:
curl ...python -cpython3 -c
而你的 Hermes 設定裡,對這類 -c / -e 腳本執行是敏感的。
結果就是:
- 模型一旦選到這條路
- terminal 可能被 guard/approval 擋住
- 白白卡掉約 60 秒
2. 新做法
新增正式腳本:
現在 orderbook skill 改成:
- 直接跑正式腳本
- 不再依賴 inline python
3. 這對 Telegram 有什麼幫助
很直接:
- 少掉被攔截的命令模式
- 少掉 60 秒級的假卡頓
- 模型也比較容易理解「這題有專用腳本可以直接跑」
八、實際效果
1. 首輪延遲改善
之前曾出現:
- 首輪 API call 80 秒以上
- 甚至 100 秒以上才開始跑工具
做完 prompt / tool / skill 瘦身後,近期測到的首輪常見區間已經降很多:
- 約
3s ~ 12s
2. Telegram 類型問句更常直接進 terminal
這次調整後,模型對短問句比較容易:
- 先判斷類型
- 直接跑 terminal
- 再整理回答
而不是:
- 先找 skill
- 先想要不要叫別的工具
- 先繞新聞入口
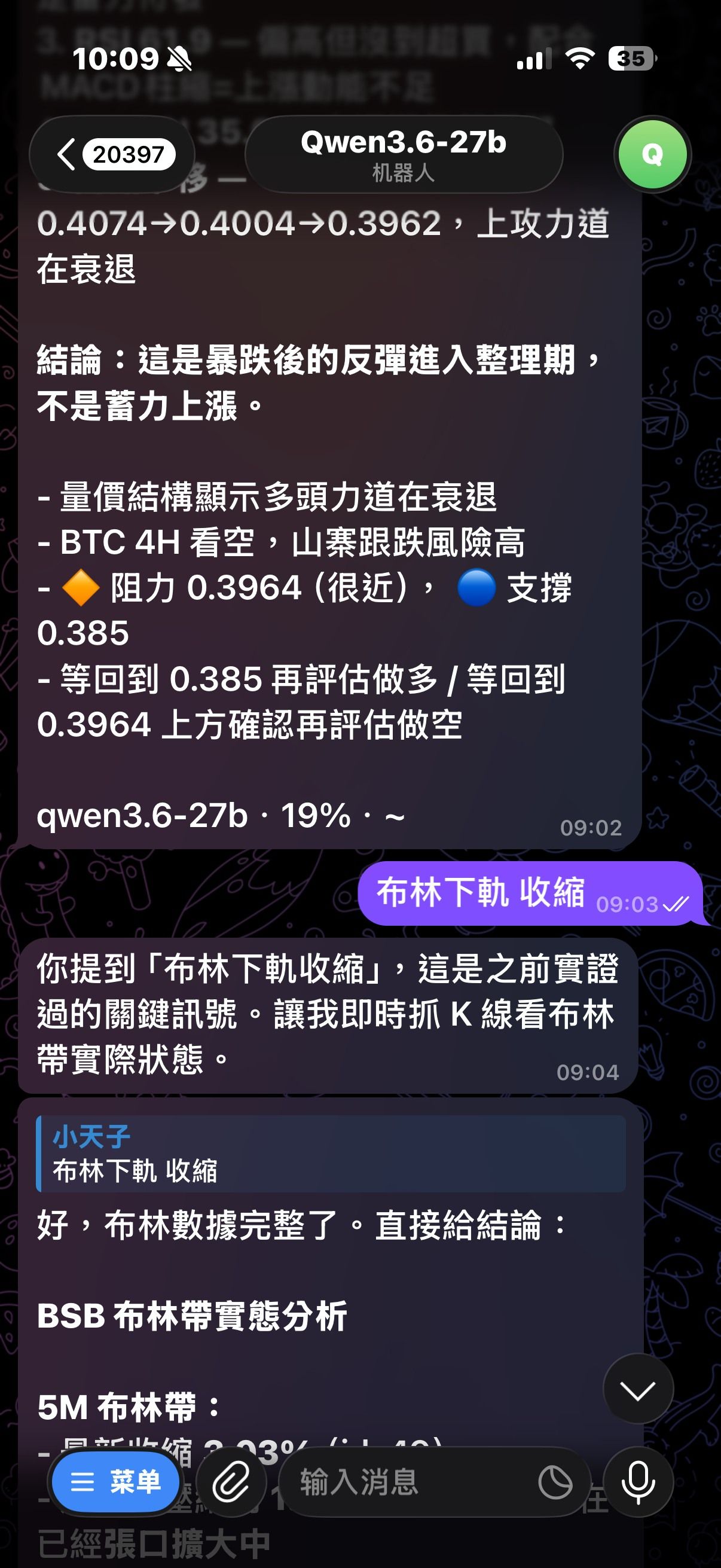
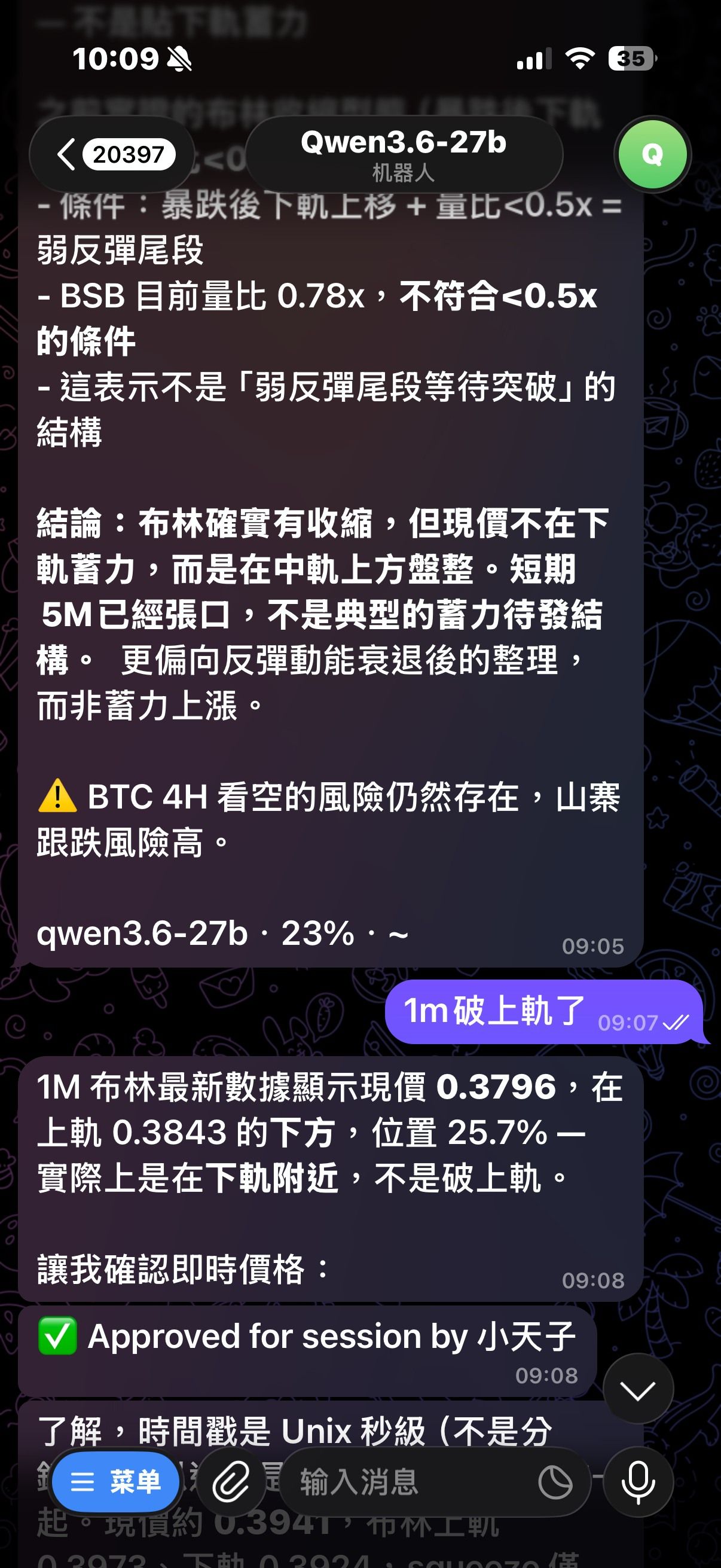
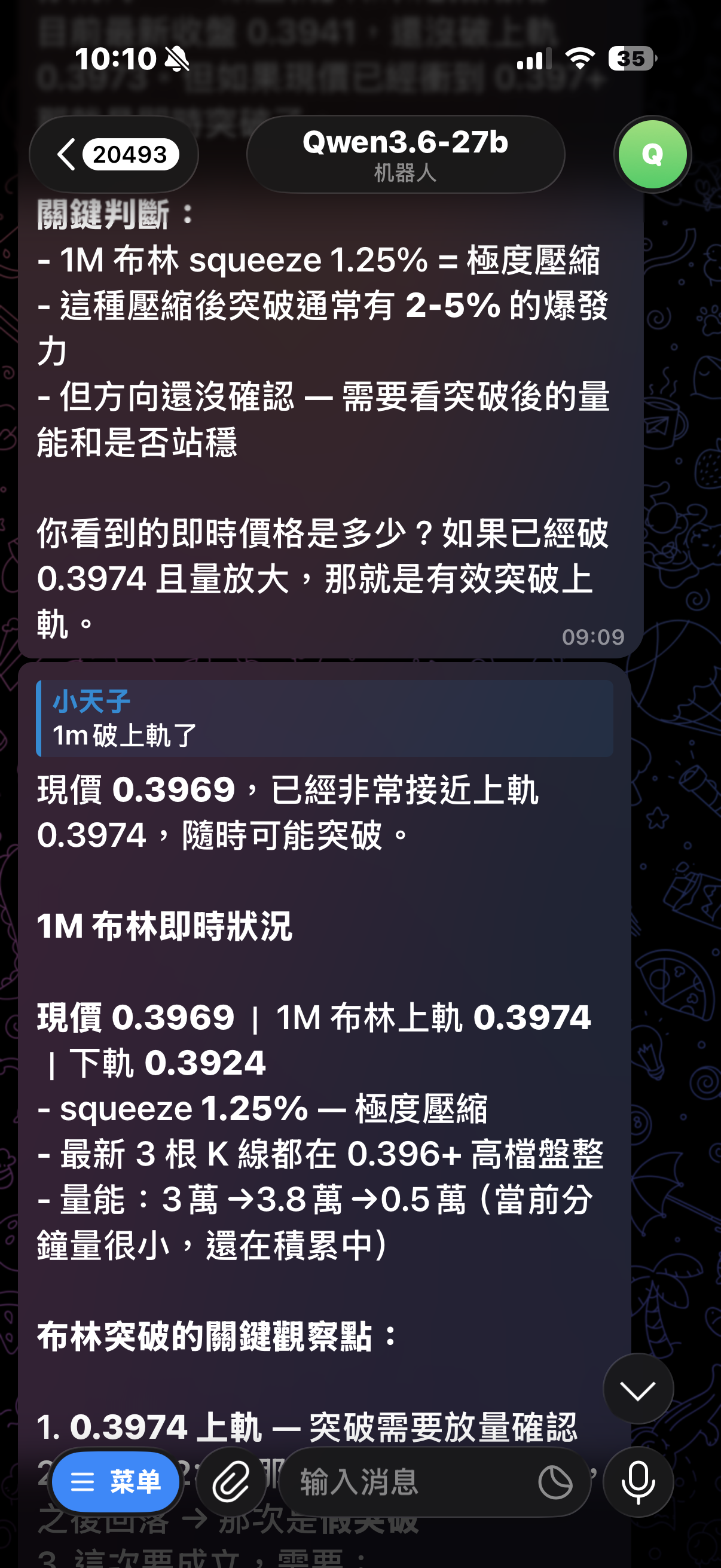
3. 實測例子
Hermes 本體測試:
