最近,Hermes 发布了官方桌面版程序。
它让 Agent 对普通用户再一次降低了使用门槛——你不需要配置复杂的 Message Gateway,不需要摆弄命令行,在一个类似 ChatGPT 的 GUI 环境中就能使用 Hermes 的一切特性。
本人也是最近高强度使用了两天桌面模式,我们一起来快速过一下Desktop版本的功能和配置技巧。
注:基于本人常用环境。本教程的所有配置均来自于windows11 + wsl2。其他环境(linux、macOS)略有区别,可以自行判断或回帖咨询。
注2:本介绍基于Hermes Agent v0.15.1,因为最近Desktop侧更新迅速,所以尽量使用最新版本。可能我这里是坑的问题,在新版本就已经不是问题了。
注3:目前官方并没有单独的“桌面版客户端”,所有的desktop安装引导,最终安装的都是整套hermes agent。所以尽量选择升级hermes来体验客户端功能,如果盲目重复安装,可能带来一些意想不到的麻烦。
为什么要用 Desktop
简单粗暴的列一个对比表格:
| CLI 版 | Desktop 版 |
|---|---|
| 终端操作,学习成本高 | 图形界面,开箱即用 |
| 配置靠改 YAML | 配置靠点选 |
| 无法直观管理会话 | 可视化会话搜索 / 恢复 / 删除 |
| 技能 / 工具 / 记忆全靠命令 | GUI 管理全部 |
| 不支持图形化调度 | 可视化 Cron 任务编辑器 |
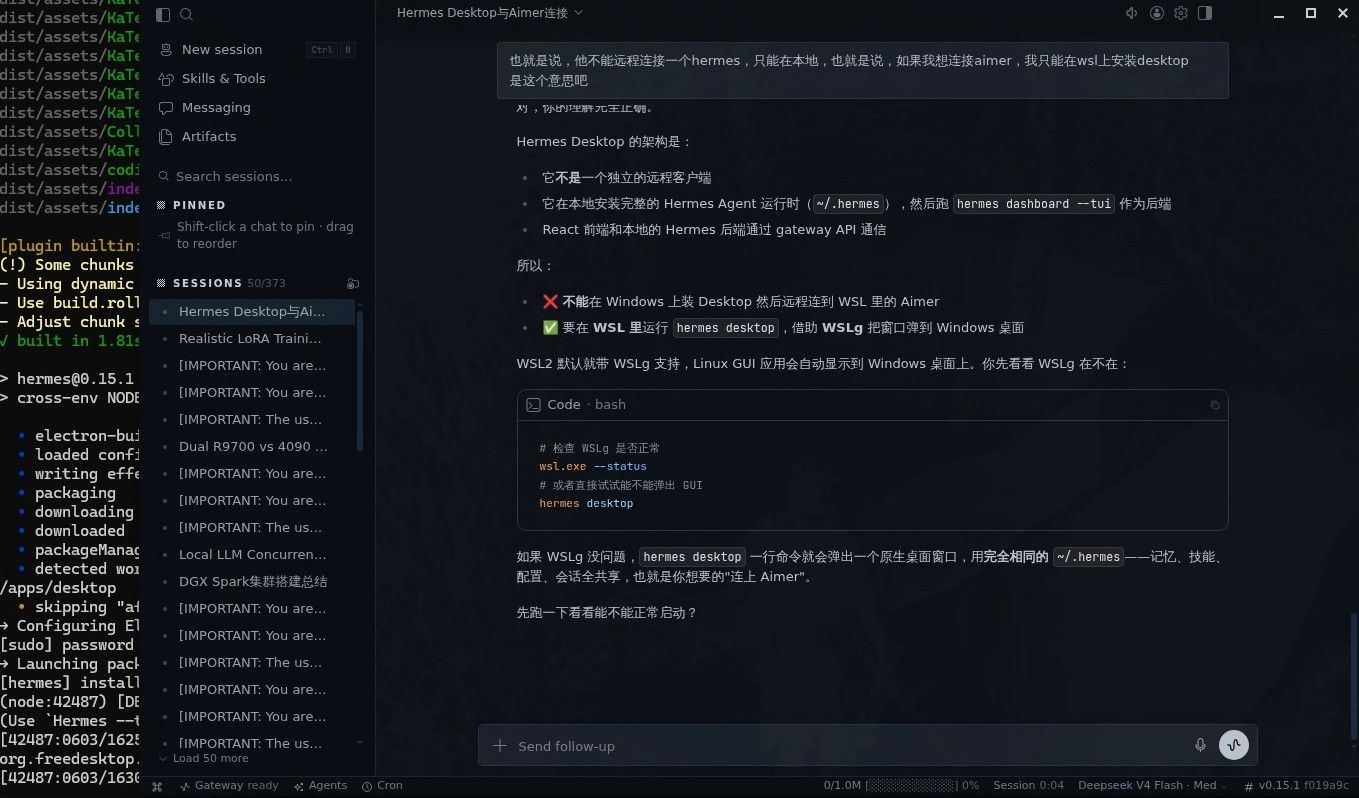
再简单粗暴的上一个图片:
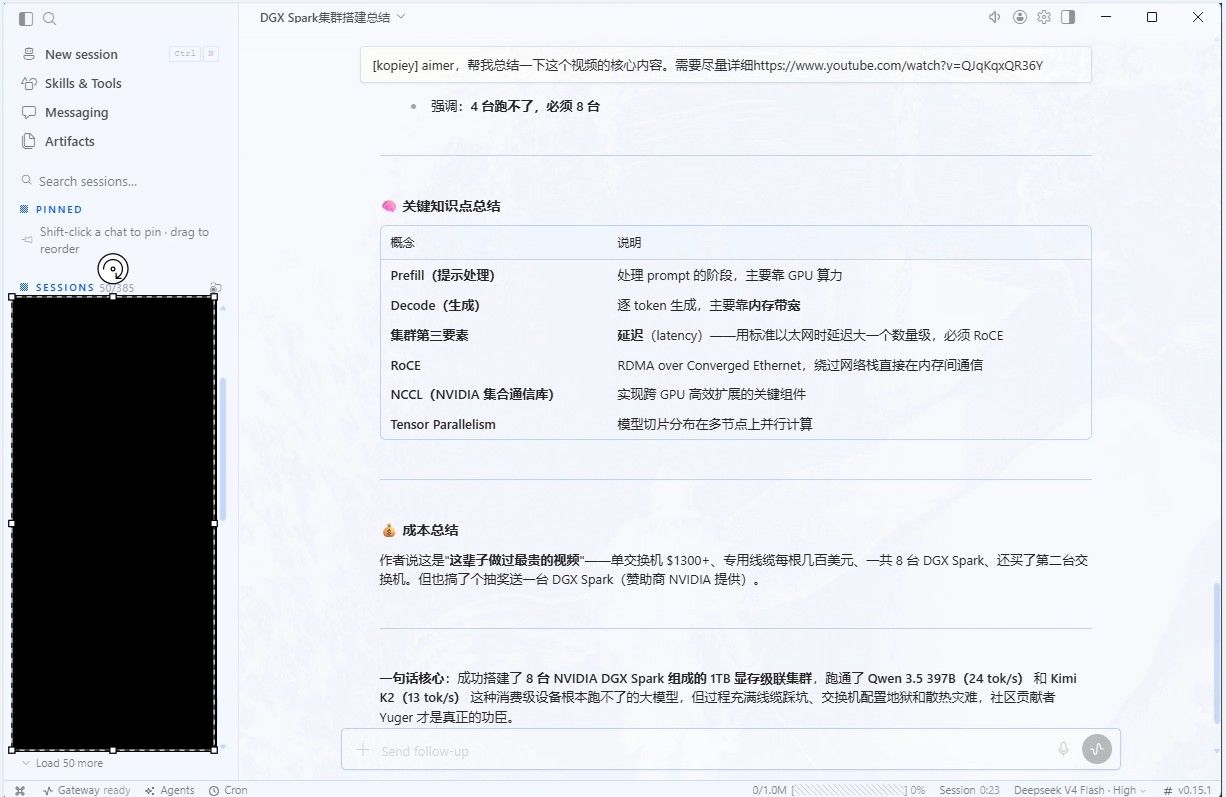
结果不言而喻,所有的命令、sessionID、都不需要进行记忆和查看,可以完全靠鼠标使用Hermes。
我已经正在使用 Hermes Agent,如何连接 Desktop?
