
24GB显存的话,qwen3.6-27B Q4,再加上 256k q8量化的kvcache放不下。这是我能看到的最明显的问题。
然后就是linux的GUI远程桌面无论哪家效果都不好。最流行的UU远程和parsec甚至就不支持Linux作为server(受控端)
-
一个7900 xtx 24G 装机单,期望:稳定、高性价比、可拓展,请大神点评 -
OpenAI的内部模型,在benchmark的过程中,为了获取高分,最终黑掉了huggingface来窃取对应试题的答案如题。
huggingface的对应文章: https://huggingface.co/blog/security-incident-july-2026然后抱脸试图通过GPT5.6修复漏洞,结果因为GPT5.6的系统审查严格,很多有价值的上下文无法上传(比如攻击的方法、日志、痕迹等。估计是被GPT的防火墙识别成了攻击,而不是上下文信息)而无法修复,最终无奈启用自建GLM5.2解决了问题。
即便是OpenAI这种头部巨头,也一样搞不好模型走捷径的问题。
Agent指令遵循任重而道远。 -
AI 产品溢出产能回收计划 & 实战任务发布 - 任务 二 -
请教下DEEPSEEK资深用户:高峰期卡顿问题。目前没发现这个问题,卡顿你指的是prefill和decode性能下降?可以看你的Agent的底层调用日志来计算一下prefill和decode性能。
deepseek的服务状态可以以此页面作为参考:https://status.deepseek.com/
-
大伙儿对最近Reddit LocalLLM社区中很火的Ternary Bonsai 27B怎么看?看了下,作者自述的性能如下:
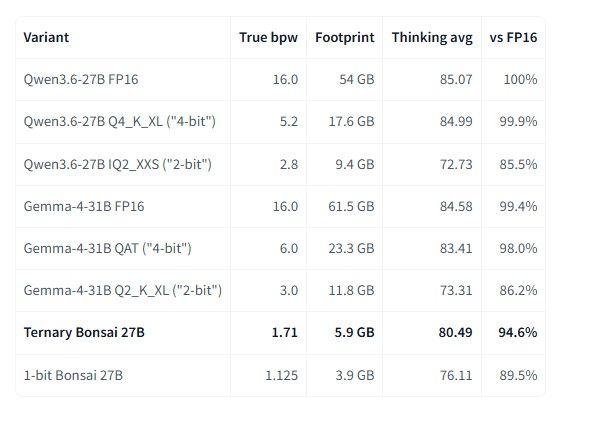
但他这个性能描述有很大的不合理之处。至少是benchmark的选型不合理。
他自述Gemma-4-31B FP16的能力是Qwen3.6-27B FP16的 99.4%。但任何benchmark网站都不支持此结论。
比如:https://artificialanalysis.ai/models/comparisons/qwen3-6-27b-vs-gemma-4-31b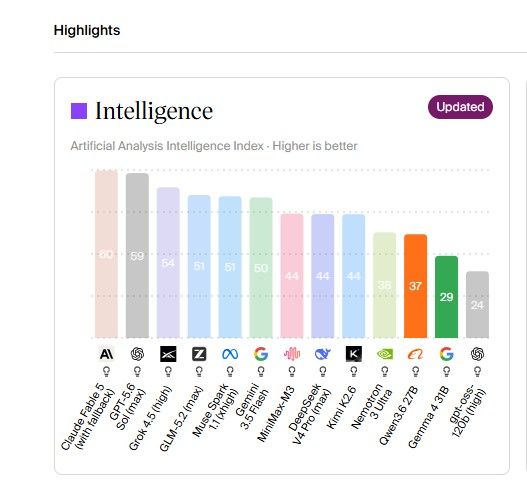
基于此,作者对于其27B模型是Qwen3.6-27B FP16的94.6%的结论至少是值得探讨的。
-
程序员的天塌了!其实八成的程序员都是要失业!自身的薪资和能力已经和市场倒挂了!本质上还是软件工程的生产资料本来就不在于Coding。
近十年的高工资都是因为编程人才储量和移动互联网爆发导致的资源错配。目前的环境又是多维度全面看空Coding:AI编程导致开发成本下降,AI爆发导致硬件成本上升,软件迭代速度下降。经济全面萎缩,导致错配的人力资源价值无法持续兑现。
-
求助帖,文字(文案、剧本)转音频,声音 AI 化太明显!TTS的话,你需要把你的文案口语化润色,并针对你的TTS方案做结构化改造。比如你的TTS是否支持语气和气口,等等。
这个润色工作LLM可以做到90%,但如果想到100%,还是要手工介入。
还有一点,就是你的显卡偏弱,最强的本地TTS跑不了,这也是差距之一。
TTS能力可以参照这个榜单:https://artificialanalysis.ai/text-to-speech/leaderboard/selected-voice?open-weights=true
-
淺聊PrismaQuant, INT4 Autoround, W4A4 NVFP4量化下的Tool Call表現很有意义的评测,目前localLLM就是缺乏整个harness的流程优化。换句话说就是还没有头部团队为localLLM整个生态做兜底。
搞模型的自己闷头搓模型,搓出来就跑Benchmark,万事大吉。
搞Agent工具的都忙着和线上LLM做深度绑定,或者自己搞LLM provider。
搞LLM运行框架的还在忙着提升吞吐量。localLLM实际的落地体验反而被人忽略了。
-
Wan2.2 I2V(图生视频)技巧Tips最近刚接触多媒体生成这块,所以知识体系还不足以能够分享整个工作流,所以只能是发一些我的观察和经验,欢迎交流指教。
