
生成耗时主要浪费在了装载卸载模型文件上了,4步计算的耗时是正常的,没有使用sageattention
J
John8686
@John8686
-
为大家带来dasiwa大神的wan2.2工作流实测 -
为大家带来dasiwa大神的wan2.2工作流实测我在折腾了几天ltx2.3之后,认为ltx的效果缺失不太行。即使使用了一堆动作控制和人物保持技术,还是得不到哪怕是凑合用的效果。
经过多轮实测,只有在多图关键帧引导下,或者数字人念稿子这个领域,ltx2.3的效果能够保障。能够保障的意思是,使用AI脚本让它自己在那跑,不需要人工审核筛选。
可能确实是我菜,但是我已经上了很多额外的约束手段了,还是只能有这个效果的话,就不太值得折腾了。
于是我还是转向wan2.2工作流。之前我尝试过AIO的wan2.2工作流,是比较省显存的。但由于没有高低噪节点,和官方工作流差异过大了,导致我不知道该怎么往里面加stand_in这类的辅助插件,无法解决人物一致性的问题。这个确实是因为我菜,但是作者也没有提供任何文档,想学也没地方学是吧。
链接文本
链接是c站相当热门的一个wan2.2高低噪节点,关键是这个作者文档写得特别扎实,有什么不懂的读文档就行。dasiwa大神怕我等菜鸡学不会,甚至还录了一个youtube视频教我们。这就非常体贴了。
图片是使用fp8 SafeTenso模型,480P,16帧,8秒视频的硬件占用情况。可以看到,基本上榨干了32g DRAM+20g vRAM,而且由于显存不足,已经开始占用共享显存了。5秒视频用了288秒生成,8秒视频用了580s。
也就是说,需要32gb的VRAM才能比较好的应付fp8 SafeTenso模型带来的压力。gguf还没测,但是也省不了太多的,肯定还是超过20gb。
不过好消息是,即使使用了fp8 SafeTenso模型,也没有出些写入虚拟内存(写硬盘)的情况。只要不写硬盘,实际上也算不上多慢,我认为可以忍受。
115312_00001.mp4
给大家看一下5s的480P视频质量。 -
实测刘悦的ltx2.3整合包,我不同意他的思路。@001-fcuk-guge
点的是你的链接 -
实测刘悦的ltx2.3整合包,我不同意他的思路。我又要承认,是我肤浅了。刘悦的天才之处在于,他先用放大节点把视频浅空间缩小了一倍(没错,是缩小,逆用放大节点)。然后你实际计算的时候,其实计算的是缩小了一倍的视频。然后他再用Upscale x2工作组,把缩小了一倍的视频给放大了一倍。
他通过这种方法,有损的降低了视频生成所需要的硬件,这应该就是他8g显存可玩的核心秘籍。
这个思路是非常有价值的,我使用gguf_4_k_m之后,是可以原生的生成24帧,720p,15秒视频的,刚好把我的3080-20g和32g内存压榨到极点。图忘了截了,手打一下吧:
显存占用最高到18.9gb,内存占用最高到31.7gb。cpu和gpu各跑一半(因为是gguf,有几层在cpu上计算)。
如果再学习一下刘悦的这个思路,视频尺寸还可以再扩大。 -
实测刘悦的ltx2.3整合包,我不同意他的思路。@001-fcuk-guge 已经被删除了,你点开试试。我看的肯定式b站粉丝数、播放量最高的那个秋叶。不过不重要了,我已经不用国内互联网学习了。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。@001-fcuk-guge 秋叶整合包式全网著名包。除了臃肿倒是没有其他缺点。但是他那个先要扫码加微信的下载方式我接受不了。最开始我也是看B站上国内的教程学,但是有一个算一个全都要加微信加飞书什么的,太恶心了。现在我都看红迪上老外的教程。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。@ye9ok 因为按照常规理解,内存炸了就应该往虚拟内存里面写东西。
我首先确认了我的虚拟内存在固态硬盘,然后又把盘符给换了,各种折腾,但是这个整合包始终不往虚拟内存写数据,就盯着我的机械硬盘霍霍。最后我盯着资源管理器看的时候发现,我的机械硬盘编号是hdd 0。然后我就用open code搜文件夹,ai确认了hdd 0是写在Python脚本里的。
刘悦这样做的好处是,如果小白没设置虚拟内存,或者虚拟内存设置过小,那么这个写死了的脚本可以确保成功跑完,出视频,绝对不会oom。无非就是非常慢,非常卡。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。@wwcd2016 如果你图文都没有摸到边的话,肯定是你的问题,不是3090的问题。24g显存是很能打的。
首先,请放弃整合包这种东西,这玩意有毒,别去碰。
然后,请前往英伟达官方网站链接文本,下载工作站版本的显卡驱动NVIDIA Studio 驱动,而不是游戏版game ready。接着,请下载DDU,这是一个可以彻底删除干净你现有显卡驱动的软件链接文本,点这个链接去官方网站下载。下载好之后安装运行它,选择英伟达图标,一路点确定,它会帮你把系统的显卡驱动删得干干净净。