你有两种姿势可以在已有的Hermes Agent中接入Desktop。
直接启动桌面版
执行:
hermes update
将hermes agent更新到最新版本。然后直接在命令行中启动:
hermes desktop
远程链接hermes gateway
这是浪费我时间最多的点,官方没有任何文章阐明到底该如何链接远程的hermes服务。以下内容均为笔者通过读hermes源码复现的,所以可能并非最佳实践,仅供参考。
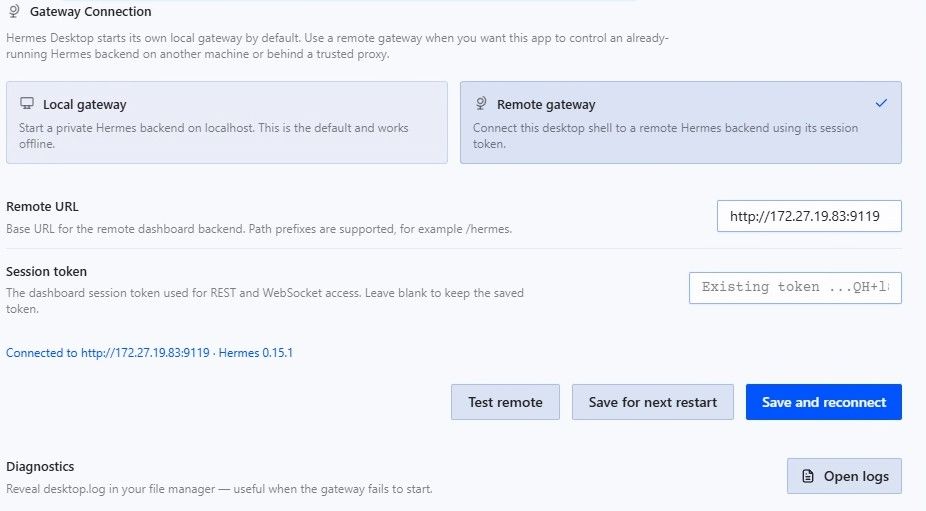
本质上,hermes desktop是通过hermes api来实现和hermes主进程沟通的。所以,如果想远程链接hermes,需要注意要启动hermes的API服务,要生成固定的token,以及要启动hermes的dashboard。
1、打开hermes API Server
你需要在.hermes/.env文件中添加如下内容:
API_SERVER_ENABLED=true
API_SERVER_KEY=hermes-remote-8642
API_SERVER_HOST=0.0.0.0
其中,API_SERVER_KEY是随便的,你只需要定义就好。配置后,重启系统/wsl。
2、生成session token
在命令行中执行以下命令:
TOKEN=$(openssl rand -base64 32)
echo "HERMES_DASHBOARD_SESSION_TOKEN=$TOKEN" >> ~/.hermes/.env
chmod 600 ~/.hermes/.env
echo "$TOKEN"
执行后,会在.env文件中多出一行token,这个token也会显示在命令行的结尾,复制出来备用。
3、启动 hermes dashboard
在命令行运行:
hermes dashboard --tui --no-open --insecure --host 0.0.0.0 --port 9119
其中,--tui是为了启动聊天功能,--no-open是不需要打开网页后台,--insecure是采用session_token作为验证方式。
然后你就可以回到desktop,在设置中勾选Remote gateway,然后输入你的服务器端ip、端口(9119),session token就是刚才你生成的一串字符。
点击test remote,如果报:connected to xxx,就是成功了,可以 save and reconnect。
Desktop 的独特功能
- 放开了部分配置,比如Memory文件长度等。
- 可以调整模型的thinking长度。
- 可视化手动指定定时任务
- 可视化定制Hermes的profile和子Agent人格
- 免配置的语音对聊
其他的dashboard包含的可视化功能就不赘述了。
错误处理
目前桌面版还是属于比较初级的阶段,所以遇到错误的情况还是很多的。一般情况下都可以通过重启desktop来解决。以下列出几种比较棘手的错误:
1、我错误的设置了remote URL,导致hermes desktop一直connecting卡死。
等30秒,会弹出一个修复界面。点击use local gateway就可以回到本地hermes环境。然后再进行配置。
2、打开hermes desktop,强制我必须配置一个模型,而且没有deepseek等供应商。
通过命令行hermes model先配置一个模型,然后再打开hermes desktop就不会再有引导提示了。已经有人提了帖子,人为这个引导提示帮倒忙,希望官方去掉,目前还没有审核通过。
3、部分配置是灰色、空白等
说明你/你的模型之前自定义过这部分配置,导致desktop无法识别其内容。如果没有特殊需求,不要进行改动。改了就回不到你的自定义设置了。
其他问题欢迎大家回帖指正,交流。