记录一下自己RTX3080 20g的一些配置
WIN11安装:
git clone https://github.com/ggerganov/llama.cpp
cmake -B build -D GGML_CUDA=ON -D CMAKE_CUDA_ARCHITECTURES=86 -D LLAMA_BUILD_SERVER=ON -D LLAMA_BUILD_ALL_EXAMPLES=OFF -D LLAMA_BUILD_TESTS=OFF -D LLAMA_BUILD_EXAMPLES=OFF
cmake --build build --config Release --parallel 2
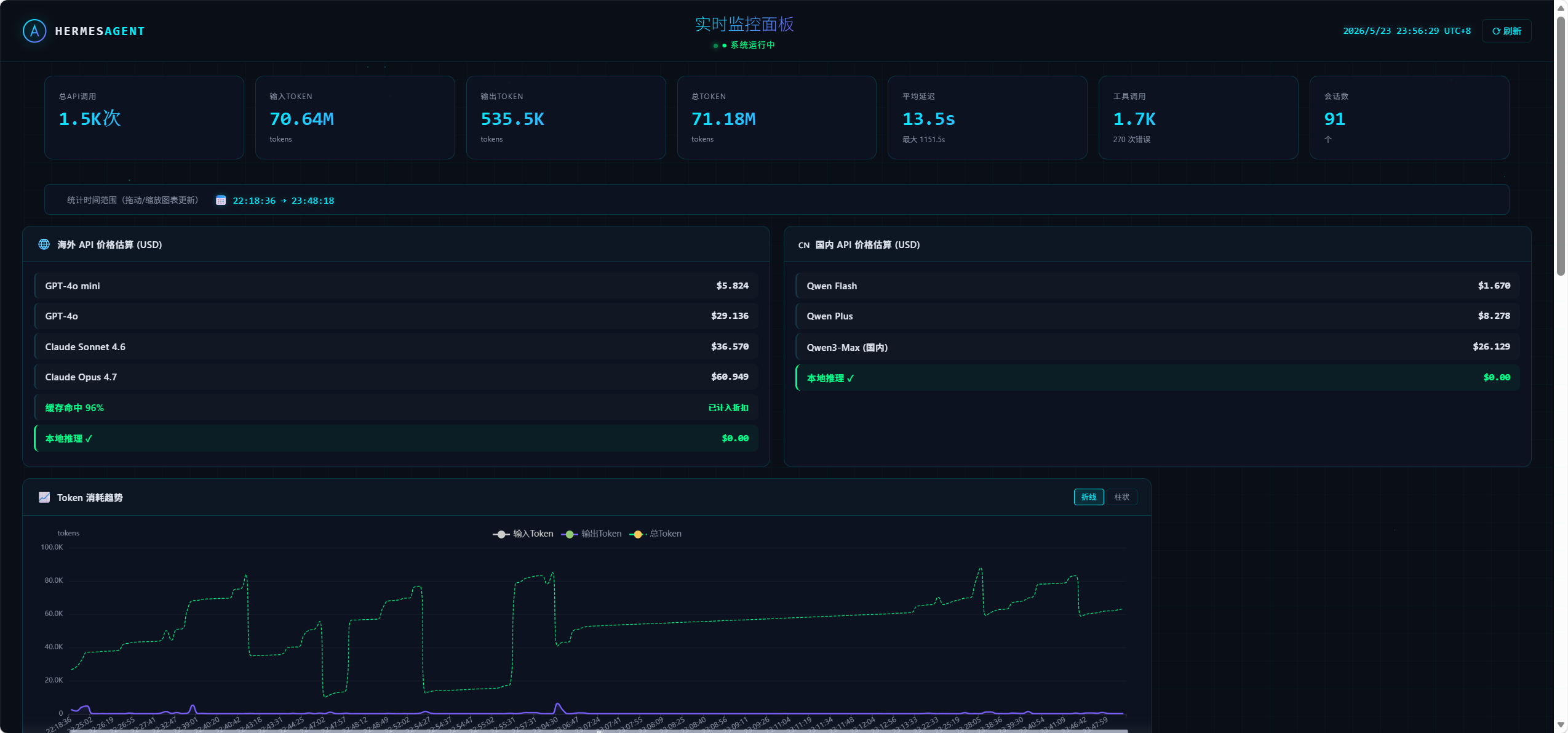
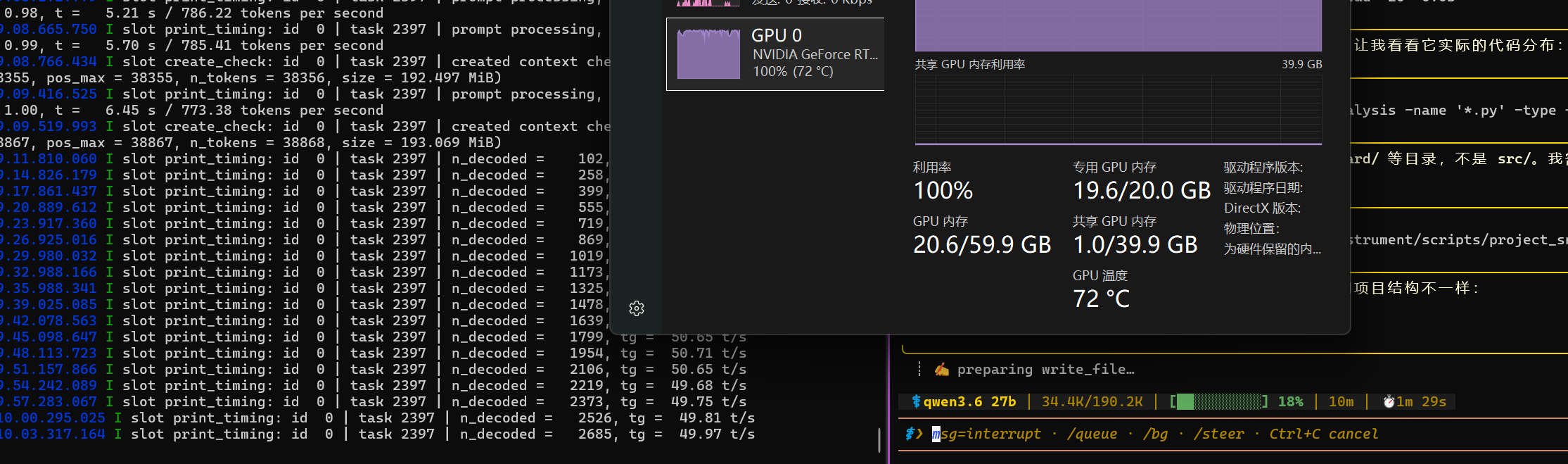
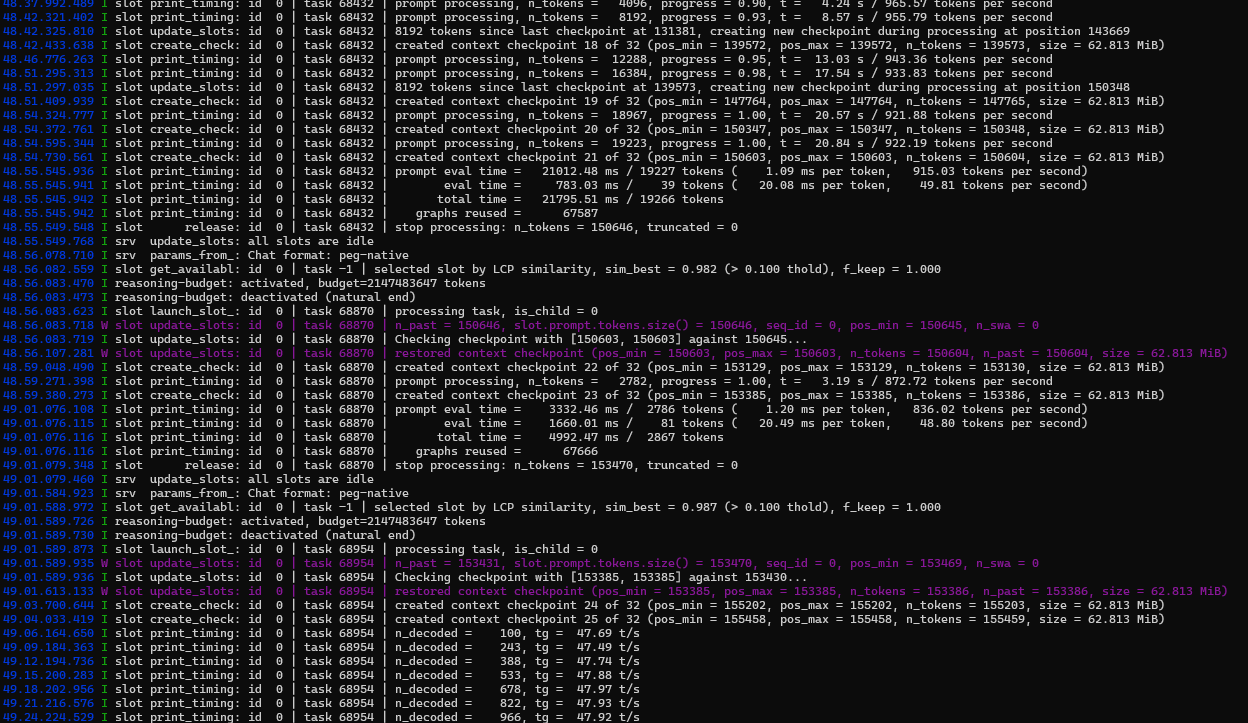