重启之后你的电脑没有显卡驱动,分辨率变得特别低,不用担心,这是正常的。你安装一下之前你下载好的NVIDIA Studio 驱动就行了。
**到此为止,恭喜你折腾完显卡驱动了。**没错,n卡也是需要折腾驱动的,只是没有A卡那么折腾。然后,请前往comfyui的官方发布页链接文本下载官方的便携包。
需要注意的是,你的3090显卡是支持cu131的,也就是可以支持非常新的版本。但是这里面有一个微小的坑——版本太新了,你一旦遇到问题,全网找不到解决的方法,所以不适合菜鸟。下载页面一共有四个下载选项,我建议你下载ComfyUI_windows_portable_nvidia_cu126.7z这个旧版本。cu126是比较旧的版本,换句话说就是很成熟,不至于出什么大问题,出了问题你问ai也好,搜视频教程也好,比较容易解决。
解压这个官方便携包,你的comfyui已经可以成功运行起来了。但是你还没有下载任何模型权重,所以还跑不了图。
你建议你去著名的c站下载这个模型链接文本,这个是最好的动漫风格模型,没有之一。因为它可以画你懂的那种图。
下载这个6.5g的模型文件后,把他复制到\ComfyUI_windows_portable\ComfyUI\models\checkpoints\ 里面,然后重新启动comfyui。
在默认的工作流中(第一次启动comfyui应该会自动弹出一个默认工作流),如果没有的话,用我写的这个简单出图.json 把这些json文件鼠标拖动,扔到comfyui网页上,它自动识别。
找到Checkpoint加载器(简易),鼠标单击下拉条,选择WAI-illustrious-SDXL_17.safetensors。然后点右上角的运行按钮就开始跑图了。
你先跑出第一张图,以后要学的东西非常多,你自己到网上找教程看。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。最后,我强烈建议各位不要使用任何整合包,只使用官方的便携包,所有依赖自己手动安装。
依然推荐RuneXX大佬的正规gguf工作流,gguf才是从根本上降低了显存的占用,不要搞那些奇技淫巧。
国内的各种教程,各种整合包,多数是卖课卖模型的,碰都不要碰。
下载模型只认准huggingface和C站,下载节点只认准github和huggingface。
小白不可能知道人家整合包里面的python代码写了什么玩意,会不会把你的电脑变肉鸡。 -
实测刘悦的ltx2.3整合包,我不同意他的思路。我承认昨天的我有点菜了。今天把它彻底捋了一下,应该是完全搞明白了。
刘悦的整合包,使用一系列的python脚本,对工作流的默认工作模式进行了大量的魔改。核心改动为:
所有模型默认先往DRAM里加载,如果DRAM加载不下了,脚本写死了往HDD 0里面加载,而非是页面文件中加载。这一点是坑中之坑,我折腾了好久才弄明白。
如果你有64gb的内存,而且你是全固态硬盘,那么你是感觉不到这个整合包坑在哪的。
因为内存的读写速度虽然比显存慢一些,但是慢不了太过分;读写固态硬盘虽然会毁掉硬盘,但如果你是小白的话,你也不知道这个知识点,不知道就不会担心受怕。但是我只有32g的内存,而且好死不死,我的HDD 0是一块机械硬盘。于是运行这个整合包时,就发生了内存写满了往机械硬盘写的盛况,这tm能不卡到崩溃么。
弄明白了他的思路,剩下的事情就好办了:
把他整合包里面\ComfyUI\custom_nodes完整的剪切到我的官方comfyui下(这个是节点文件夹)
把他的\ComfyUI\user\default\workflows工作流剪切到官方comfyui对于目录下(这个是工作流文件夹)
把他的\ComfyUI\models剪切到官方comfyui对于目录下(这个是模型文件夹)
把他的qwen3-vl-2b剪切到comfyui根目录下(这是个文生音频模型,但是我暂时没搞明白这是干啥用的,肯定是有用不能删)
其他全都删了就行了。然后用官方comfyui直接跑,模型会默认往vram里面加载,不再强制加载进内存了。当vram加载满了,才会往内存里面写;当内存写满了,会往页面文件里面写。这时候我可以设置页面文件在固态硬盘里面,读写硬盘的速度就快多了。
实测:3080-20g+32g内存,480p视频,测试了100帧,只在二次放大的节点时,往硬盘写了几秒钟文件,其他时候靠vram和dvram就扛下来了。大大降低了对硬盘寿命的损耗,而且速度变得非常的快。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。@terry 不是的,它默认的加载器是官方的二合一加载器,可以同时选择视频模型和文字解码模型那个,不支持gguf。gemma3实在是太大了。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。@williamlouis 我夸克没有会员,每秒100多k的速度在那下载。
-
实测刘悦的ltx2.3整合包,我不同意他的思路。夸克挂了三天机,终于把这个整合包下载下来了。
直接试跑——oom崩溃。
看了一下日志,居然是因为我的页面文件设置得不够大?