1、生成视频尽量使用模型原生训练的帧率和总帧数。对于wan2.2的I2V而言,就是81帧,fps16。总帧数、fps加大会导致一些问题,最明显的就是质量劣化,或者动作漂移。本质上就是模型其实处理不了那么多的总帧数。
2、官方推荐的参数基本上就是最理想的参数,比如在使用加速LoRA:LightX2V时,总步数是4,CFG是1,sigma接近0.9,CRF低于18
3、如果需要最终输出的视频参数改动(分辨率、帧率、总长度)尽量使用对视频后期处理思路来改动,比如利用 RIFE来插帧,从而提升帧率。利用Wan2.2的FLF2V(首尾帧生成) 来实现多段5秒的视频无缝组合,从而延长时间等。
大概就酱。
-
在线调用的最大无奈这个是典型的Agent工具和API格式不适配的情况,和什么场景无关。需要确认的是你的Agent工具是什么,其格式是否符合deepseek官网提供的两种兼容API其一。
本地LLM能正常运行,普遍是因为不管是llama.cpp还是vllm,他们的API都是考虑最大化宽松兼容的,走的是能跑就跑的设计思路,和线上API的效率优先逻辑不同。
-
AI推論主機的內存合理配置 ? -
新手村误入沃玛寺庙。“如何 Hermes 快速了解和接手 claude code 现在做的项目”
直接告诉Hermes你的项目的文件夹位置就好,Claude Code你在使用的所有痕迹都会存在你选定目录的根目录的.claude文件夹中。“把它安装在 VPS 上,但数据来回传输会经常不通”
这个可以让Hermes或者Claude Code来排查,代价就是你要把你的VPS的用户名和密码提供给LLM,不过从你是新手的角度来考虑,这也没什么问题。“目前硬件资源”
如果只搞用Agent进行Coding或者工作流,本质上对于硬件没什么要求。所以不急。 -
各位大神你們用的系統是ubuntu server還是desktop版呢?首先,先更正一个点,就是对于Linux而言,GUI和系统桌面不是绑定死的。换句话说,你可以理解为Linux的图形界面是零散的。你可以在没有系统桌面的前提下,全屏运行一个游戏。
然后就是要看你的ubuntu的设备是一个什么定位。
如果只是一个粗暴的模型API提供者,那系统桌面就是纯累赘。
如果你的设备是一个AI服务的Server,系统桌面就是可选项,毕竟有远程可视化的方案。如果是一个AI服务的All in One主机,你需要在本机操作多媒体、文件内容,甚至需要进行编程、文字编辑、浏览网页等复杂的交互操作。那么桌面图形界面就有其意义。最起码多一个鼠标操作的维度,你就能节省大量的对于文件、多窗口等的命令行输入。
举个特别简单的例子,你在桌面,你只需要双击程序A,再双击程序B,你就完成了程序A、B的后台运行,且可以随意切换。
但是命令行你付出的成本就大很多。 -
【7900xtx】装了个claude code,一天烧3000万token,莫非是我本地大模型太蠢了?坑在哪里?速度上主要是体量的区别。Hermes的skill和ToolList,再加上memery和既有聊天记录的索引,太重了。
至于说烧token的问题,主要得以一个可以量化的任务为前提来比较。
举个例子,Claude Code因为冷启动提示词少,所以prefill速度相对较高,也能帮你烧更多的token。
相反的,假如你的Claude Code配置有问题,导致部分能力缺失,LLM总是循环请求不存在,或者无法正常运行的Tool,也会导致大量的浪费。所以废token要定量对比分析才行。
-
新手双卡r9700 ai pro交作业 -
618刚攒的机,用来做linux工作站,看看能折腾出啥来,水一贴@David-Dec “爬取上市公司年报”是一个非常具体的需求,而且对内容有严格的精准度要求。这种情况下一般不是用检索工具解决的。一般是靠直接爬取或者通过某些第三方服务直接获取的pdf文件。
所以需要你通过Coding Agent或者Hermes直接写脚本更实际。本质逻辑是去xxx这个网址获取yyy.pdf这个文件。
而不是“帮我去获取google的半年财报“这种非常模棱两可的提示词。