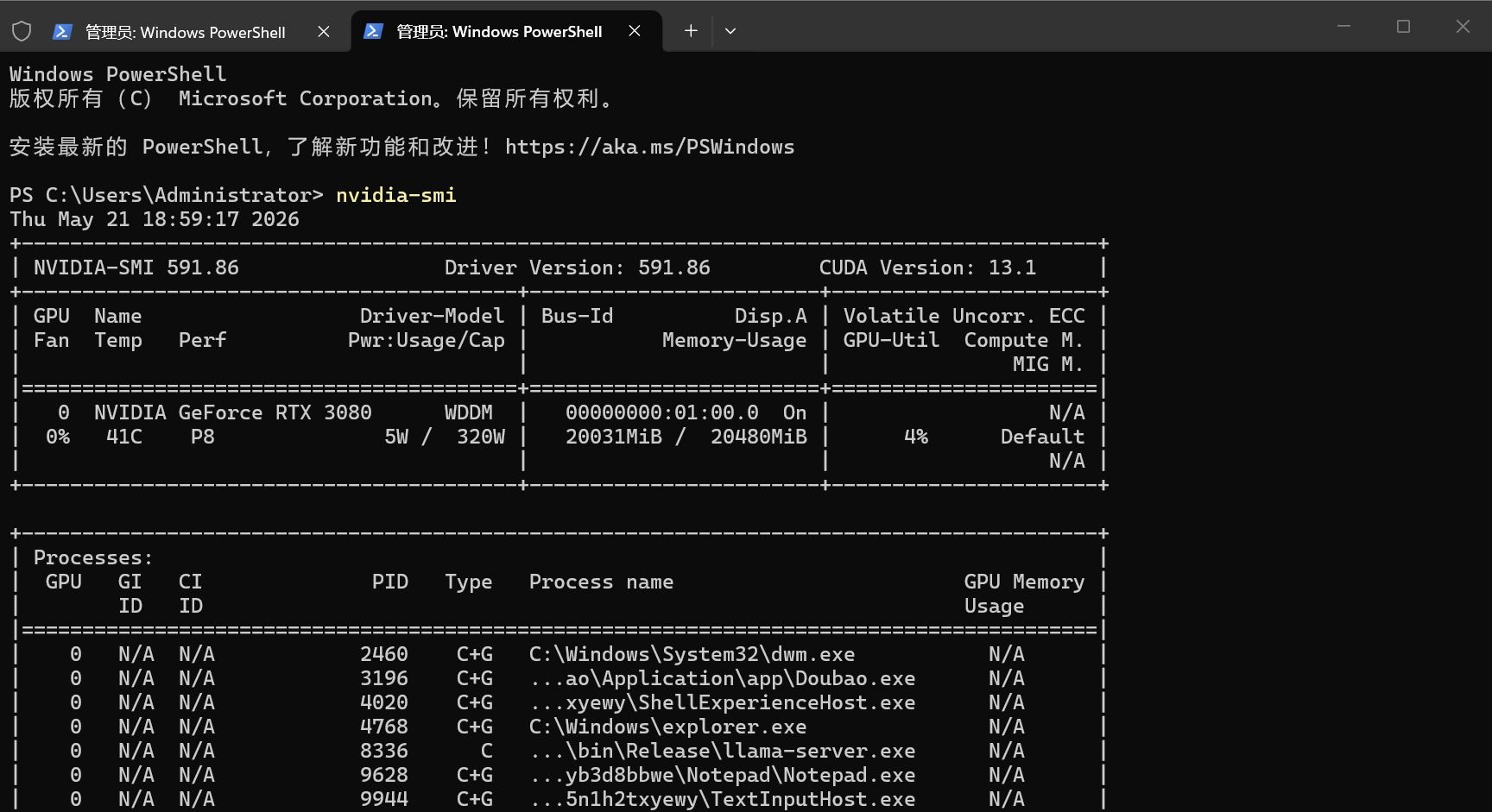
启用集成显卡很有帮助,可以设置168960KV
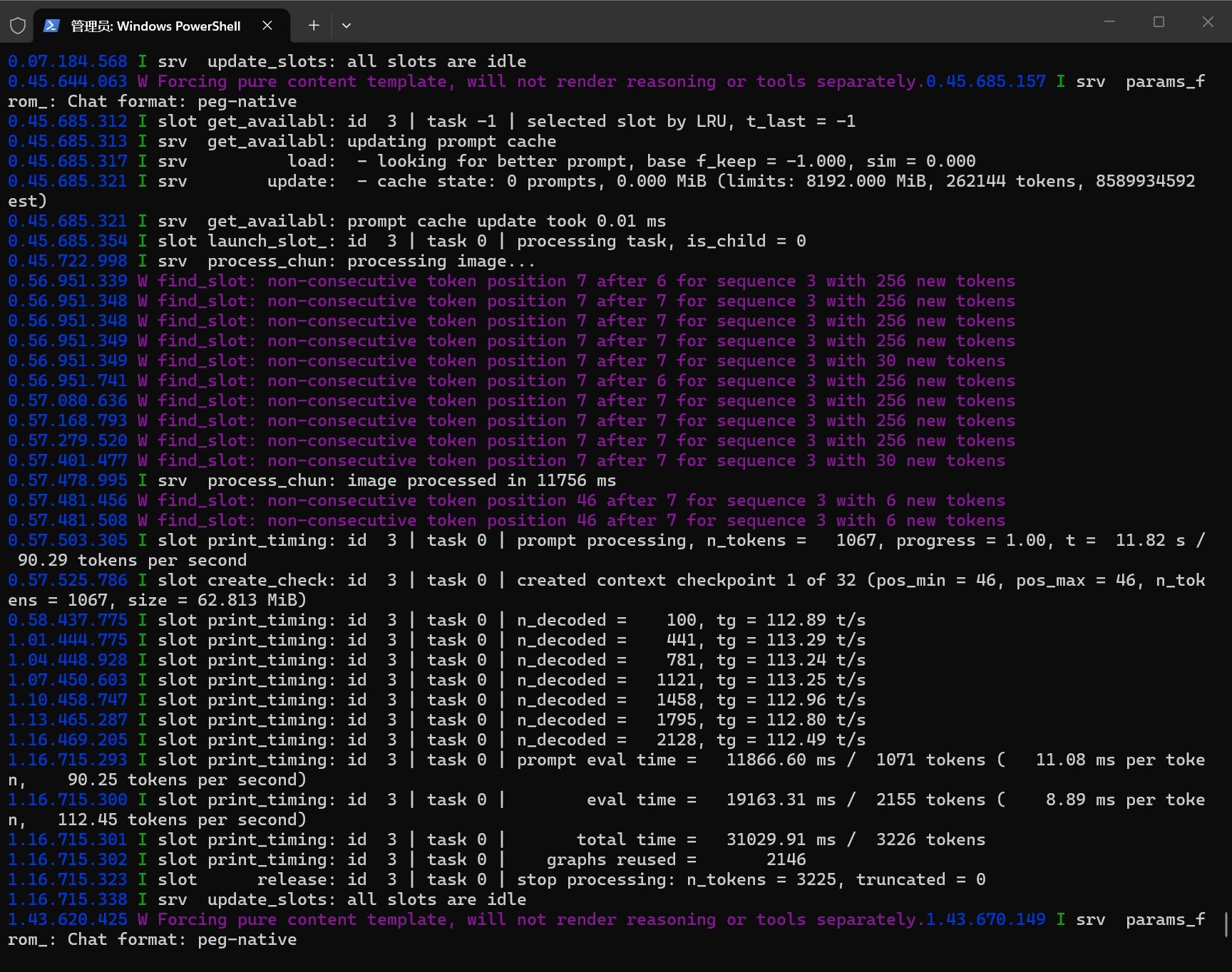
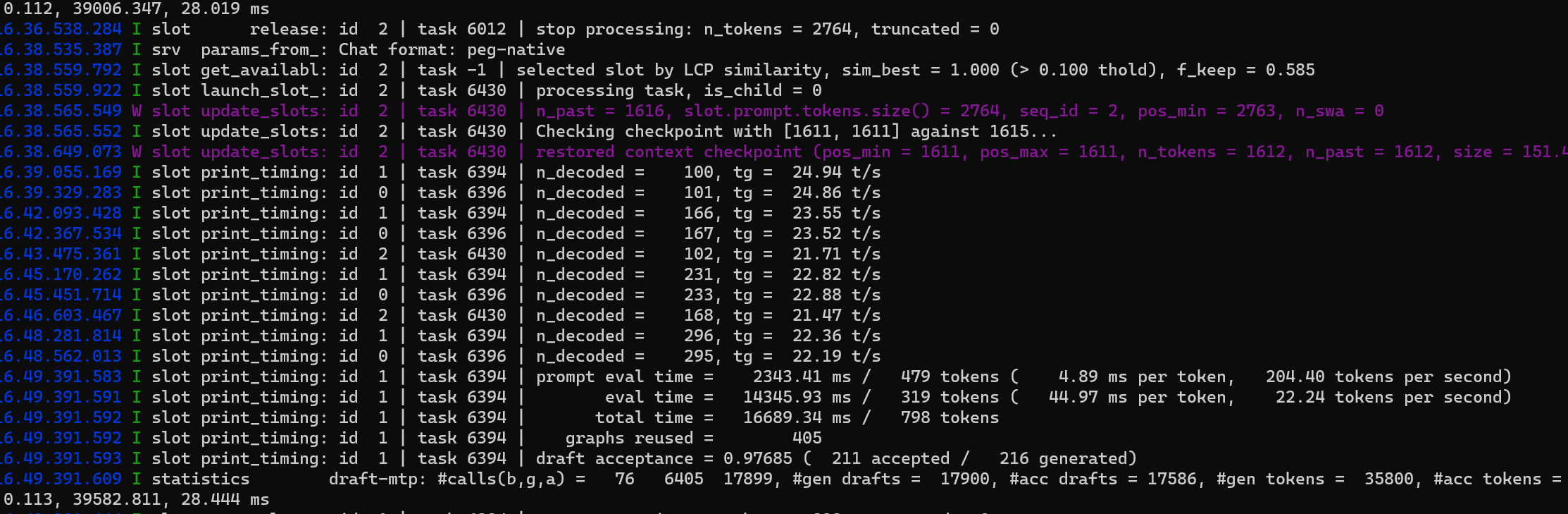
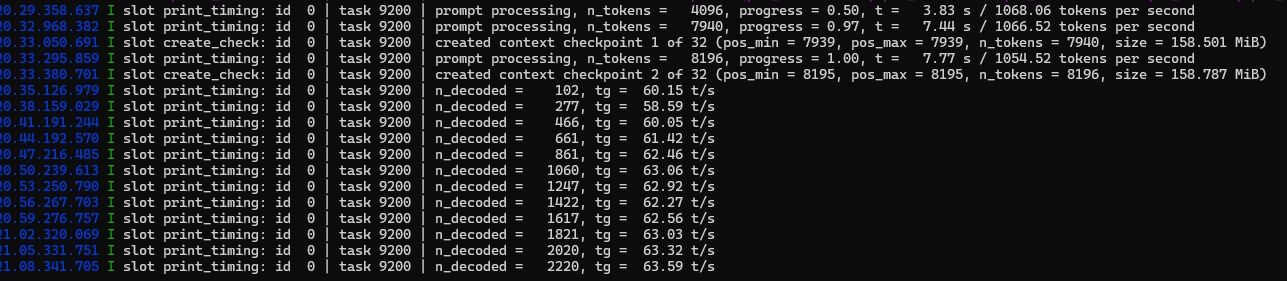
初始60+T/S PREFILL1200 T/S,HERMES设置95%上下文才开始压缩,到压缩上下文之前还能有35T/S,PREFILL400T/S