自己观察了一下,这个整个包载入的模型尺寸很大,不是量化模型。
于是手动把主模型换成了fp4精度的,把text_encoders模型也给换了。试跑——差点把我的硬盘给整炸了,好家伙一直100%,全靠页面文件虚拟内存硬抗呗。
我这可是换了更小的模型的,他原版工作流,为了省显存,对内存的要求太极端了。这种资源占用,影片没跑几段,别硬盘给我弄挂了的。于是直接上红迪搜了一下,发现社区是有成熟的gguf模型工作流的链接文本
这是RuneXX大佬的huggingface页面。直接下载工作流,然后按照comfyui的报错,把缺失的插件和模型全都装齐,就可以开跑了。 -
wan2.2视频模型,3080-20g实测可跑通。@001-fcuk-guge 经过这两天的折腾,发现这条路线的问题。他没有采用官方的高低噪工作流,因此,无法得到各种兼容官方工作流的插件的加持。比如XX ID,用来保持人脸一致性。
所以这条路实际上走不通,只能当玩具玩玩。 -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s@566656661 实测35BA3B不弱,安排他写打砖块游戏,一次就通,表现比27b还要好,27b需要debug之后才通。
-
wan2.2视频模型,3080-20g实测可跑通。请注意,虽然生成过程中的显存占用低于16gb,但是在载入提示词解码模型时,显存占用来到了18gb,所以4060这种16g的显卡跑这个工作流会非常卡,有oom风险。
坛主一直声称3080不要去折腾wan2.2,我实测发现是完全可以的。
也不需要下载任何启动器或者整合包,这一点我个人认为很重要。因为你不知道那些整合包里面有没有留什么python脚本,有没有安全性风险。 -
wan2.2视频模型,3080-20g实测可跑通。@williamlouis 我跑的是nsfw视频,上图不太合适吧。
我上个资源管理器截图吧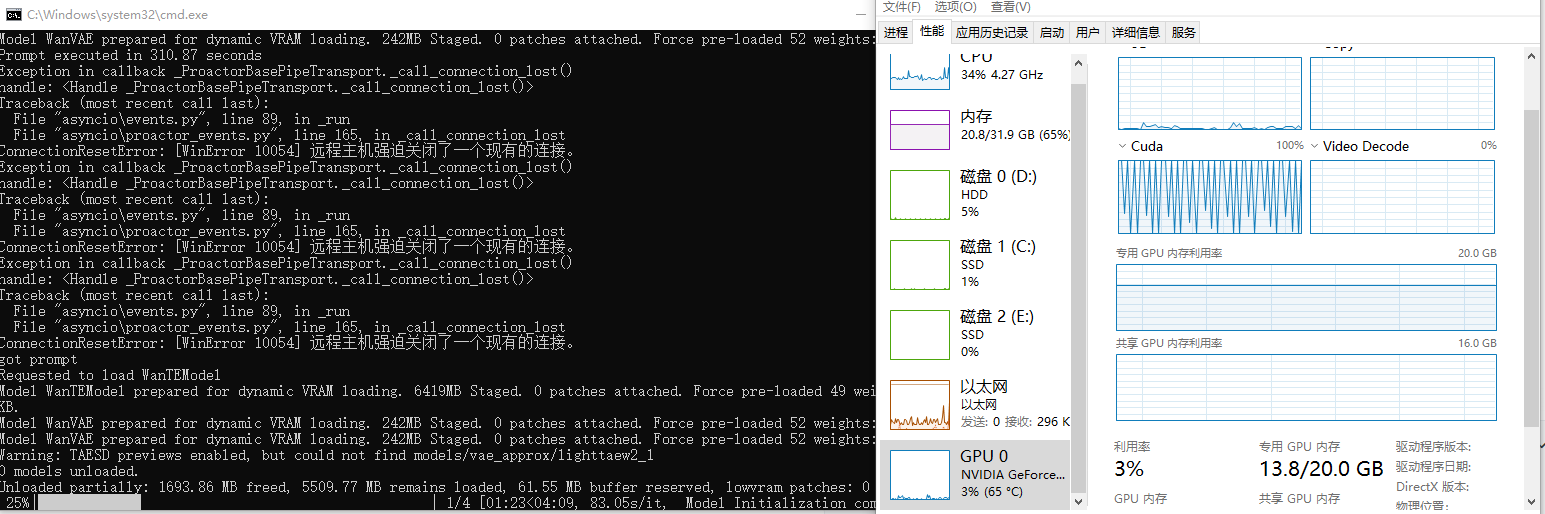
该图为15帧每秒,150帧,4步出视频,480p视频生成过程中的系统资源占用情况。
-
wan2.2视频模型,3080-20g实测可跑通。@BKNNNN Q8模型大小就18g+,肯定不能。最多上Q6版本。