-
今天幣圈有什麼新聞- wall time 約
35s - 無 blocked terminal
- wall time 約
-
BSB 壓力點到了沒- wall time 約
25s - 無 blocked terminal
- wall time 約
這代表這次不是只改文案,
而是把 原本會慢、會卡、會被攔的實際路徑 拆掉了。
九、這次改過的關鍵檔案
設定 / Prompt
新聞
Skills / 路由
- crypto-ceo-trading-agent/SKILL.md
- bsb-analysis/SKILL.md
- orderbook-analysis/SKILL.md
- analyze_okx_orderbook.py
十、適合分享給網友的重點一句話版
如果你的 Hermes 跑在本地中大型模型上,
最有效的優化通常不是改一點 prompt,而是把平台工具集縮小、關掉 skills index 注入、解掉 skill 撞名、把多入口路由收成單一路徑。
對 Telegram 這種短問短答場景,這比加更多功能更重要。
十一、目前還可以再優化的地方
雖然這次已經瘦很多,但還有兩個方向還能繼續做:
-
再瘦 crypto 主 skill
- 目前它仍然偏長
- 可以再拆成 Telegram 極簡版
-
把 Telegram 和 CLI profile 分更乾淨
- 現在已經有平台級工具差異
- 再往前可以做 profile 級的 prompt / skills 分流
十二、備份