然后是信息检索,目前我使用的是https://www.tavily.com/ 的免费额度,对于我的检索量来讲,堪用,然后我设计了API额度耗光后,降级到duckduckgo的搜索API,也可以选择锤哥推荐的brave检索API。
成熟的搜索API不光能给你网页快照,更多的是给你结构化数据,相当于是他们已经为你爬取了一部分信息。这样的精准度比Hermes自己去爬要准一些。而且能绕过一些反爬验证。
-
《天才程序员再次陨落》——2026/07/02 deepseek API崩溃纪实16:50:笔者发现Hermes Agent和OpenCode均出现了反应变慢的情况。以为是服务器的网络问题,遂开始远程排查。
17:01:OpenCode go订阅的deepseek-v4-flash模型开始报超时和超限。
17:10:https://status.deepseek.com/ 开始报API和网页性能下降。
17:12:API请求风暴开始席卷其他平价模型,MiMO v2.5官网、MiMO v2.5 go订阅,开始崩溃,GLM5.2的decode性能大幅下降。
17:15:go订阅的非Qwen模型均出现了性能下降的情况,认知度最高的模型API几乎均不可用。
18:02:deepseek官网汇报API性能问题解决,服务开始恢复。
18:05:OpenCode go订阅恢复正常。结论:
1、模型降级到其他LLM供应商并不是一个稳妥的容灾方案。大家的AI工具普遍都有容灾和降级逻辑。所以,当一个巨量API服务崩溃时,不要奢望其他API能够接住这“泼天的富贵”,我看到更多的是连锁崩溃。2、OpenCode的GO订阅一直号称自己的deepseek-v4是境外自部署。但通过此次事故推断,此结论存疑。
3、通过这次请求海啸能够观测到,LLM供应商从某种程度上讲,已经成为了类似“水、电、网”的存在。当服务出现波动时,抢夺挤兑的情况甚至更严重。
-
我最近对AI有点顿悟了,发现架构能力和判断能力是最重要的!本质上还是统计学结果和实际价值之间的“夹角”导致的。
对于机器学习模型而言,多=正确,在99%的场景下,这个结论都是对的。但其实无论是商业价值还是科研价值,占最大比重的都是剩下那1%。
再加上算法层面,目前的LLM远还没到理想的统计学上限。
而工具层面,上下文信息还不能无痛完全采集。所以就导致其功效的二八原则也非常明显。谁更有行业的领先视野,谁更能提供最有价值的上下文,谁更能高效的纠偏提点,谁就越能发挥LLM的潜力。
当然,随着算法和工具的逐渐完善,统计学和现实世界的“夹角”也会进一步缩小。就像是智驾一样,从辅助到有人到集控到最后的完全无人。总是有一个过程的。
所以统计学模型其实是非常令人绝望的一种形态。他会随着算法、数据、工具的完善,逐渐吞噬掉一个又一个的行业,一个又一个的阶层,让可能本来在前20%就能掌握80%的资源的生态,演进到前千分之一,掌握99.9%的资源的高度集中态。
-
關於GB10跟N1X@怪物 稠密模型是相较于MoE模型来讲的。MoE是一个新技术,大知识总量,但是每次运行的时候只调用一部分参数,从而加快推理速度。
比如楼主说的Qwen3.6-35B-A3B,就是他的模型总知识量是35B参数,但每次运行,只会针对性使用3B参数来参与。
但是对于个人部署来讲,限制瓶颈普遍不在推理性能,而在内存总量,所以巨大的MoE模型对于个人部署价值非常有限。而小MoE模型,因为执行时参与运算的参数又过少,难免影响其注意力和推理能力。
-
關於GB10跟N1X@怪物 楼主的错误可以理解,很多人人为模型的“体量”=“能力”。但实际上并不是如此。
体量只决定静态知识储备和统计学趋势(类似于一个人没手机,无工具情况下,自己的脑子里的知识总量和思维判断)。
能力就更为复杂一些。举个简单粗暴的例子,一个小学生+google,知识体量也一定赢过大学生自身脑容量,但是实际场景的问题解决,则不见得谁更强。
所以认知模型能力更相对客观的是看benchmark,也就是跑分。
我比较常用参考的跑分网站:https://benchlm.ai/llm-agent-benchmarks我最推荐的Qwen3.6-27B非拒绝模型是https://huggingface.co/HauhauCS/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
仅供参考。