我认为Q5量化版本很好,进入到k采样器环节时,显存占用14.5g。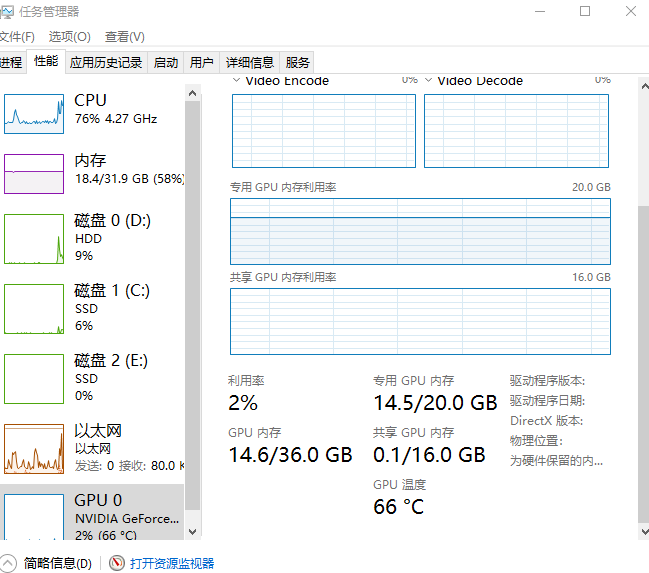
这样就有了很长的视频时长冗余。
这个看你个人取舍。 -
wan2.2视频模型,3080-20g实测可跑通。都在说刘悦的ltx2.2整合包很好,但是需要夸克网盘下载。我这个人特别不喜欢装这种客户端,所以一直没下载。
今天想着自己搭建一下工作流,在huggingface上搜索了一下,发现一个挺成熟的wan2.2工作流,支持你懂的那种视频生成。实测生成130帧视频,显存占用为15.6gb。更长的视频还没空跑,反正3080-20g感觉应该够了。
这个是原作者的链接:链接文本
熟手直接下载原作者的工作流就可以了。
生手下载这个我用中文注释过的json文件,然后直接拖动进comfyui即可。
rapid-aio-mega-gguf-example.json如果你的comfyui是白板的(没下载过整合包等,插件依赖不完整),那么你打开的这个工作流到处都是报错的红框框,不要紧张,这是正常的。
按照侧边栏的报错信息,一个一个把缺失的依赖安装上就行了。缺失分为三种:插件缺失,模型缺失,图片缺失。插件缺失:通过comfyui manager安装缺失的插件即可,就是把报警信息里的插件名字复制粘贴到搜索栏,然后点安装就行了。
模型缺失:报警信息里面提供了详细的模型名称,模型存放的位置。你按照要求,用google搜索,然后去huggingface下载就行。这里有一个小技巧,huggingface的下载链接,迅雷是可以识别的,你可以复制链接到迅雷中下载,不一定要用浏览器下载或者官方推荐的xnet下载。
这是量化版模型作者的链接:链接文本
你显存低的话,不能用原版模型,必须得用量化版的模型,点上面的链接下载。
你显存低的话,不能用原版模型,必须得用量化版的模型,点上面的链接下载。
你显存低的话,不能用原版模型,必须得用量化版的模型,点上面的链接下载。图片缺失:当你解决的所有缺失的插件和模型后,会发现还有一条报警消除不了,那是因为你图生视频工作流中,没有加载图片。加载完图片自然就不报警了。
特别注意 显存低的用户,不要下载超过wan2.2-rapid-mega-aio-nsfw-v12.1-Q5_K.gguf的模型。q4量化或者q5量化的版本就是极限了,在往上显存就不够了。