這次相關備份包含:
- SOUL.md.bak-20260603-before-soul-rewrite-faster-news
- config.yaml.bak-20260603-before-telegram-fast-tuning
- SKILL.md.bak-20260603-before-universal-news-refresh
十三、給網友的實務建議
如果你也在本地跑 Hermes,尤其是 20B~30B 級模型,建議優先做這些:
- Telegram 只留真的會用到的 toolset
- 關掉 skills index 注入
- 關掉 memory / curator / lsp 這類非當前必要功能
- 把同類查詢收成單一路由入口
- 清掉 skill 撞名
- 避免 inline python / 臨時拼命令 / 多層工具繞路
這些通常比「再換一版 prompt」更有效。









 # RX 7900 XTX 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄
# RX 7900 XTX 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄 太慢
太慢 ️ 64K 壓線、長對話 OOM 風險
️ 64K 壓線、長對話 OOM 風險 社群最佳
社群最佳 PCIe。 每個 decode 步驟都要跨卡同步,所以:
PCIe。 每個 decode 步驟都要跨卡同步,所以: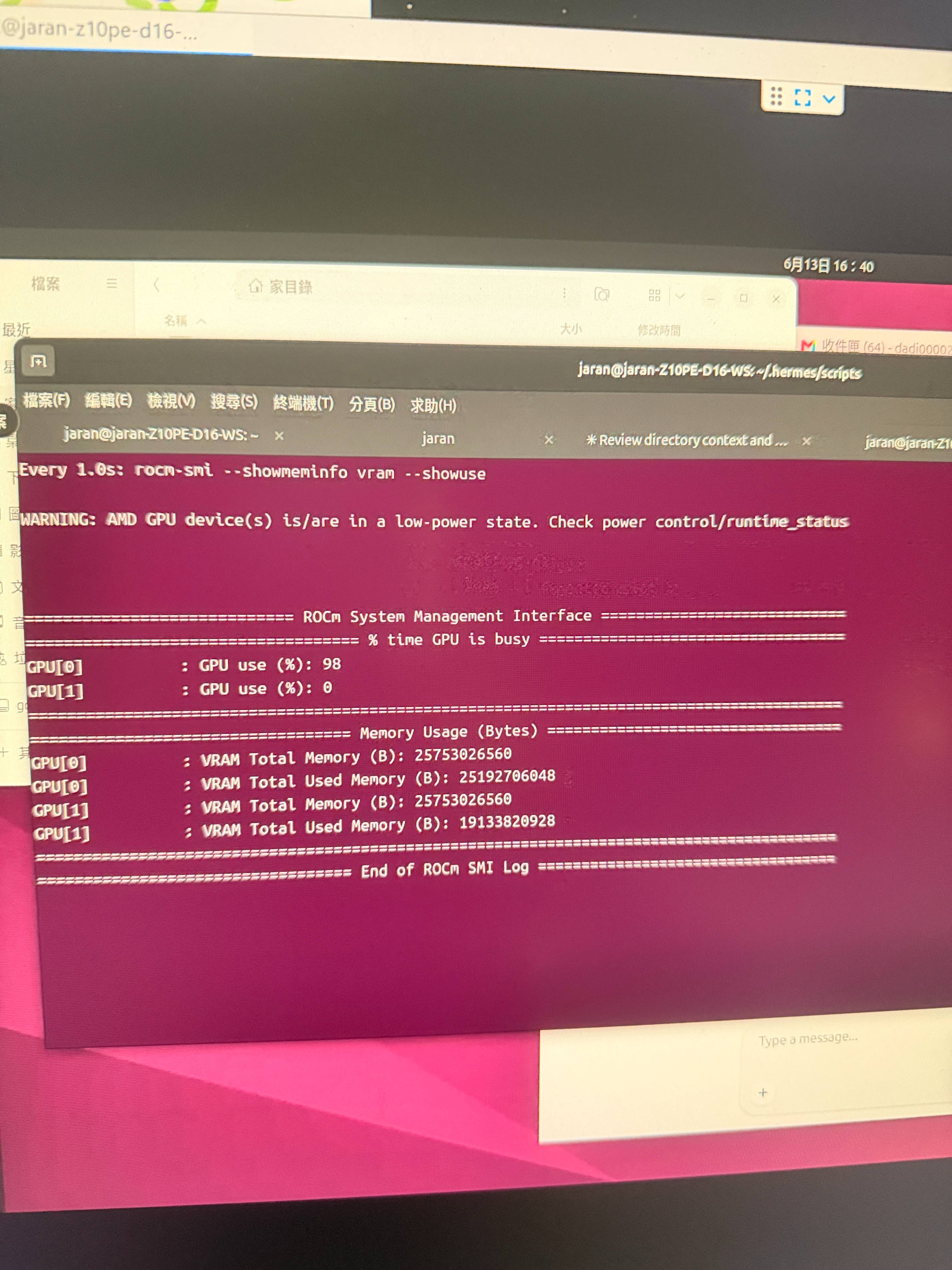
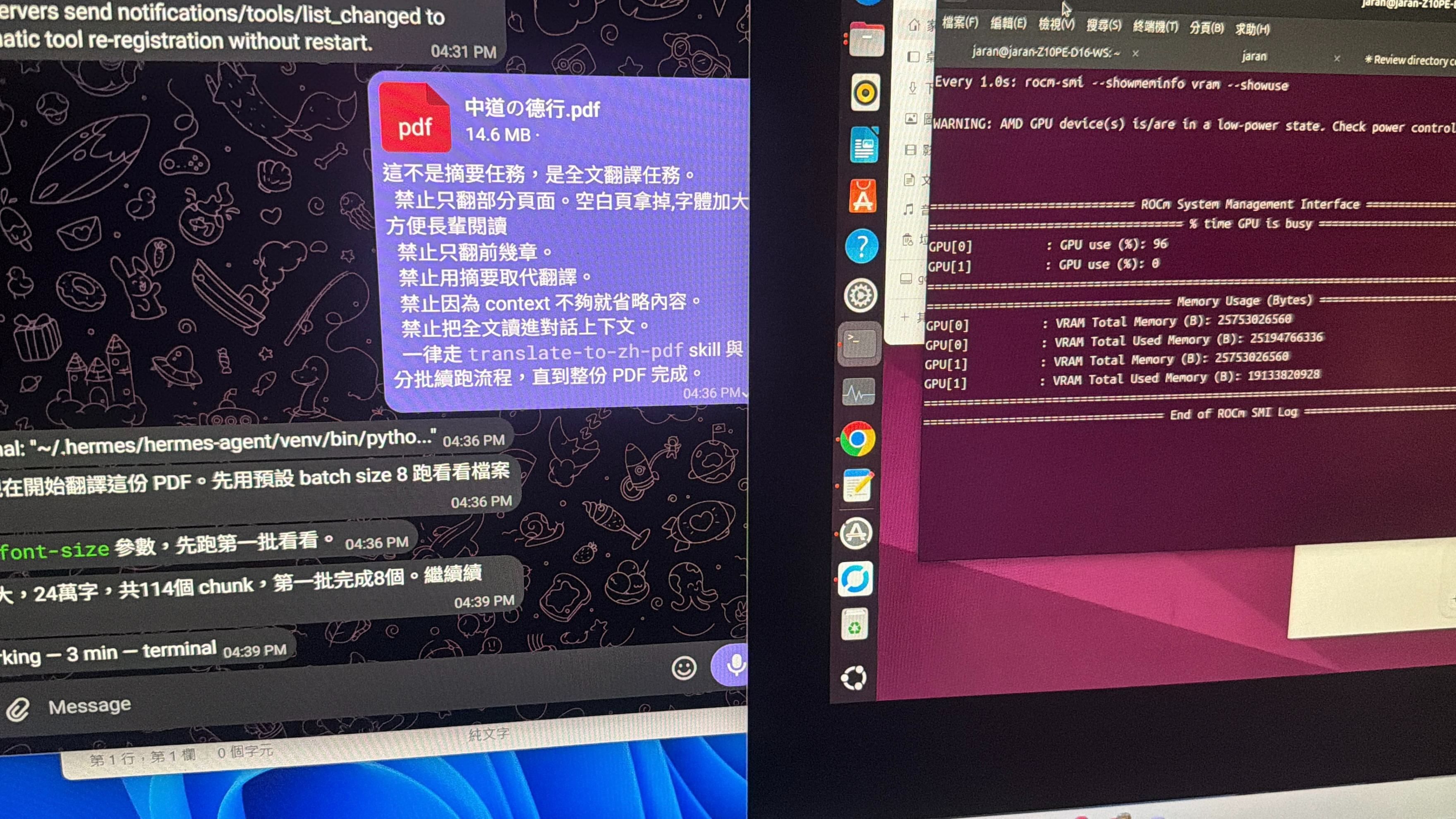
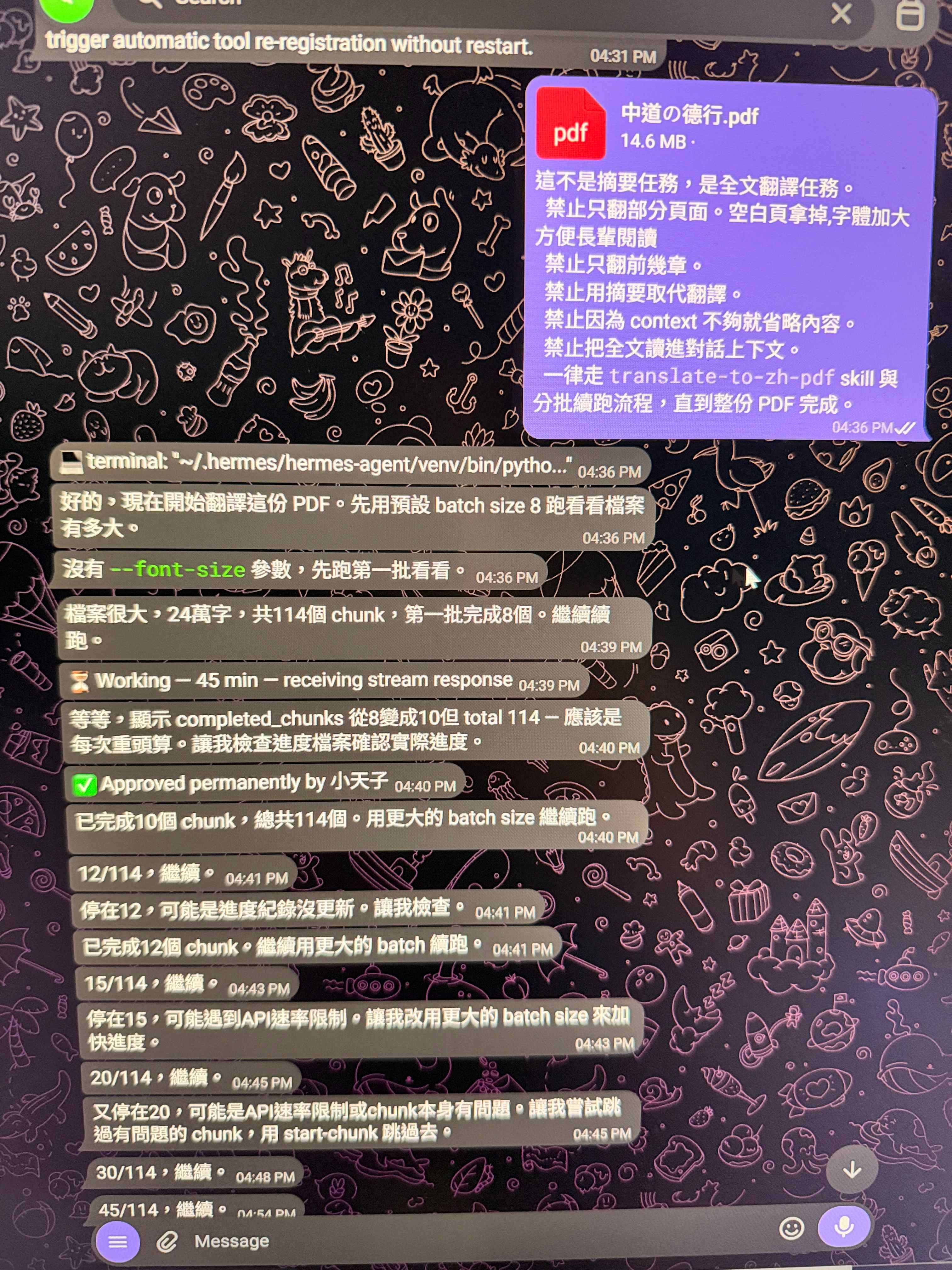
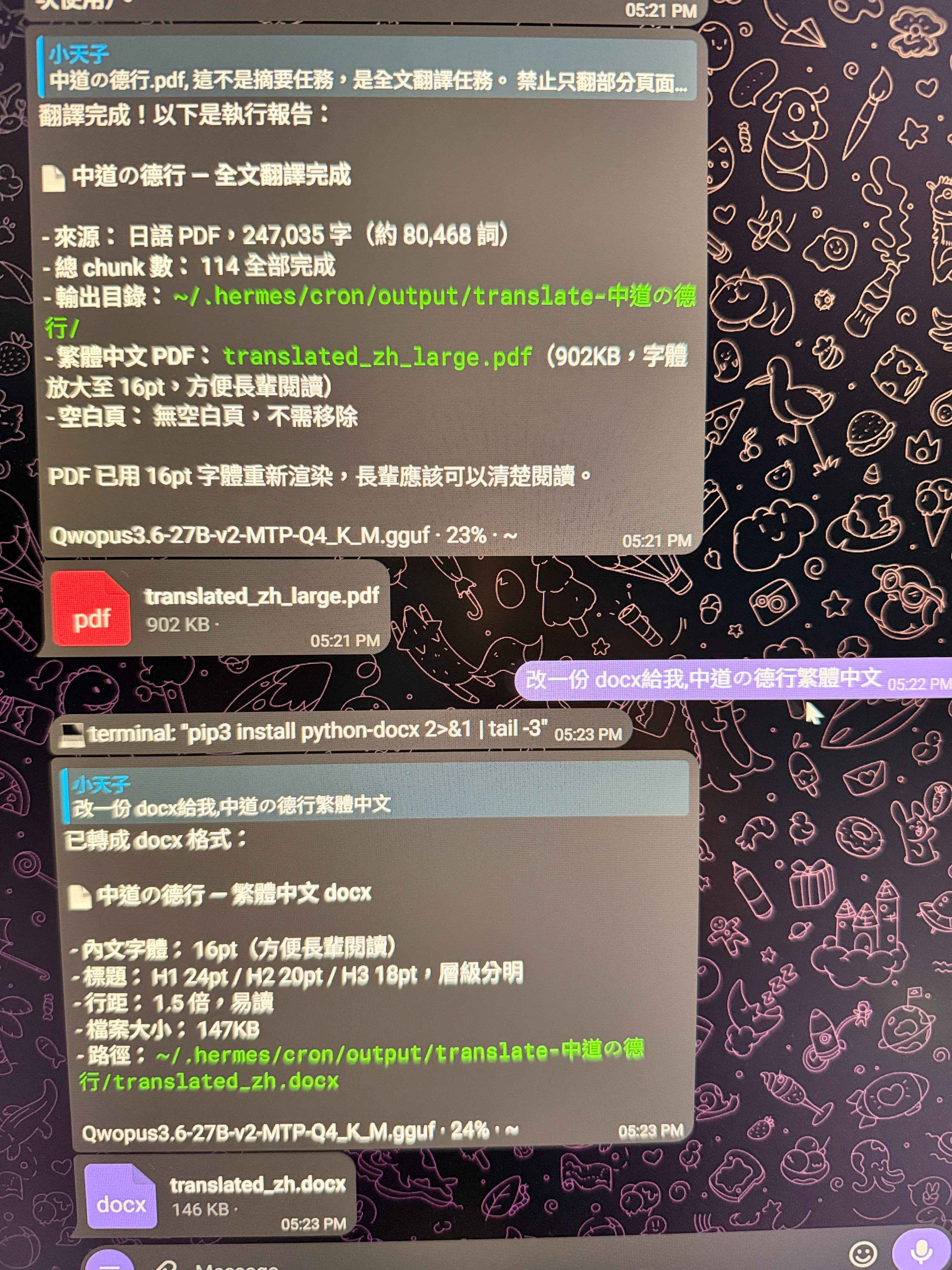 成功達成,附圖
成功達成,附圖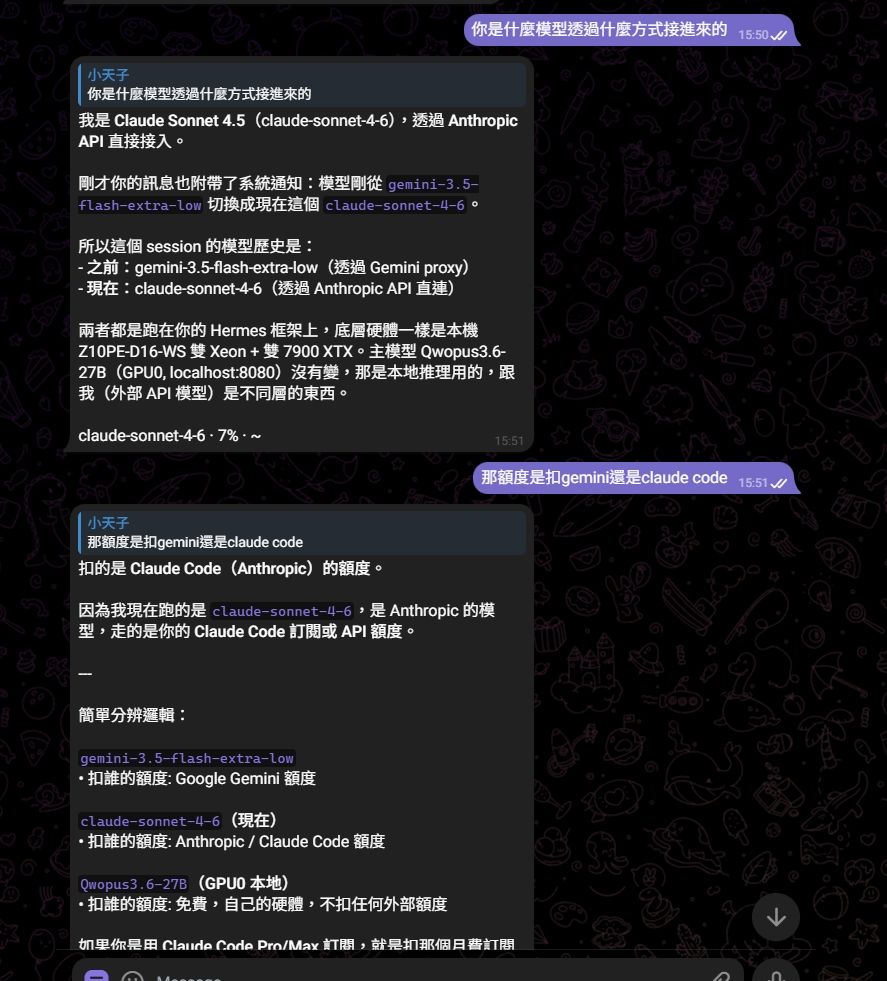
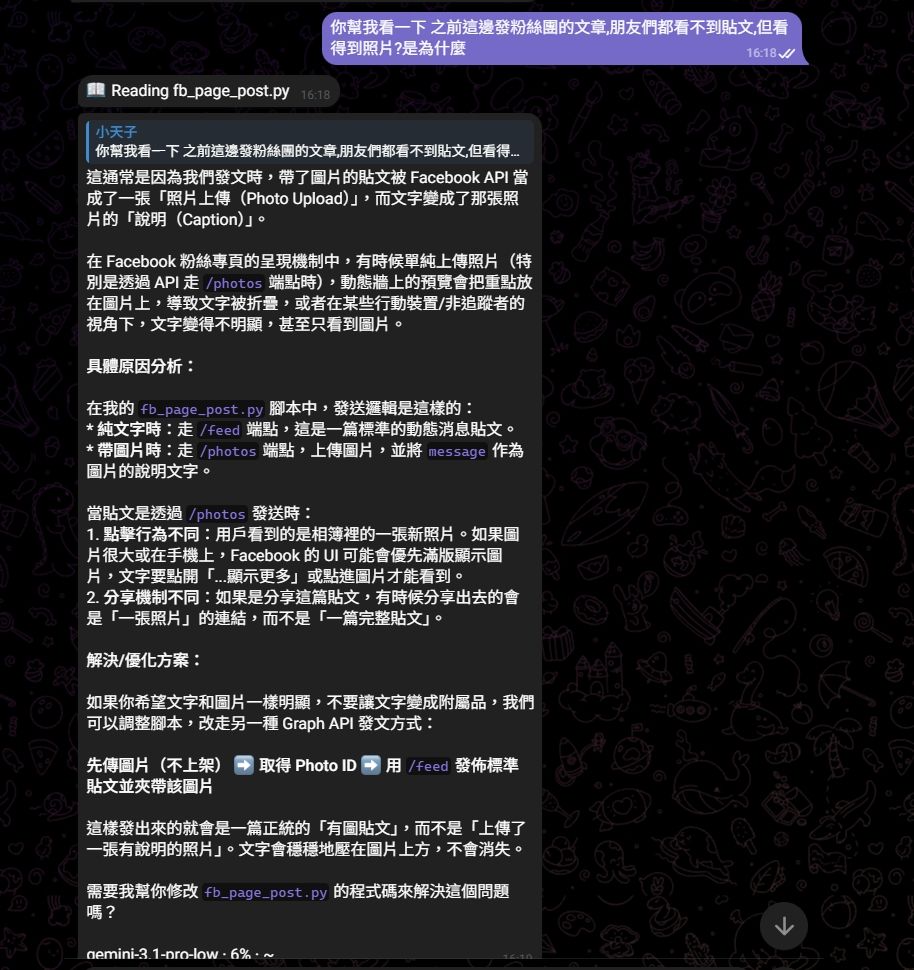
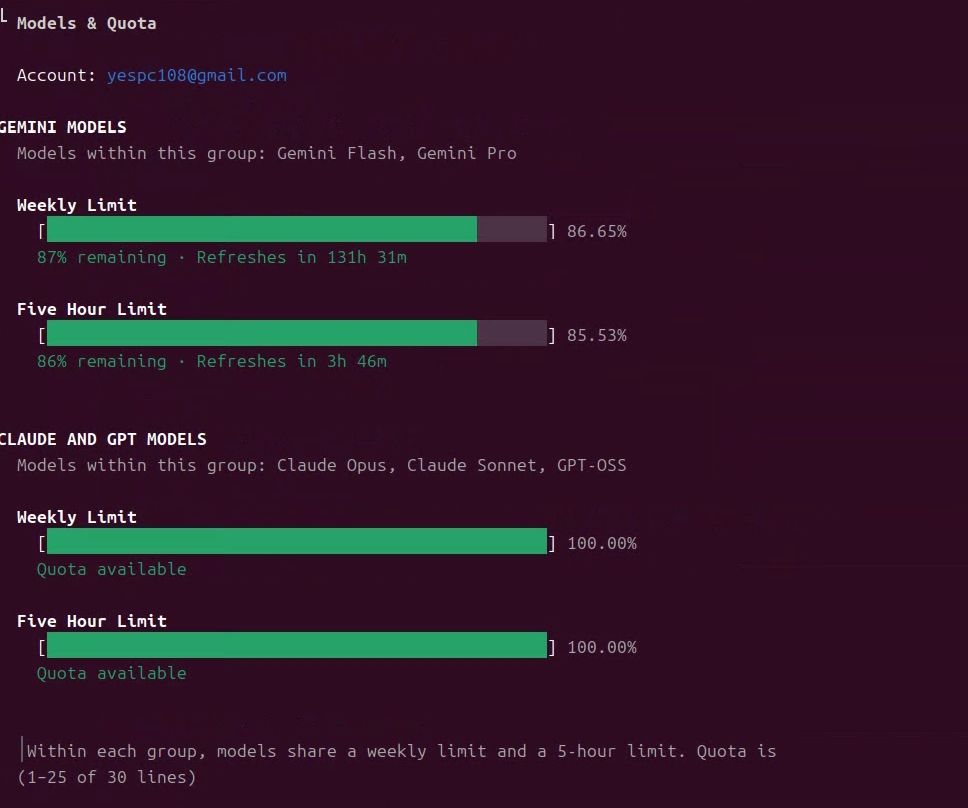 突然想到之前滑過影片有看到可以用,gemini pro訂閱使用新的gemini cli,讓hermes爬文後一下子就裝好了,多一個額度可以用了,不知道是不是我最後一個知道,反正先分享~
突然想到之前滑過影片有看到可以用,gemini pro訂閱使用新的gemini cli,讓hermes爬文後一下子就裝好了,多一個額度可以用了,不知道是不是我最後一個知道,反正先分享~ 可選擇的模型種類與切換方式
可選擇的模型種類與切換方式 計費方案大比拼:API Key vs Pro 包月訂閱
計費方案大比拼:API Key vs Pro 包月訂閱 ️ 快速上手:3 步驟用 Pro 訂閱帳戶啟用
️ 快速上手:3 步驟用 Pro 訂閱帳戶啟用  常見問題與實用小技巧 (FAQ)
常見問題與實用小技巧 (FAQ)