实际工作体验中,实际上KV量化使用Q80和Q40精度损失几乎不可感知,所以就锁定Q40了
MTP命中基本都可以保持在0.85以上,偶尔会有一两次0.5左右的,实际收益非常高
本地爽玩大模型了
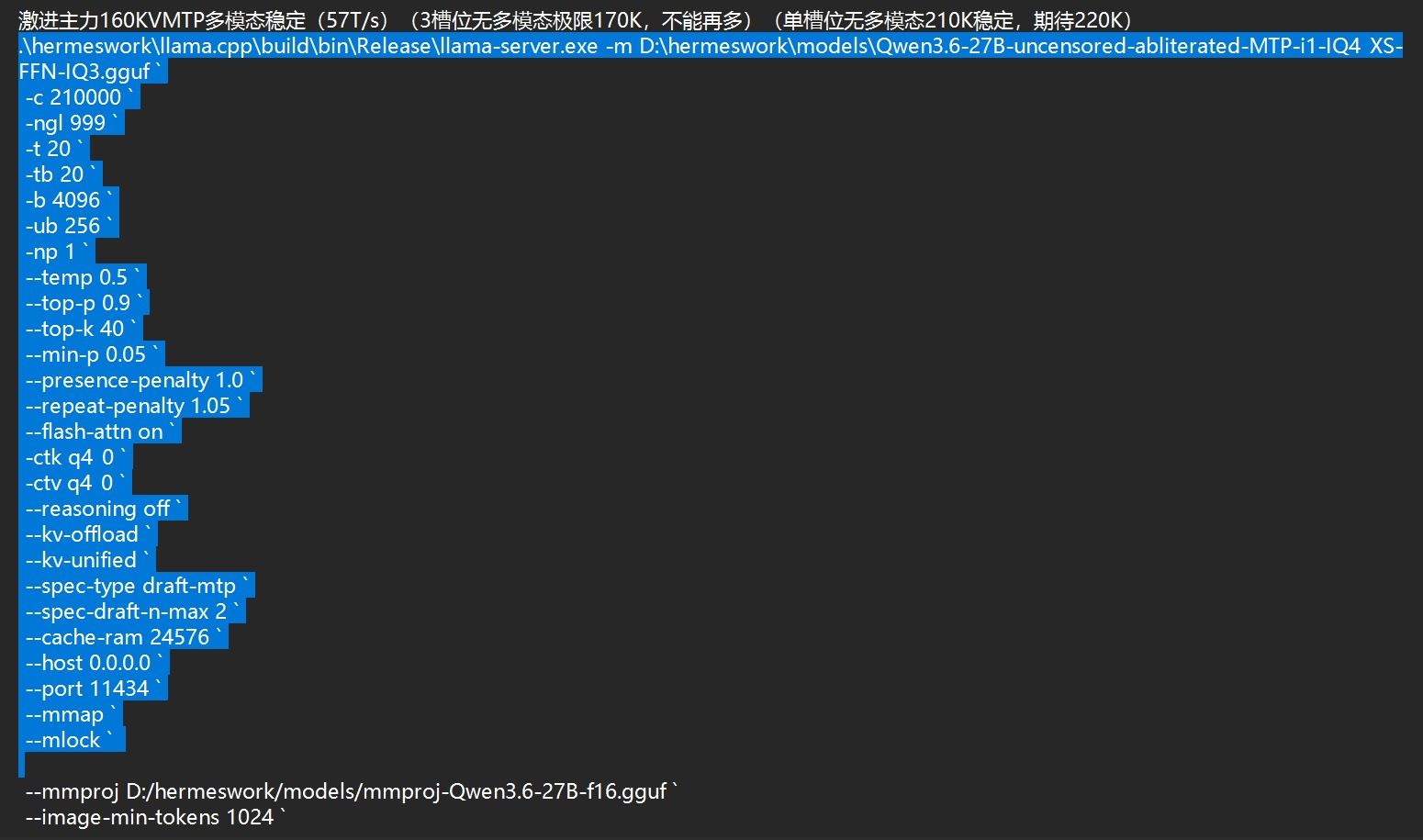
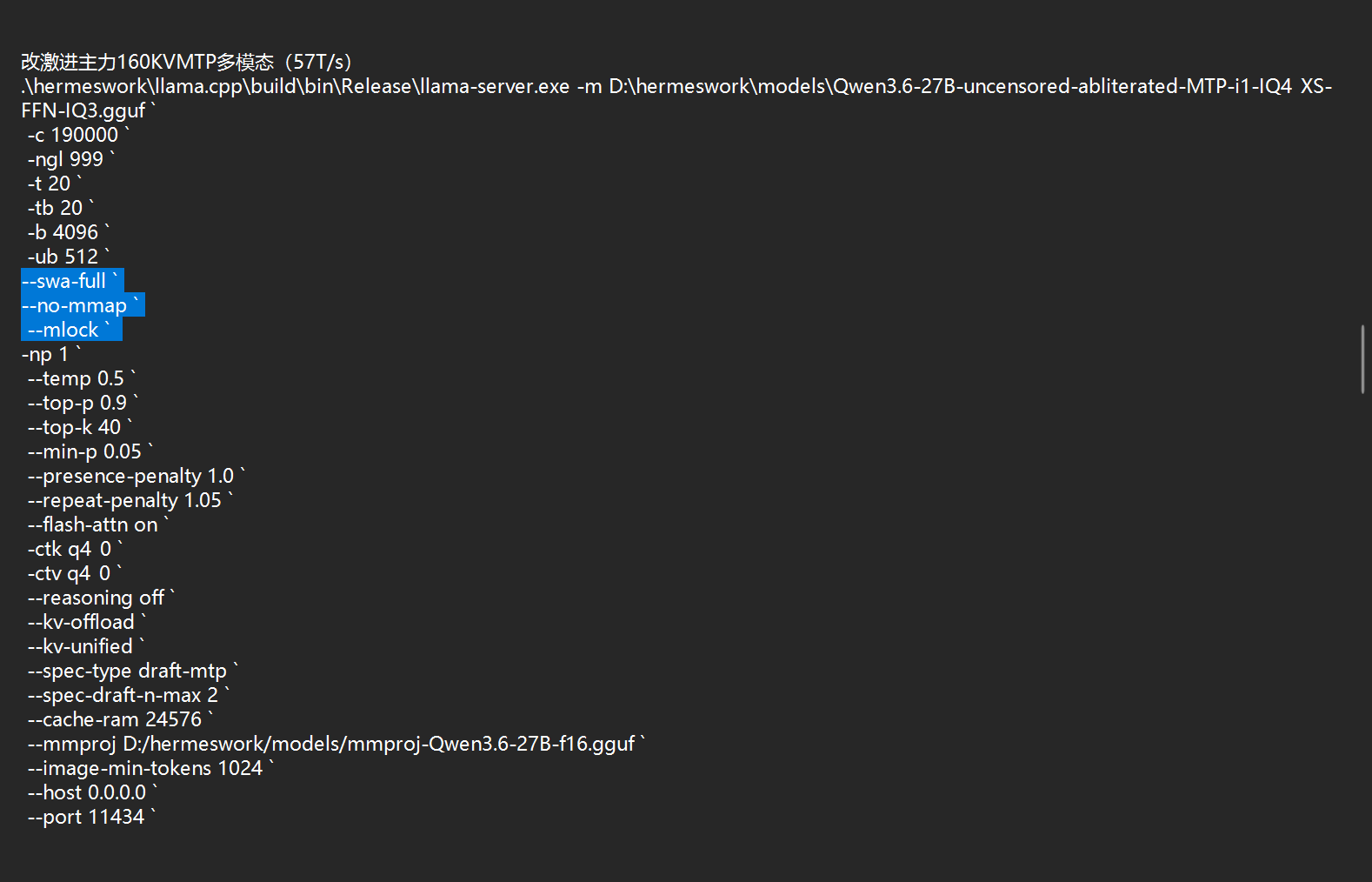
.\hermeswork\llama.cpp\build\bin\Release\llama-server.exe -m D:\hermeswork\models\Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved.i1-IQ4_XS.gguf `
-c 168960 `
-ngl 99 `
-t 24 `
-tb 24 `
-b 2048 `
-ub 256 `
-np 1 `
--temp 0.15 `
--top-p 0.9 `
--top-k 40 `
--min-p 0.05 `
--presence-penalty 1.0 `
--repeat-penalty 1.05 `
--flash-attn on `
-ctk q4_0 `
-ctv q4_0 `
--reasoning off `
--kv-offload `
--spec-type draft-mtp `
--spec-draft-n-max 2 `
--checkpoint-every-n-tokens 16384 `
--ctx-checkpoints 64 `
--cache-reuse 4096 `
--no-context-shift `
--cache-ram 24576 `
--host 0.0.0.0 `
--port 11434 `
--mmap `
--mlock `
删除了35B的配置,因为35B只有在很短的任务才能运行,任务一长就乱跑或者死循环,虽然飞快,但是感觉用不上
真是一张神卡啊